 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDedicated Inference Engine and Binary-Weight Neural Networks for Lightweight Instance Segmentation
Jan 03, 2025
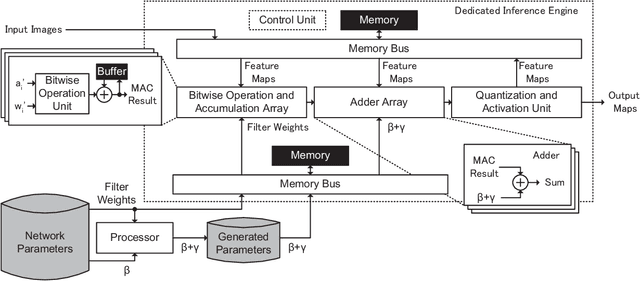
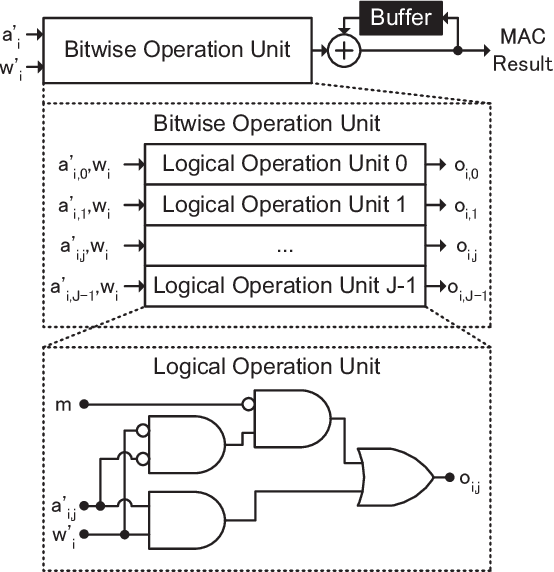
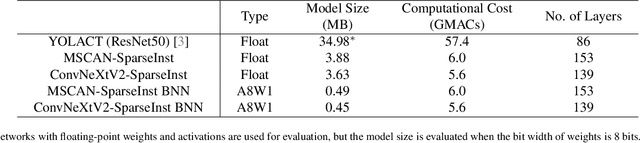
Reducing computational costs is an important issue for development of embedded systems. Binary-weight Neural Networks (BNNs), in which weights are binarized and activations are quantized, are employed to reduce computational costs of various kinds of applications. In this paper, a design methodology of hardware architecture for inference engines is proposed to handle modern BNNs with two operation modes. Multiply-Accumulate (MAC) operations can be simplified by replacing multiply operations with bitwise operations. The proposed method can effectively reduce the gate count of inference engines by removing a part of computational costs from the hardware system. The architecture of MAC operations can calculate the inference results of BNNs efficiently with only 52% of hardware costs compared with the related works. To show that the inference engine can handle practical applications, two lightweight networks which combine the backbones of SegNeXt and the decoder of SparseInst for instance segmentation are also proposed. The output results of the lightweight networks are computed using only bitwise operations and add operations. The proposed inference engine has lower hardware costs than related works. The experimental results show that the proposed inference engine can handle the proposed instance-segmentation networks and achieves higher accuracy than YOLACT on the "Person" category although the model size is 77.7$\times$ smaller compared with YOLACT.
UNet--: Memory-Efficient and Feature-Enhanced Network Architecture based on U-Net with Reduced Skip-Connections
Dec 24, 2024U-Net models with encoder, decoder, and skip-connections components have demonstrated effectiveness in a variety of vision tasks. The skip-connections transmit fine-grained information from the encoder to the decoder. It is necessary to maintain the feature maps used by the skip-connections in memory before the decoding stage. Therefore, they are not friendly to devices with limited resource. In this paper, we propose a universal method and architecture to reduce the memory consumption and meanwhile generate enhanced feature maps to improve network performance. To this end, we design a simple but effective Multi-Scale Information Aggregation Module (MSIAM) in the encoder and an Information Enhancement Module (IEM) in the decoder. The MSIAM aggregates multi-scale feature maps into single-scale with less memory. After that, the aggregated feature maps can be expanded and enhanced to multi-scale feature maps by the IEM. By applying the proposed method on NAFNet, a SOTA model in the field of image restoration, we design a memory-efficient and feature-enhanced network architecture, UNet--. The memory demand by the skip-connections in the UNet-- is reduced by 93.3%, while the performance is improved compared to NAFNet. Furthermore, we show that our proposed method can be generalized to multiple visual tasks, with consistent improvements in both memory consumption and network accuracy compared to the existing efficient architectures.
