 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrawMotion: Generating 3D Human Motions by Freehand Drawing
May 20, 2026Text-to-motion generation, which translates textual descriptions into human motions, faces the challenge that users often struggle to precisely convey their intended motions through text alone. To address this issue, this paper introduces DrawMotion, an efficient diffusion-based framework designed for multi-condition scenarios. DrawMotion generates motions based on both a conventional text condition and a novel hand-drawing condition, which provide semantic and spatial control over the generated motions, respectively. Specifically, we tackle the fine-grained motion generation task from three perspectives: 1) freehand drawing condition. To accurately capture users' intended motions without requiring tedious textual input, we develop an algorithm to automatically generate hand-drawn stickman sketches across different dataset formats; 2) multi-condition fusion. We propose a Multi-Condition Module (MCM) that is integrated into the diffusion process, enabling the model to exploit all possible condition combinations while reducing computational complexity compared to conventional approaches; and 3) training-free guidance. Notably, the MCM in DrawMotion ensures that its intermediate features lie in a continuous space, allowing classifier-guidance gradients to update the features and thereby aligning the generated motions with user intentions while preserving fidelity. Quantitative experiments and user studies demonstrate that the freehand drawing approach reduces user time by approximately 46.7% when generating motions aligned with their imagination. The code, demos, and relevant data are publicly available at https://github.com/InvertedForest/DrawMotion.
Distilling Latent Manifolds: Resolution Extrapolation by Variational Autoencoders
Mar 15, 2026Variational Autoencoder (VAE) encoders play a critical role in modern generative models, yet their computational cost often motivates the use of knowledge distillation or quantification to obtain compact alternatives. Existing studies typically believe that the model work better on the samples closed to their training data distribution than unseen data distribution. In this work, we report a counter-intuitive phenomenon in VAE encoder distillation: a compact encoder distilled only at low resolutions exhibits poor reconstruction performance at its native resolution, but achieves dramatically improved results when evaluated at higher, unseen input resolutions. Despite never being trained beyond $256^2$ resolution, the distilled encoder generalizes effectively to $512^2$ resolution inputs, partially inheriting the teacher model's resolution preference.We further analyze latent distributions across resolutions and find that higher-resolution inputs produce latent representations more closely aligned with the teacher's manifold. Through extensive experiments on ImageNet-256, we show that simple resolution remapping-upsampling inputs before encoding and downsampling reconstructions for evaluation-leads to substantial gains across PSNR, MSE, SSIM, LPIPS, and rFID metrics. These findings suggest that VAE encoder distillation learns resolution-consistent latent manifolds rather than resolution-specific pixel mappings. This also means that the high training cost on memory, time and high-resolution datasets are not necessary conditions for distilling a VAE with high-resolution image reconstruction capabilities. On low resolution datasets, the distillation model still could learn the detailed knowledge of the teacher model in high-resolution image reconstruction.
ERF-BA-TFD+: A Multimodal Model for Audio-Visual Deepfake Detection
Aug 24, 2025



Deepfake detection is a critical task in identifying manipulated multimedia content. In real-world scenarios, deepfake content can manifest across multiple modalities, including audio and video. To address this challenge, we present ERF-BA-TFD+, a novel multimodal deepfake detection model that combines enhanced receptive field (ERF) and audio-visual fusion. Our model processes both audio and video features simultaneously, leveraging their complementary information to improve detection accuracy and robustness. The key innovation of ERF-BA-TFD+ lies in its ability to model long-range dependencies within the audio-visual input, allowing it to better capture subtle discrepancies between real and fake content. In our experiments, we evaluate ERF-BA-TFD+ on the DDL-AV dataset, which consists of both segmented and full-length video clips. Unlike previous benchmarks, which focused primarily on isolated segments, the DDL-AV dataset allows us to assess the model's performance in a more comprehensive and realistic setting. Our method achieves state-of-the-art results on this dataset, outperforming existing techniques in terms of both accuracy and processing speed. The ERF-BA-TFD+ model demonstrated its effectiveness in the "Workshop on Deepfake Detection, Localization, and Interpretability," Track 2: Audio-Visual Detection and Localization (DDL-AV), and won first place in this competition.
