 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAL: A Large-scale Video Dataset of Multi-grained Spatio-temporally Action Localization
Apr 06, 2022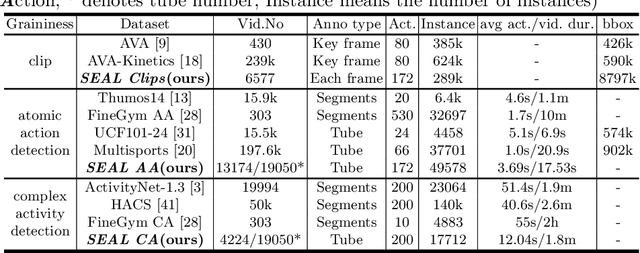
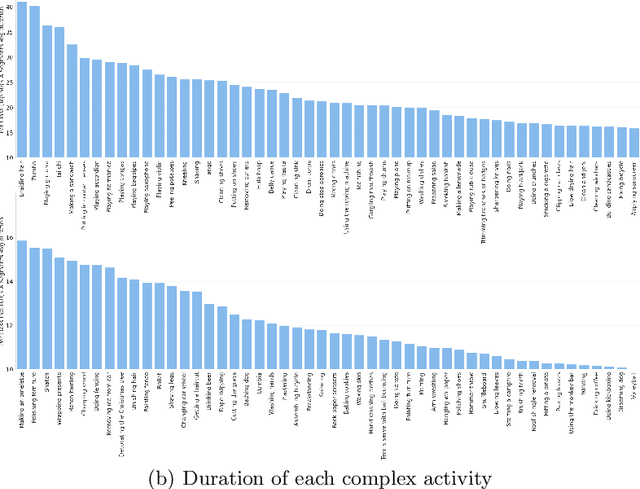
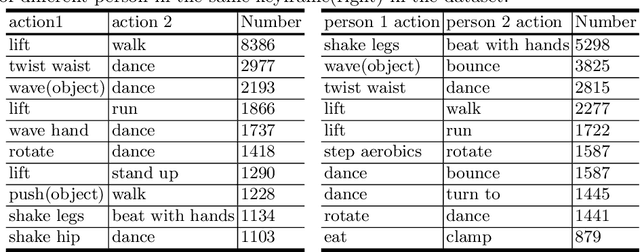
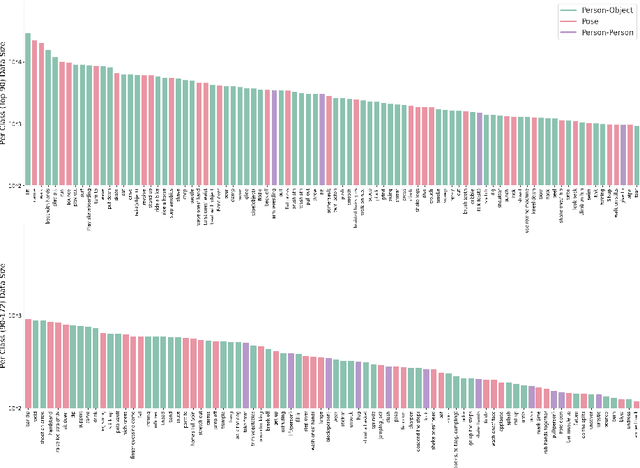
In spite of many dataset efforts for human action recognition, current computer vision algorithms are still limited to coarse-grained spatial and temporal annotations among human daily life. In this paper, we introduce a novel large-scale video dataset dubbed SEAL for multi-grained Spatio-tEmporal Action Localization. SEAL consists of two kinds of annotations, SEAL Tubes and SEAL Clips. We observe that atomic actions can be combined into many complex activities. SEAL Tubes provide both atomic action and complex activity annotations in tubelet level, producing 49.6k atomic actions spanning 172 action categories and 17.7k complex activities spanning 200 activity categories. SEAL Clips localizes atomic actions in space during two-second clips, producing 510.4k action labels with multiple labels per person. Extensive experimental results show that SEAL significantly helps to advance video understanding.