* 17 pages, 7 figures, accepted by ACCV2024
SFace: Sigmoid-Constrained Hypersphere Loss for Robust Face Recognition
May 24, 2022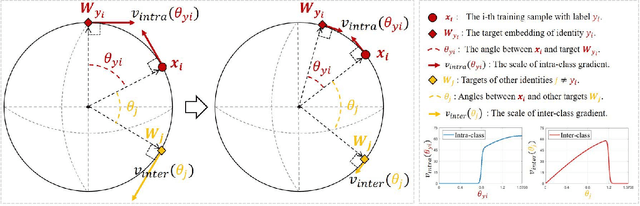
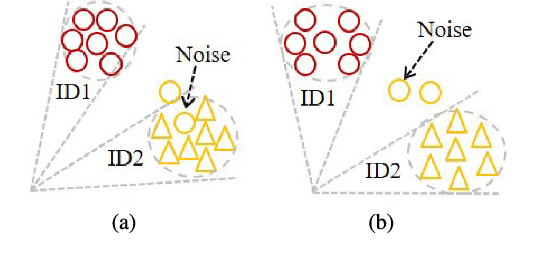
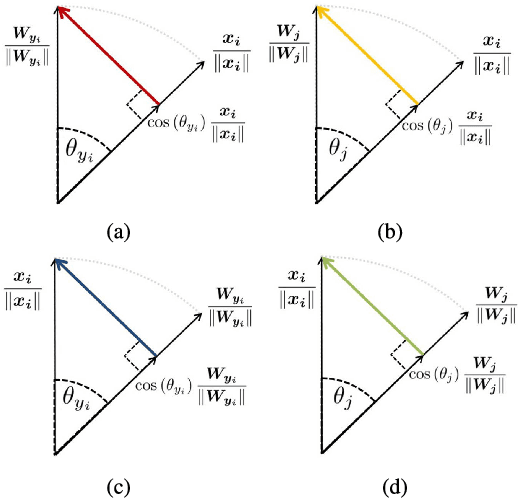
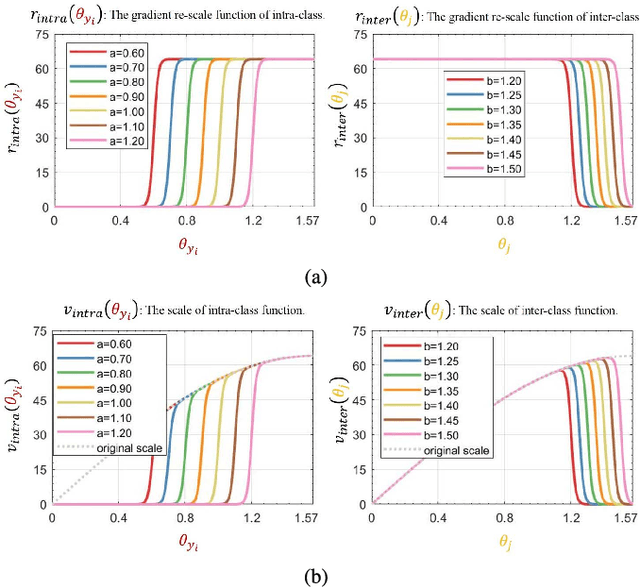
Deep face recognition has achieved great success due to large-scale training databases and rapidly developing loss functions. The existing algorithms devote to realizing an ideal idea: minimizing the intra-class distance and maximizing the inter-class distance. However, they may neglect that there are also low quality training images which should not be optimized in this strict way. Considering the imperfection of training databases, we propose that intra-class and inter-class objectives can be optimized in a moderate way to mitigate overfitting problem, and further propose a novel loss function, named sigmoid-constrained hypersphere loss (SFace). Specifically, SFace imposes intra-class and inter-class constraints on a hypersphere manifold, which are controlled by two sigmoid gradient re-scale functions respectively. The sigmoid curves precisely re-scale the intra-class and inter-class gradients so that training samples can be optimized to some degree. Therefore, SFace can make a better balance between decreasing the intra-class distances for clean examples and preventing overfitting to the label noise, and contributes more robust deep face recognition models. Extensive experiments of models trained on CASIA-WebFace, VGGFace2, and MS-Celeb-1M databases, and evaluated on several face recognition benchmarks, such as LFW, MegaFace and IJB-C databases, have demonstrated the superiority of SFace.
* 12 pages, 9 figures