StickMotion: Generating 3D Human Motions by Drawing a Stickman
Mar 05, 2025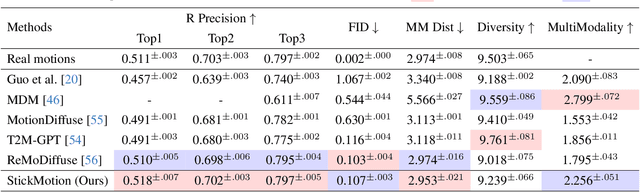
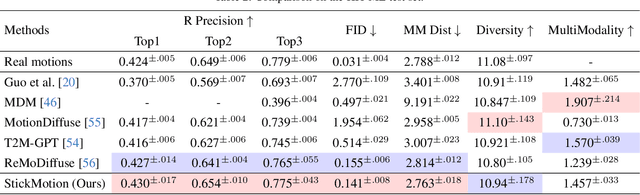
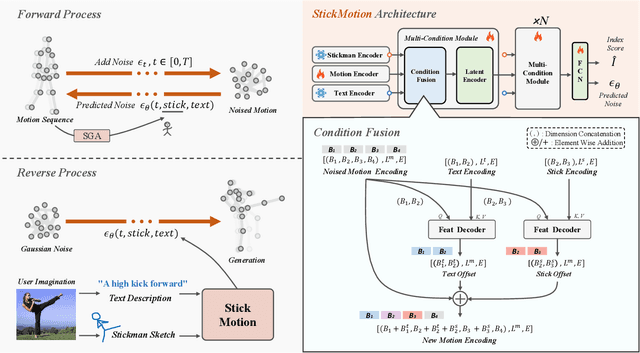
Text-to-motion generation, which translates textual descriptions into human motions, has been challenging in accurately capturing detailed user-imagined motions from simple text inputs. This paper introduces StickMotion, an efficient diffusion-based network designed for multi-condition scenarios, which generates desired motions based on traditional text and our proposed stickman conditions for global and local control of these motions, respectively. We address the challenges introduced by the user-friendly stickman from three perspectives: 1) Data generation. We develop an algorithm to generate hand-drawn stickmen automatically across different dataset formats. 2) Multi-condition fusion. We propose a multi-condition module that integrates into the diffusion process and obtains outputs of all possible condition combinations, reducing computational complexity and enhancing StickMotion's performance compared to conventional approaches with the self-attention module. 3) Dynamic supervision. We empower StickMotion to make minor adjustments to the stickman's position within the output sequences, generating more natural movements through our proposed dynamic supervision strategy. Through quantitative experiments and user studies, sketching stickmen saves users about 51.5% of their time generating motions consistent with their imagination. Our codes, demos, and relevant data will be released to facilitate further research and validation within the scientific community.
DiffBrush:Just Painting the Art by Your Hands
Feb 28, 2025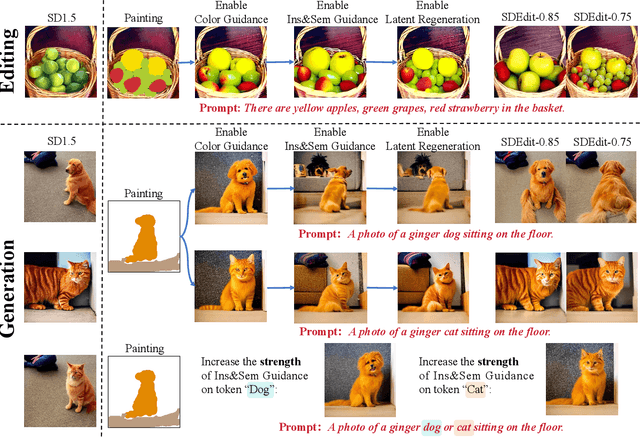
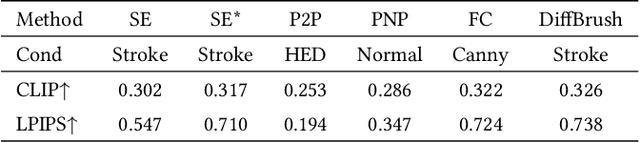
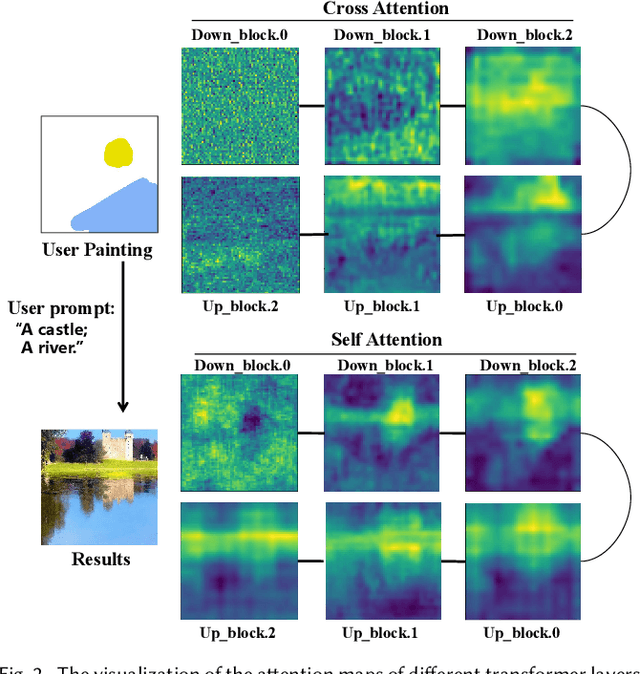
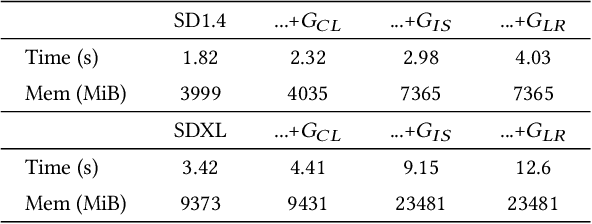
The rapid development of image generation and editing algorithms in recent years has enabled ordinary user to produce realistic images. However, the current AI painting ecosystem predominantly relies on text-driven diffusion models (T2I), which pose challenges in accurately capturing user requirements. Furthermore, achieving compatibility with other modalities