 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAL: A Large-scale Video Dataset of Multi-grained Spatio-temporally Action Localization
Paper and Code
Apr 06, 2022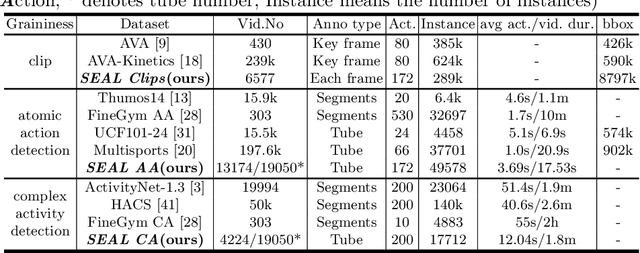
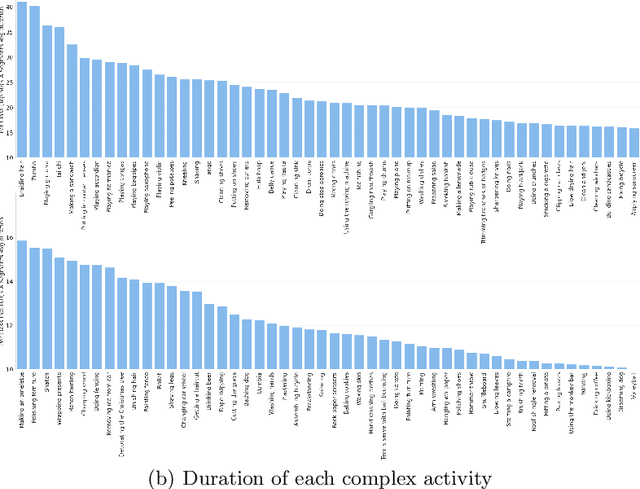
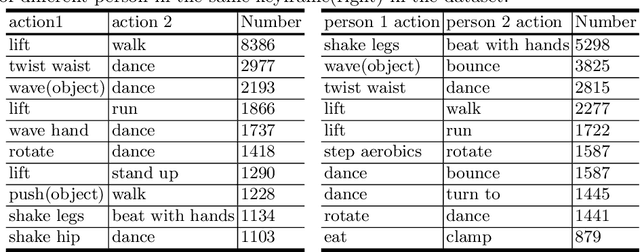
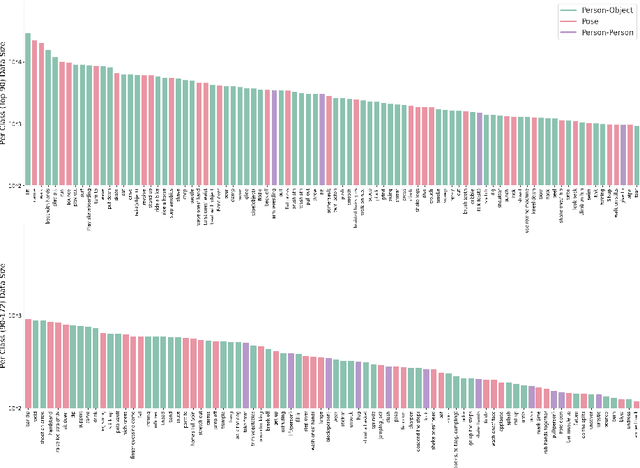
In spite of many dataset efforts for human action recognition, current computer vision algorithms are still limited to coarse-grained spatial and temporal annotations among human daily life. In this paper, we introduce a novel large-scale video dataset dubbed SEAL for multi-grained Spatio-tEmporal Action Localization. SEAL consists of two kinds of annotations, SEAL Tubes and SEAL Clips. We observe that atomic actions can be combined into many complex activities. SEAL Tubes provide both atomic action and complex activity annotations in tubelet level, producing 49.6k atomic actions spanning 172 action categories and 17.7k complex activities spanning 200 activity categories. SEAL Clips localizes atomic actions in space during two-second clips, producing 510.4k action labels with multiple labels per person. Extensive experimental results show that SEAL significantly helps to advance video understanding.