Faster-TAD: Towards Temporal Action Detection with Proposal Generation and Classification in a Unified Network
Apr 06, 2022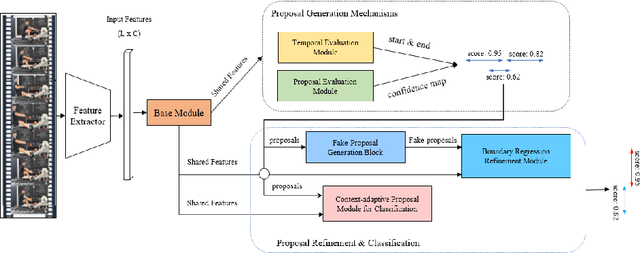
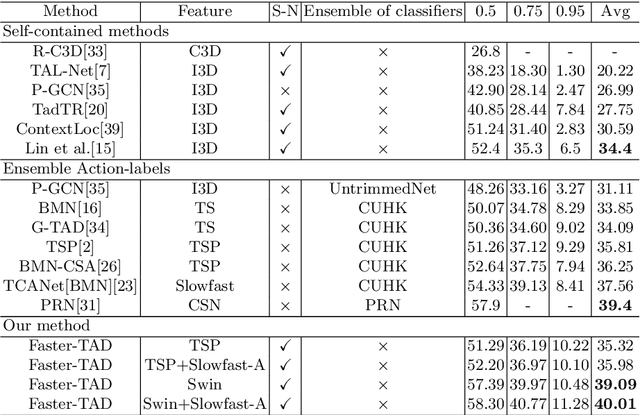
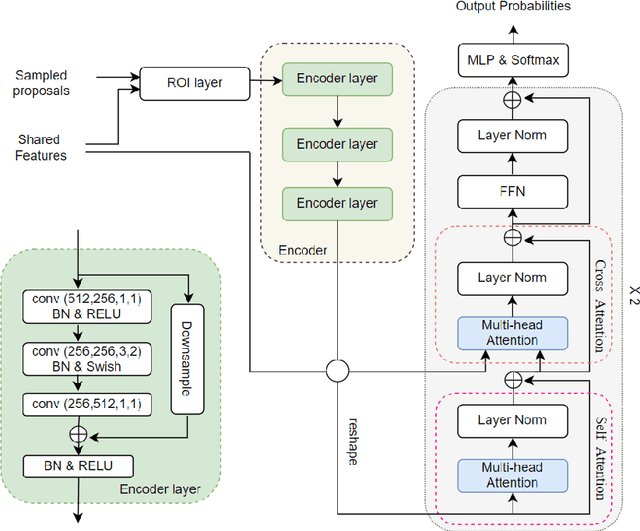
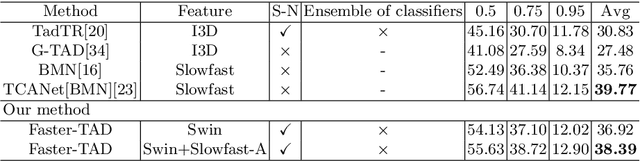
Temporal action detection (TAD) aims to detect the semantic labels and boundaries of action instances in untrimmed videos. Current mainstream approaches are multi-step solutions, which fall short in efficiency and flexibility. In this paper, we propose a unified network for TAD, termed Faster-TAD, by re-purposing a Faster-RCNN like architecture. To tackle the unique difficulty in TAD, we make important improvements over the original framework. We propose a new Context-Adaptive Proposal Module and an innovative Fake-Proposal Generation Block. What's more, we use atomic action features to improve the performance. Faster-TAD simplifies the pipeline of TAD and gets remarkable performance on lots of benchmarks, i.e., ActivityNet-1.3 (40.01% mAP), HACS Segments (38.39% mAP), SoccerNet-Action Spotting (54.09% mAP). It outperforms existing single-network detector by a large margin.
CRIS: CLIP-Driven Referring Image Segmentation
Nov 30, 2021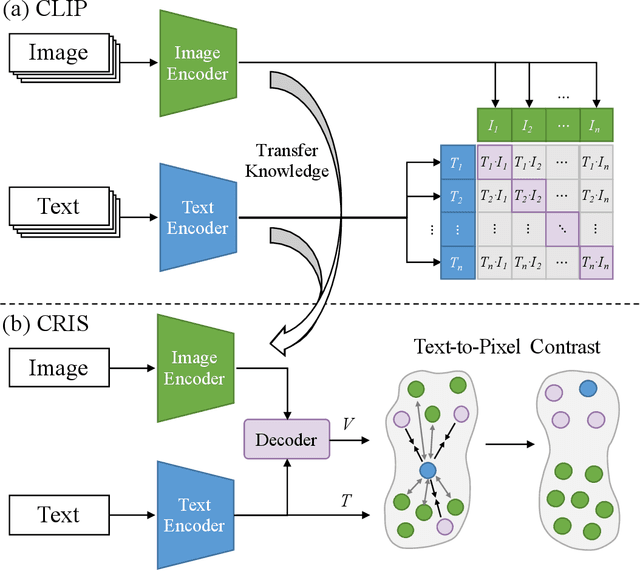
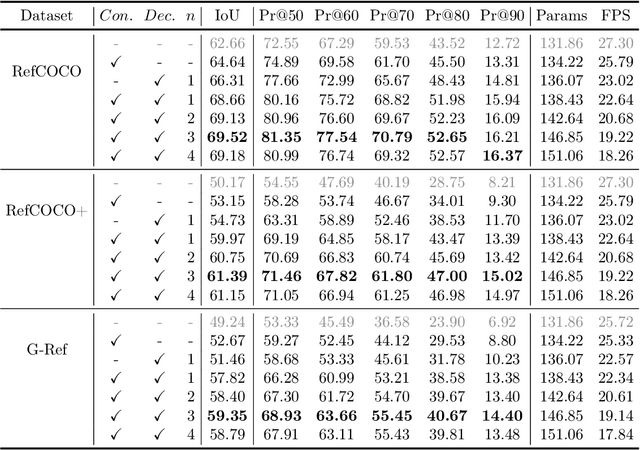

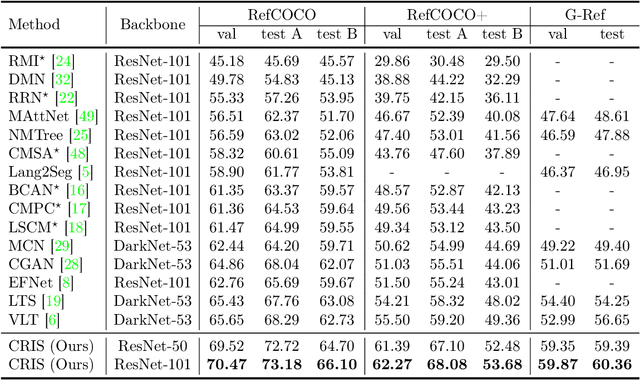
Referring image segmentation aims to segment a referent via a natural linguistic expression.Due to the distinct data properties between text and image, it is challenging for a network to well align text and pixel-level features. Existing approaches use pretrained models to facilitate learning, yet separately transfer the language/vision knowledge from pretrained models, ignoring the multi-modal corresponding information. Inspired by the recent advance in Contrastive Language-Image Pretraining (CLIP), in this paper, we propose an end-to-end CLIP-Driven Referring Image Segmentation framework (CRIS). To transfer the multi-modal knowledge effectively, CRIS resorts to vision-language decoding and contrastive learning for achieving the text-to-pixel alignment. More specifically, we design a vision-language