 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAIRS: Optimizing Redundant Assignment and List Layout for IVF-Based ANN Search
Jan 12, 2026IVF is one of the most widely used ANNS (Approximate Nearest Neighbors Search) methods in vector databases. The idea of redundant assignment is to assign a data vector to more than one IVF lists for reducing the chance of missing true neighbors in IVF search. However, the naive strategy, which selects the second IVF list based on the distance between a data vector and the list centroids, performs poorly. Previous work focuses only on the inner product distance, while there is no optimized list selection study for the most popular Euclidean space. Moreover, the IVF search may access the same vector in more than one lists, resulting in redundant distance computation and decreasing query throughput. In this paper, we present RAIRS to address the above two challenges. For the challenge of the list selection, we propose an optimized AIR metric for the Euclidean space. AIR takes not only distances but also directions into consideration in order to support queries that are closer to the data vector but father away from the first chosen list's centroid. For the challenge of redundant distance computation, we propose SEIL, an optimized list layout that exploits shared cells to reduce repeated distance computations for IVF search. Our experimental results using representative real-world data sets show that RAIRS out-performs existing redundant assignment solutions and achieves up to 1.33x improvement over the best-performing IVF method, IVF-PQ Fast Scan with refinement.
TimeMarker: A Versatile Video-LLM for Long and Short Video Understanding with Superior Temporal Localization Ability
Nov 27, 2024



Rapid development of large language models (LLMs) has significantly advanced multimodal large language models (LMMs), particularly in vision-language tasks. However, existing video-language models often overlook precise temporal localization and struggle with videos of varying lengths. We introduce TimeMarker, a versatile Video-LLM designed for high-quality dialogue based on video content, emphasizing temporal localization. TimeMarker integrates Temporal Separator Tokens to enhance temporal awareness, accurately marking specific moments within videos. It employs the AnyLength mechanism for dynamic frame sampling and adaptive token merging, enabling effective handling of both short and long videos. Additionally, TimeMarker utilizes diverse datasets, including further transformed temporal-related video QA datasets, to bolster its temporal understanding capabilities. Image and interleaved data are also employed to further enhance the model's semantic perception ability. Evaluations demonstrate that TimeMarker achieves state-of-the-art performance across multiple benchmarks, excelling in both short and long video categories. Our project page is at \url{https://github.com/TimeMarker-LLM/TimeMarker/}.
Technical Report for Soccernet 2023 -- Dense Video Captioning
Oct 31, 2024


In the task of dense video captioning of Soccernet dataset, we propose to generate a video caption of each soccer action and locate the timestamp of the caption. Firstly, we apply Blip as our video caption framework to generate video captions. Then we locate the timestamp by using (1) multi-size sliding windows (2) temporal proposal generation and (3) proposal classification.
Technical Report for ActivityNet Challenge 2022 -- Temporal Action Localization
Oct 31, 2024In the task of temporal action localization of ActivityNet-1.3 datasets, we propose to locate the temporal boundaries of each action and predict action class in untrimmed videos. We first apply VideoSwinTransformer as feature extractor to extract different features. Then we apply a unified network following Faster-TAD to simultaneously obtain proposals and semantic labels. Last, we ensemble the results of different temporal action detection models which complement each other. Faster-TAD simplifies the pipeline of TAD and gets remarkable performance, obtaining comparable results as those of multi-step approaches.
Technical Report for SoccerNet Challenge 2022 -- Replay Grounding Task
Oct 31, 2024



In order to make full use of video information, we transform the replay grounding problem into a video action location problem. We apply a unified network Faster-TAD proposed by us for temporal action detection to get the results of replay grounding. Finally, by observing the data distribution of the training data, we refine the output of the model to get the final submission.
