 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Exploration in Hybrid-Policy RLVR for Multi-Modal Reasoning
Feb 22, 2026Reinforcement Learning with verifiable rewards (RLVR) has emerged as a primary learning paradigm for enhancing the reasoning capabilities of multi-modal large language models (MLLMs). However, during RL training, the enormous state space of MLLM and sparse rewards often leads to entropy collapse, policy degradation, or over-exploitation of suboptimal behaviors. This necessitates an exploration strategy that maintains productive stochasticity while avoiding the drawbacks of uncontrolled random sampling, yielding inefficient exploration. In this paper, we propose CalibRL, a hybrid-policy RLVR framework that supports controllable exploration with expert guidance, enabled by two key mechanisms. First, a distribution-aware advantage weighting scales updates by group rareness to calibrate the distribution, therefore preserving exploration. Meanwhile, the asymmetric activation function (LeakyReLU) leverages the expert knowledge as a calibration baseline to moderate overconfident updates while preserving their corrective direction. CalibRL increases policy entropy in a guided manner and clarifies the target distribution by estimating the on-policy distribution through online sampling. Updates are driven by these informative behaviors, avoiding convergence to erroneous patterns. Importantly, these designs help alleviate the distributional mismatch between the model's policy and expert trajectories, thereby achieving a more stable balance between exploration and exploitation. Extensive experiments across eight benchmarks, including both in-domain and out-of-domain settings, demonstrate consistent improvements, validating the effectiveness of our controllable hybrid-policy RLVR training. Code is available at https://github.com/zhh6425/CalibRL.
Agentic Memory Enhanced Recursive Reasoning for Root Cause Localization in Microservices
Jan 06, 2026As contemporary microservice systems become increasingly popular and complex-often comprising hundreds or even thousands of fine-grained, interdependent subsystems-they are experiencing more frequent failures. Ensuring system reliability thus demands accurate root cause localization. While many traditional graph-based and deep learning approaches have been explored for this task, they often rely heavily on pre-defined schemas that struggle to adapt to evolving operational contexts. Consequently, a number of LLM-based methods have recently been proposed. However, these methods still face two major limitations: shallow, symptom-centric reasoning that undermines accuracy, and a lack of cross-alert reuse that leads to redundant reasoning and high latency. In this paper, we conduct a comprehensive study of how Site Reliability Engineers (SREs) localize the root causes of failures, drawing insights from professionals across multiple organizations. Our investigation reveals that expert root cause analysis exhibits three key characteristics: recursiveness, multi-dimensional expansion, and cross-modal reasoning. Motivated by these findings, we introduce AMER-RCL, an agentic memory enhanced recursive reasoning framework for root cause localization in microservices. AMER-RCL employs the Recursive Reasoning RCL engine, a multi-agent framework that performs recursive reasoning on each alert to progressively refine candidate causes, while Agentic Memory incrementally accumulates and reuses reasoning from prior alerts within a time window to reduce redundant exploration and lower inference latency. Experimental results demonstrate that AMER-RCL consistently outperforms state-of-the-art methods in both localization accuracy and inference efficiency.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
EraseAnything: Enabling Concept Erasure in Rectified Flow Transformers
Dec 29, 2024Removing unwanted concepts from large-scale text-to-image (T2I) diffusion models while maintaining their overall generative quality remains an open challenge. This difficulty is especially pronounced in emerging paradigms, such as Stable Diffusion (SD) v3 and Flux, which incorporate flow matching and transformer-based architectures. These advancements limit the transferability of existing concept-erasure techniques that were originally designed for the previous T2I paradigm (\textit{e.g.}, SD v1.4). In this work, we introduce \logopic \textbf{EraseAnything}, the first method specifically developed to address concept erasure within the latest flow-based T2I framework. We formulate concept erasure as a bi-level optimization problem, employing LoRA-based parameter tuning and an attention map regularizer to selectively suppress undesirable activations. Furthermore, we propose a self-contrastive learning strategy to ensure that removing unwanted concepts does not inadvertently harm performance on unrelated ones. Experimental results demonstrate that EraseAnything successfully fills the research gap left by earlier methods in this new T2I paradigm, achieving state-of-the-art performance across a wide range of concept erasure tasks.