incurs substantial training costs. To this end, we introduce DiffBrush, which is compatible with T2I models and allows users to draw and edit images. By manipulating and adapting the internal representation of the diffusion model, DiffBrush guides the model-generated images to converge towards the user's hand-drawn sketches for user's specific needs without additional training. DiffBrush achieves control over the color, semantic, and instance of objects in images by continuously guiding the latent and instance-level attention map during the denoising process of the diffusion model. Besides, we propose a latent regeneration, which refines the randomly sampled noise in the diffusion model, obtaining a better image generation layout. Finally, users only need to roughly draw the mask of the instance (acceptable colors) on the canvas, DiffBrush can naturally generate the corresponding instance at the corresponding location.
EraseAnything: Enabling Concept Erasure in Rectified Flow Transformers
Dec 29, 2024Removing unwanted concepts from large-scale text-to-image (T2I) diffusion models while maintaining their overall generative quality remains an open challenge. This difficulty is especially pronounced in emerging paradigms, such as Stable Diffusion (SD) v3 and Flux, which incorporate flow matching and transformer-based architectures. These advancements limit the transferability of existing concept-erasure techniques that were originally designed for the previous T2I paradigm (\textit{e.g.}, SD v1.4). In this work, we introduce \logopic \textbf{EraseAnything}, the first method specifically developed to address concept erasure within the latest flow-based T2I framework. We formulate concept erasure as a bi-level optimization problem, employing LoRA-based parameter tuning and an attention map regularizer to selectively suppress undesirable activations. Furthermore, we propose a self-contrastive learning strategy to ensure that removing unwanted concepts does not inadvertently harm performance on unrelated ones. Experimental results demonstrate that EraseAnything successfully fills the research gap left by earlier methods in this new T2I paradigm, achieving state-of-the-art performance across a wide range of concept erasure tasks.