decoder to propagate fine-grained semantic information from textual representations to each pixel-level activation, which promotes consistency between the two modalities. In addition, we present text-to-pixel contrastive learning to explicitly enforce the text feature similar to the related pixel-level features and dissimilar to the irrelevances. The experimental results on three benchmark datasets demonstrate that our proposed framework significantly outperforms the state-of-the-art performance without any post-processing. The code will be released.
Racial Faces in-the-Wild: Reducing Racial Bias by Deep Unsupervised Domain Adaptation
Dec 01, 2018
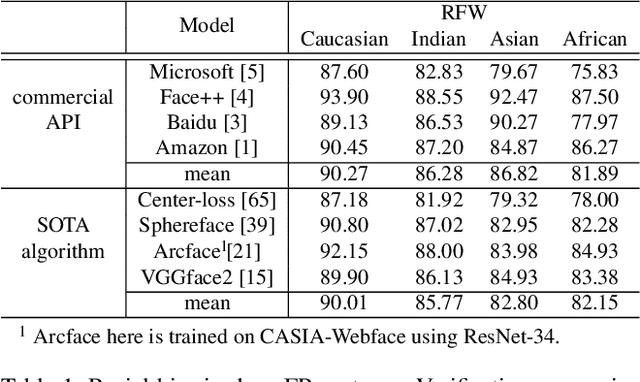
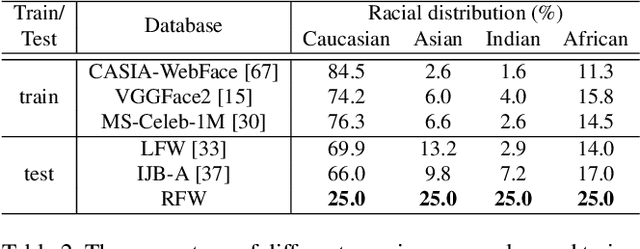

Despite of the progress achieved by deep learning in face recognition (FR), more and more people find that racial bias explicitly degrades the performance in realistic FR systems. Facing the fact that existing training and testing databases consist of almost Caucasian subjects, there are still no independent testing databases to evaluate racial bias and even no training databases and methods to reduce it. To facilitate the research towards conquering those unfair issues, this paper contributes a new dataset called Racial Faces in-the-Wild (RFW) database with two important uses, 1) racial bias testing: four testing subsets, namely Caucasian, Asian, Indian and African, are constructed, and each contains about 3000 individuals with 6000 image pairs for face verification, 2) racial bias reducing: one labeled training subset with Caucasians and three unlabeled training subsets with Asians, Indians and Africans are offered to encourage FR algorithms to transfer recognition knowledge from Caucasians to other races. For we all know, RFW is the first database for measuring racial bias in FR algorithms. After proving the existence of domain gap among different races and the existence of racial bias in FR algorithms, we further propose a deep information maximization adaptation network (IMAN) to bridge the domain gap, and comprehensive experiments show that the racial bias could be narrowed-down by our algorithm.