Reducing Events to Augment Log-based Anomaly Detection Models: An Empirical Study
Sep 07, 2024As software systems grow increasingly intricate, the precise detection of anomalies have become both essential and challenging. Current log-based anomaly detection methods depend heavily on vast amounts of log data leading to inefficient inference and potential misguidance by noise logs. However, the quantitative effects of log reduction on the effectiveness of anomaly detection remain unexplored. Therefore, we first conduct a comprehensive study on six distinct models spanning three datasets. Through the study, the impact of log quantity and their effectiveness in representing anomalies is qualifies, uncovering three distinctive log event types that differently influence model performance. Drawing from these insights, we propose LogCleaner: an efficient methodology for the automatic reduction of log events in the context of anomaly detection. Serving as middleware between software systems and models, LogCleaner continuously updates and filters anti-events and duplicative-events in the raw generated logs. Experimental outcomes highlight LogCleaner's capability to reduce over 70% of log events in anomaly detection, accelerating the model's inference speed by approximately 300%, and universally improving the performance of models for anomaly detection.
Population-Based Evolutionary Gaming for Unsupervised Person Re-identification
Jun 08, 2023Unsupervised person re-identification has achieved great success through the self-improvement of individual neural networks. However, limited by the lack of diversity of discriminant information, a single network has difficulty learning sufficient discrimination ability by itself under unsupervised conditions. To address this limit, we develop a population-based evolutionary gaming (PEG) framework in which a population of diverse neural networks is trained concurrently through selection, reproduction, mutation, and population mutual learning iteratively. Specifically, the selection of networks to preserve is modeled as a cooperative game and solved by the best-response dynamics, then the reproduction and mutation are implemented by cloning and fluctuating hyper-parameters of networks to learn more diversity, and population mutual learning improves the discrimination of networks by knowledge distillation from each other within the population. In addition, we propose a cross-reference scatter (CRS) to approximately evaluate re-ID models without labeled samples and adopt it as the criterion of network selection in PEG. CRS measures a model's performance by indirectly estimating the accuracy of its predicted pseudo-labels according to the cohesion and separation of the feature space. Extensive experiments demonstrate that (1) CRS approximately measures the performance of models without labeled samples; (2) and PEG produces new state-of-the-art accuracy for person re-identification, indicating the great potential of population-based network cooperative training for unsupervised learning.