Fewer Tokens and Fewer Videos: Extending Video Understanding Abilities in Large Vision-Language Models
Jun 12, 2024



Amidst the advancements in image-based Large Vision-Language Models (image-LVLM), the transition to video-based models (video-LVLM) is hindered by the limited availability of quality video data. This paper addresses the challenge by leveraging the visual commonalities between images and videos to efficiently evolve image-LVLMs into video-LVLMs. We present a cost-effective video-LVLM that enhances model architecture, introduces innovative training strategies, and identifies the most effective types of video instruction data. Our innovative weighted token sampler significantly compresses the visual token numbers of each video frame, effectively cutting computational expenses. We also find that judiciously using just 10% of the video data, compared to prior video-LVLMs, yields impressive results during various training phases. Moreover, we delve into the influence of video instruction data in limited-resource settings, highlighting the significance of incorporating video training data that emphasizes temporal understanding to enhance model performance. The resulting Fewer Tokens and Fewer Videos LVLM (FTFV-LVLM) exhibits exceptional performance across video and image benchmarks, validating our model's design and training approaches.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
SEAL: A Large-scale Video Dataset of Multi-grained Spatio-temporally Action Localization
Apr 06, 2022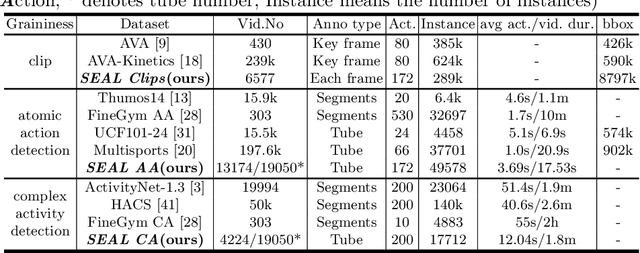
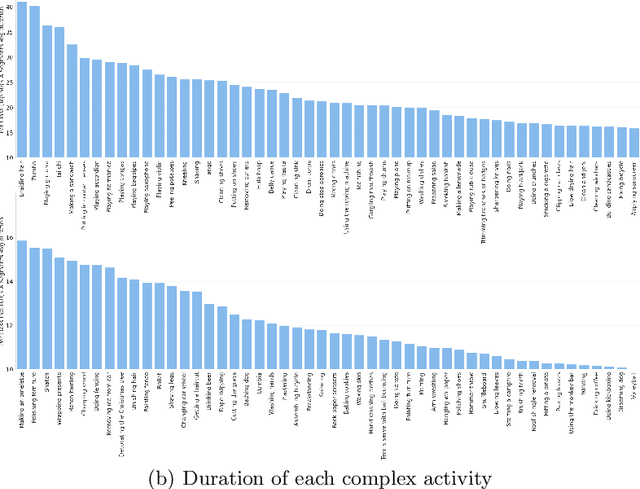
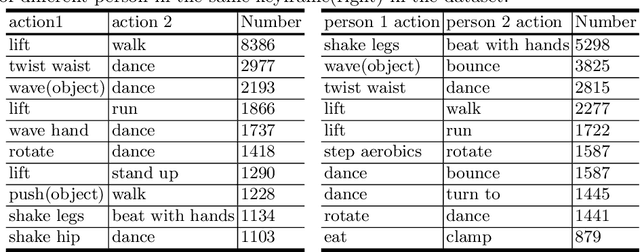
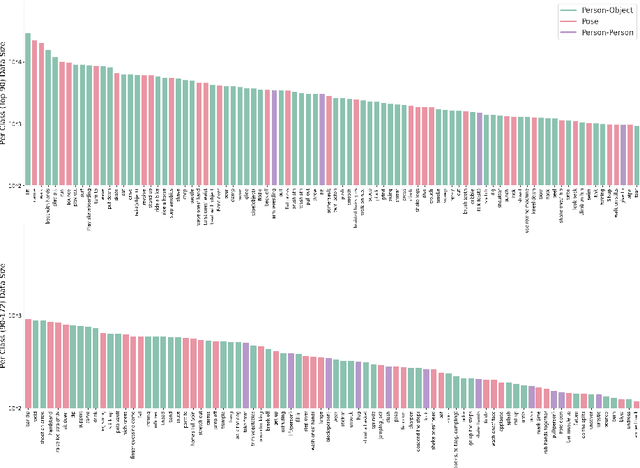
In spite of many dataset efforts for human action recognition, current computer vision algorithms are still limited to coarse-grained spatial and temporal annotations among human daily life. In this paper, we introduce a novel large-scale video dataset dubbed SEAL for multi-grained Spatio-tEmporal Action Localization. SEAL consists of two kinds of annotations, SEAL Tubes and SEAL Clips. We observe that atomic actions can be combined into many complex activities. SEAL Tubes provide both atomic action and complex activity annotations in tubelet level, producing 49.6k atomic actions spanning 172 action categories and 17.7k complex activities spanning 200 activity categories. SEAL Clips localizes atomic actions in space during two-second clips, producing 510.4k action labels with multiple labels per person. Extensive experimental results show that SEAL significantly helps to advance video understanding.
