 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster-TAD: Towards Temporal Action Detection with Proposal Generation and Classification in a Unified Network
Paper and Code
Apr 06, 2022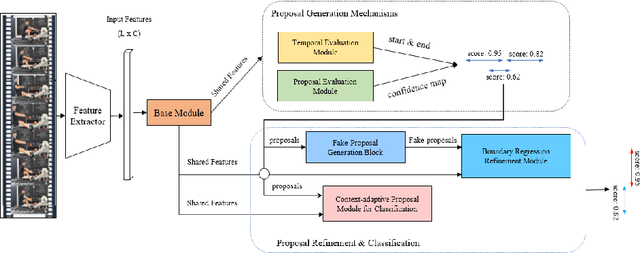
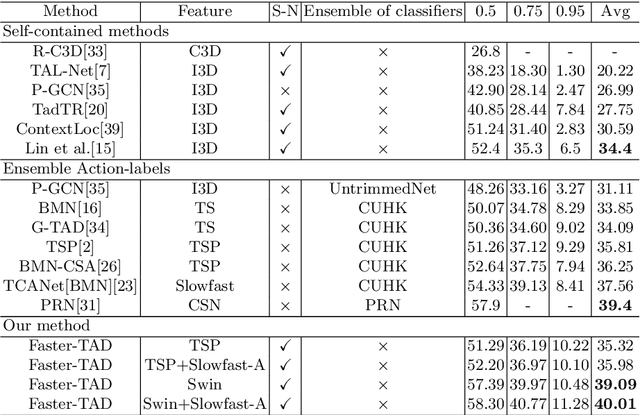
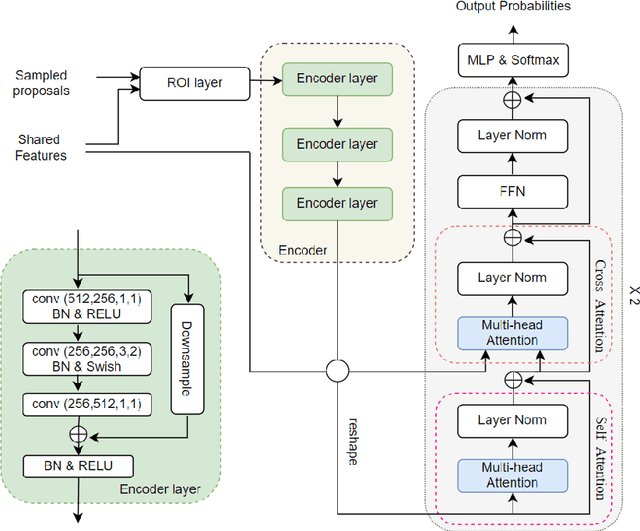
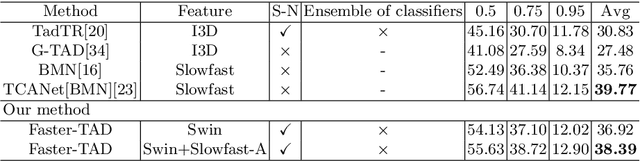
Temporal action detection (TAD) aims to detect the semantic labels and boundaries of action instances in untrimmed videos. Current mainstream approaches are multi-step solutions, which fall short in efficiency and flexibility. In this paper, we propose a unified network for TAD, termed Faster-TAD, by re-purposing a Faster-RCNN like architecture. To tackle the unique difficulty in TAD, we make important improvements over the original framework. We propose a new Context-Adaptive Proposal Module and an innovative Fake-Proposal Generation Block. What's more, we use atomic action features to improve the performance. Faster-TAD simplifies the pipeline of TAD and gets remarkable performance on lots of benchmarks, i.e., ActivityNet-1.3 (40.01% mAP), HACS Segments (38.39% mAP), SoccerNet-Action Spotting (54.09% mAP). It outperforms existing single-network detector by a large margin.