Learning Disentangled Representation Implicitly via Transformer for Occluded Person Re-Identification
Jul 06, 2021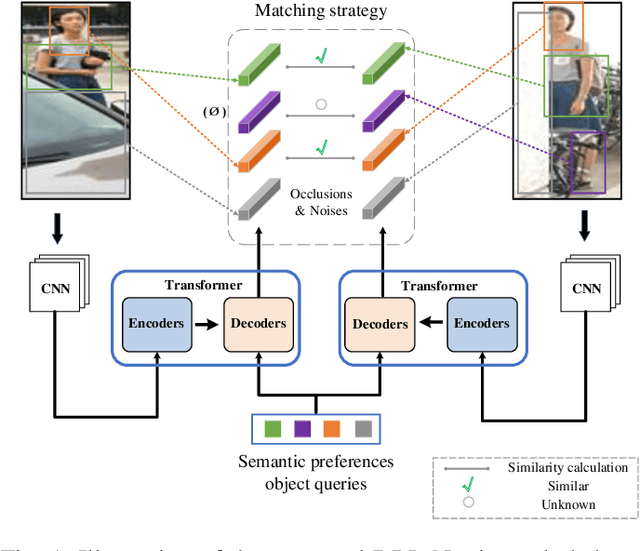
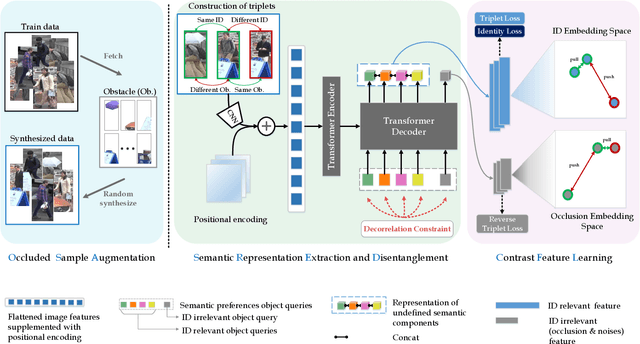

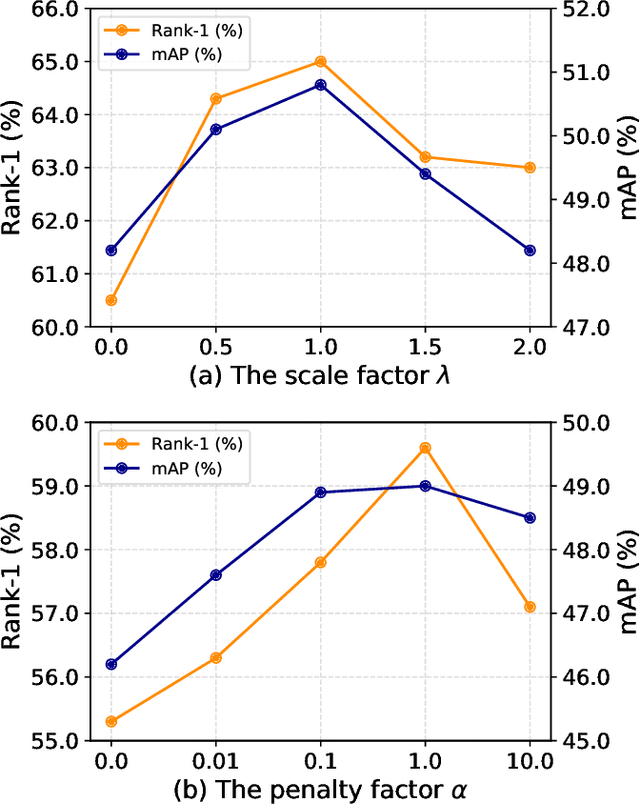
Person re-identification (re-ID) under various occlusions has been a long-standing challenge as person images with different types of occlusions often suffer from misalignment in image matching and ranking. Most existing methods tackle this challenge by aligning spatial features of body parts according to external semantic cues or feature similarities but this alignment approach is complicated and sensitive to noises. We design DRL-Net, a disentangled representation learning network that handles occluded re-ID without requiring strict person image alignment or any additional supervision. Leveraging transformer architectures, DRL-Net achieves alignment-free re-ID via global reasoning of local features of occluded person images. It measures image similarity by automatically disentangling the representation of undefined semantic components, e.g., human body parts or obstacles, under the guidance of semantic preference object queries in the transformer. In addition, we design a decorrelation constraint in the transformer decoder and impose it over object queries for better focus on different semantic components. To better eliminate interference from occlusions, we design a contrast feature learning technique (CFL) for better separation of occlusion features and discriminative ID features. Extensive experiments over occluded and holistic re-ID benchmarks (Occluded-DukeMTMC, Market1501 and DukeMTMC) show that the DRL-Net achieves superior re-ID performance consistently and outperforms the state-of-the-art by large margins for Occluded-DukeMTMC.
Multiple Expert Brainstorming for Domain Adaptive Person Re-identification
Jul 13, 2020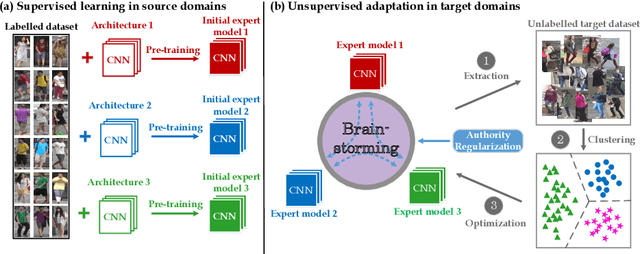

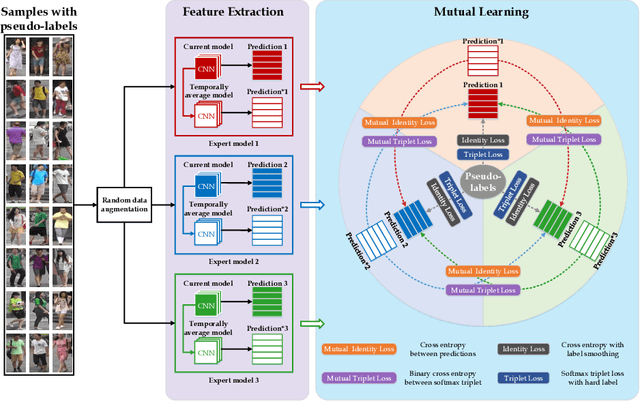
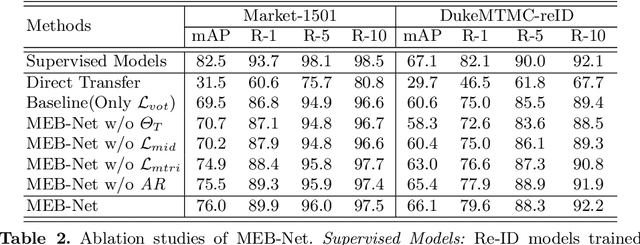
Often the best performing deep neural models are ensembles of multiple base-level networks, nevertheless, ensemble learning with respect to domain adaptive person re-ID remains unexplored. In this paper, we propose a multiple expert brainstorming network (MEB-Net) for domain adaptive person re-ID, opening up a promising direction about model ensemble problem under unsupervised conditions. MEB-Net adopts a mutual learning strategy, where multiple networks with different architectures are pre-trained within a source domain as expert models equipped with specific features and knowledge, while the adaptation is then accomplished through brainstorming (mutual learning) among expert models. MEB-Net accommodates the heterogeneity of experts learned with different architectures and enhances discrimination capability of the adapted re-ID model, by introducing a regularization scheme about authority of experts. Extensive experiments on large-scale datasets (Market-1501 and DukeMTMC-reID) demonstrate the superior performance of MEB-Net over the state-of-the-arts.