Faster-TAD: Towards Temporal Action Detection with Proposal Generation and Classification in a Unified Network
Apr 06, 2022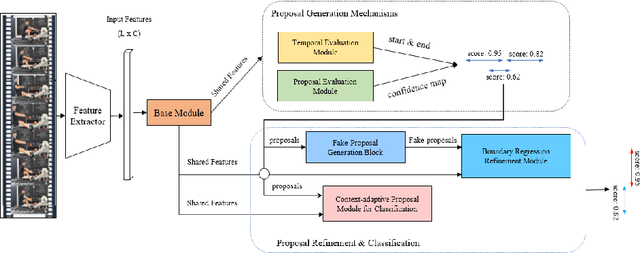
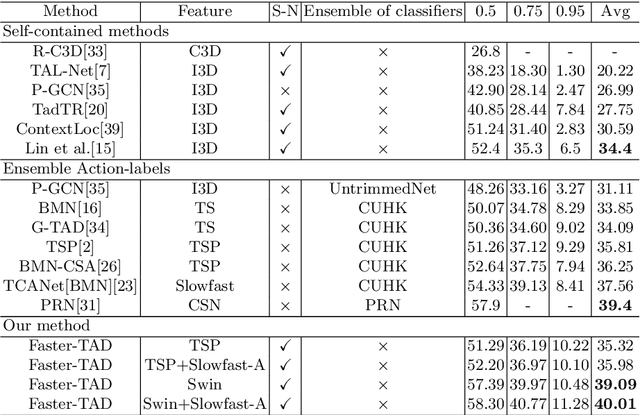
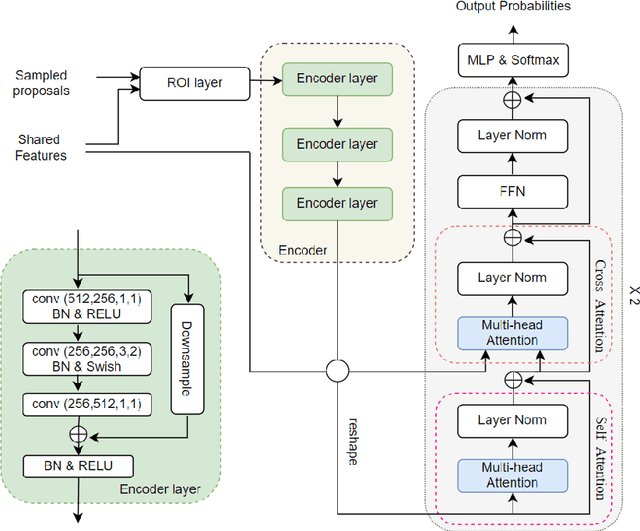
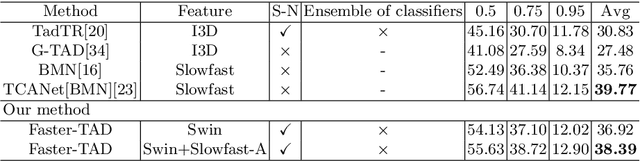
Temporal action detection (TAD) aims to detect the semantic labels and boundaries of action instances in untrimmed videos. Current mainstream approaches are multi-step solutions, which fall short in efficiency and flexibility. In this paper, we propose a unified network for TAD, termed Faster-TAD, by re-purposing a Faster-RCNN like architecture. To tackle the unique difficulty in TAD, we make important improvements over the original framework. We propose a new Context-Adaptive Proposal Module and an innovative Fake-Proposal Generation Block. What's more, we use atomic action features to improve the performance. Faster-TAD simplifies the pipeline of TAD and gets remarkable performance on lots of benchmarks, i.e., ActivityNet-1.3 (40.01% mAP), HACS Segments (38.39% mAP), SoccerNet-Action Spotting (54.09% mAP). It outperforms existing single-network detector by a large margin.