 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Prompting Foundation Models for Medical Image Segmentation
Sep 01, 2024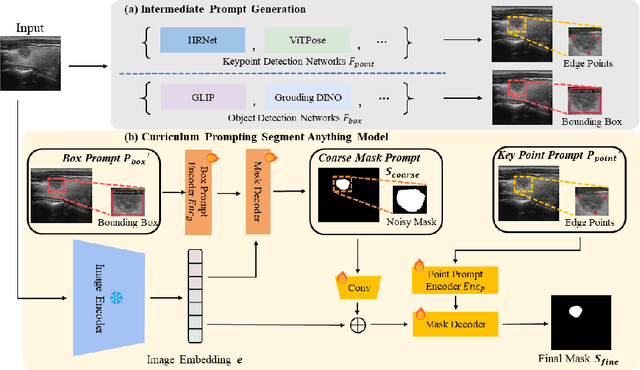
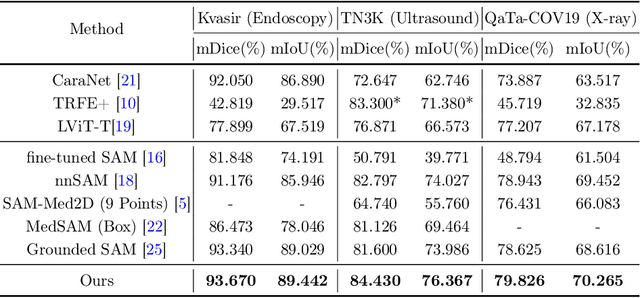

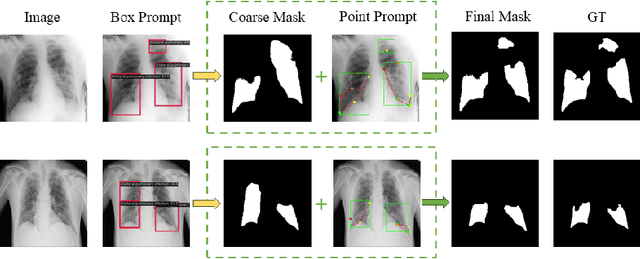
Adapting large pre-trained foundation models, e.g., SAM, for medical image segmentation remains a significant challenge. A crucial step involves the formulation of a series of specialized prompts that incorporate specific clinical instructions. Past works have been heavily reliant on a singular type of prompt for each instance, necessitating manual input of an ideally correct prompt, which is less efficient. To tackle this issue, we propose to utilize prompts of different granularity, which are sourced from original images to provide a broader scope of clinical insights. However, combining prompts of varying types can pose a challenge due to potential conflicts. In response, we have designed a coarse-to-fine mechanism, referred to as curriculum prompting, that progressively integrates prompts of different types. Through extensive experiments on three public medical datasets across various modalities, we demonstrate the effectiveness of our proposed approach, which not only automates the prompt generation process but also yields superior performance compared to other SAM-based medical image segmentation methods. Code is available at: https://github.com/AnnaZzz-zxq/Curriculum-Prompting.
Generalizable Facial Expression Recognition
Aug 20, 2024SOTA facial expression recognition (FER) methods fail on test sets that have domain gaps with the train set. Recent domain adaptation FER methods need to acquire labeled or unlabeled samples of target domains to fine-tune the FER model, which might be infeasible in real-world deployment. In this paper, we aim to improve the zero-shot generalization ability of FER methods on different unseen test sets using only one train set. Inspired by how humans first detect faces and then select expression features, we propose a novel FER pipeline to extract expression-related features from any given face images. Our method is based on the generalizable face features extracted by large models like CLIP. However, it is non-trivial to adapt the general features of CLIP for specific tasks like FER. To preserve the generalization ability of CLIP and the high precision of the FER model, we design a novel approach that learns sigmoid masks based on the fixed CLIP face features to extract expression features. To further improve the generalization ability on unseen test sets, we separate the channels of the learned masked features according to the expression classes to directly generate logits and avoid using the FC layer to reduce overfitting. We also introduce a channel-diverse loss to make the learned masks separated. Extensive experiments on five different FER datasets verify that our method outperforms SOTA FER methods by large margins. Code is available in https://github.com/zyh-uaiaaaa/Generalizable-FER.