A Similarity Inference Metric for RGB-Infrared Cross-Modality Person Re-identification
Jul 03, 2020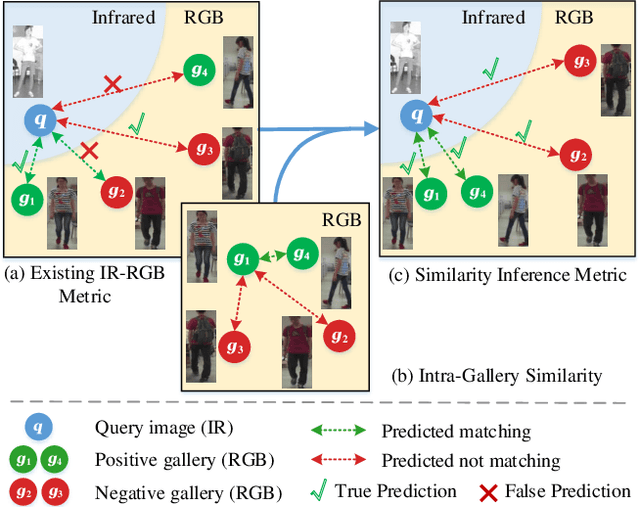
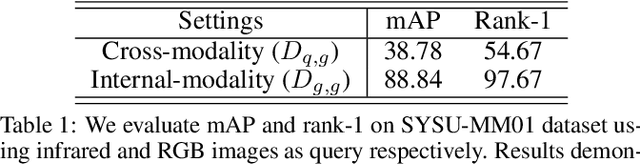
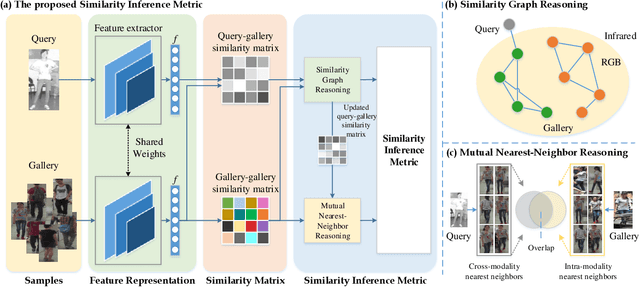
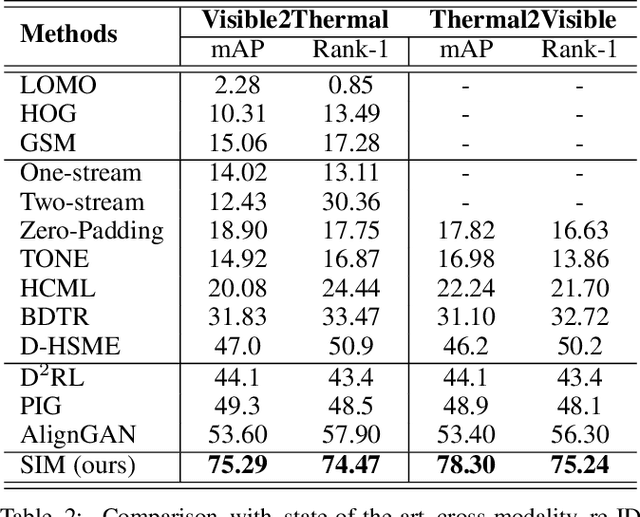
RGB-Infrared (IR) cross-modality person re-identification (re-ID), which aims to search an IR image in RGB gallery or vice versa, is a challenging task due to the large discrepancy between IR and RGB modalities. Existing methods address this challenge typically by aligning feature distributions or image styles across modalities, whereas the very useful similarities among gallery samples of the same modality (i.e. intra-modality sample similarities) is largely neglected. This paper presents a novel similarity inference metric (SIM) that exploits the intra-modality sample similarities to circumvent the cross-modality discrepancy targeting optimal cross-modality image matching. SIM works by successive similarity graph reasoning and mutual nearest-neighbor reasoning that mine cross-modality sample similarities by leveraging intra-modality sample similarities from two different perspectives. Extensive experiments over two cross-modality re-ID datasets (SYSU-MM01 and RegDB) show that SIM achieves significant accuracy improvement but with little extra training as compared with the state-of-the-art.