Technical Report for SoccerNet Challenge 2022 -- Replay Grounding Task
Oct 31, 2024



In order to make full use of video information, we transform the replay grounding problem into a video action location problem. We apply a unified network Faster-TAD proposed by us for temporal action detection to get the results of replay grounding. Finally, by observing the data distribution of the training data, we refine the output of the model to get the final submission.
Towards Automated Data Sciences with Natural Language and SageCopilot: Practices and Lessons Learned
Jul 21, 2024



While the field of NL2SQL has made significant advancements in translating natural language instructions into executable SQL scripts for data querying and processing, achieving full automation within the broader data science pipeline - encompassing data querying, analysis, visualization, and reporting - remains a complex challenge. This study introduces SageCopilot, an advanced, industry-grade system system that automates the data science pipeline by integrating Large Language Models (LLMs), Autonomous Agents (AutoAgents), and Language User Interfaces (LUIs). Specifically, SageCopilot incorporates a two-phase design: an online component refining users' inputs into executable scripts through In-Context Learning (ICL) and running the scripts for results reporting & visualization, and an offline preparing demonstrations requested by ICL in the online phase. A list of trending strategies such as Chain-of-Thought and prompt-tuning have been used to augment SageCopilot for enhanced performance. Through rigorous testing and comparative analysis against prompt-based solutions, SageCopilot has been empirically validated to achieve superior end-to-end performance in generating or executing scripts and offering results with visualization, backed by real-world datasets. Our in-depth ablation studies highlight the individual contributions of various components and strategies used by SageCopilot to the end-to-end correctness for data sciences.
UniParser: Multi-Human Parsing with Unified Correlation Representation Learning
Oct 13, 2023


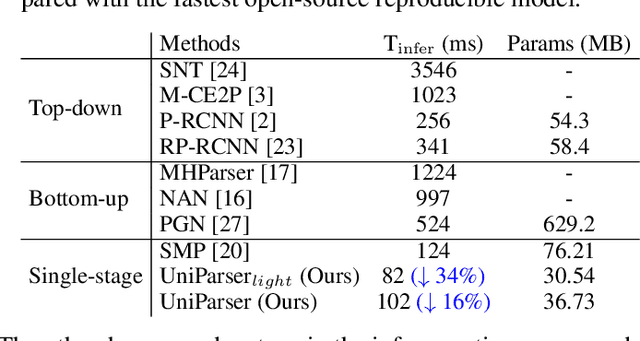
Multi-human parsing is an image segmentation task necessitating both instance-level and fine-grained category-level information. However, prior research has typically processed these two types of information through separate branches and distinct output formats, leading to inefficient and redundant frameworks. This paper introduces UniParser, which integrates instance-level and category-level representations in three key aspects: 1) we propose a unified correlation representation learning approach, allowing our network to learn instance and category features within the cosine space; 2) we unify the form of outputs of each modules as pixel-level segmentation results while supervising instance and category features using a homogeneous label accompanied by an auxiliary loss; and 3) we design a joint optimization procedure to fuse instance and category representations. By virtual of unifying instance-level and category-level output, UniParser circumvents manually designed post-processing techniques and surpasses state-of-the-art methods, achieving 49.3% AP on MHPv2.0 and 60.4% AP on CIHP. We will release our source code, pretrained models, and online demos to facilitate future studies.
The 3rd Anti-UAV Workshop & Challenge: Methods and Results
May 12, 2023


The 3rd Anti-UAV Workshop & Challenge aims to encourage research in developing novel and accurate methods for multi-scale object tracking. The Anti-UAV dataset used for the Anti-UAV Challenge has been publicly released. There are two main differences between this year's competition and the previous two. First, we have expanded the existing dataset, and for the first time, released a training set so that participants can focus on improving their models. Second, we set up two tracks for the first time, i.e., Anti-UAV Tracking and Anti-UAV Detection & Tracking. Around 76 participating teams from the globe competed in the 3rd Anti-UAV Challenge. In this paper, we provide a brief summary of the 3rd Anti-UAV Workshop & Challenge including brief introductions to the top three methods in each track. The submission leaderboard will be reopened for researchers that are interested in the Anti-UAV challenge. The benchmark dataset and other information can be found at: https://anti-uav.github.io/.