 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaimDiff-RL: Fine-Grained Caption Reinforcement Learning through Visual Claim Comparison
May 19, 2026Long-form image captioning exposes a reward granularity problem in RL: captions are judged as whole sequences, while the important errors occur at the level of individual visual claims. A good dense caption should be both faithful and informative, avoiding hallucination without omitting salient details. Yet pairwise preferences, reference-based metrics, and holistic scalar rewards compress these local errors into a single sequence-level signal, obscuring the tradeoff between factuality and coverage. We introduce ClaimDiff-RL, a framework that uses reference-conditioned atomic claim differences as the reward unit for caption RL. Given an image, an actor caption, and a reference caption, a multimodal judge enumerates visually grounded differences, verifies each difference against the image, assigns open-vocabulary error types and severity levels, and produces per-difference statistics for reward composition. This makes hallucinated claims and omitted salient facts separately measurable and tunable. Experiments show that holistic scalar rewards can reduce hallucination by increasing missing facts, while ClaimDiff-RL exposes this faithfulness and coverage tradeoff and enables more balanced operating points. On a 160-image human-labeled diagnostic benchmark, public captioning benchmarks, and VQA benchmarks, ClaimDiff-RL improves the hallucination--missing-fact balance, preserves general capability, and even surpasses Gemini-3-Pro-Preview on several fine-grained Capability dimensions such as object counting, spatial relations, and scene recognition. These results suggest that typed, verifiable claim differences are an effective reward unit for fine-grained and diagnosable caption RL.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
OmniGenBench: A Benchmark for Omnipotent Multimodal Generation across 50+ Tasks
May 24, 2025



Recent breakthroughs in large multimodal models (LMMs), such as the impressive GPT-4o-Native, have demonstrated remarkable proficiency in following general-purpose instructions for image generation. However, current benchmarks often lack the necessary breadth and depth to fully evaluate the diverse capabilities of these models. To overcome this limitation, we introduce OmniGenBench, a novel and comprehensive benchmark meticulously designed to assess the instruction-following abilities of state-of-the-art LMMs across both perception-centric and cognition-centric dimensions. Our OmniGenBench includes 57 diverse sub-tasks grounded in real-world scenarios, systematically categorized according to the specific model capabilities they demand. For rigorous evaluation, we further employ a dual-mode protocol. This protocol utilizes off-the-shelf visual parsing tools for perception-centric tasks and a powerful LLM-based judger for cognition-centric tasks to assess the alignment between generated images and user instructions. Using OmniGenBench, we evaluate mainstream generative models, including prevalent models like GPT-4o, Gemini-2.0-Flash, and Seedream, and provide in-depth comparisons and analyses of their performance.Code and data are available at https://github.com/emilia113/OmniGenBench.
One RL to See Them All: Visual Triple Unified Reinforcement Learning
May 23, 2025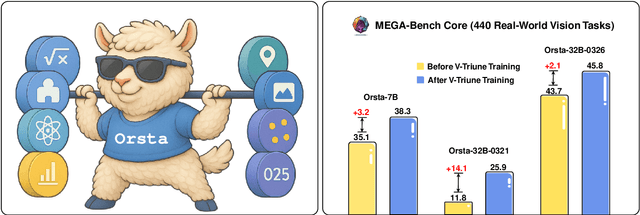
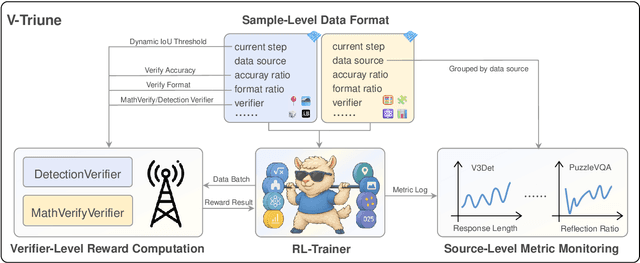
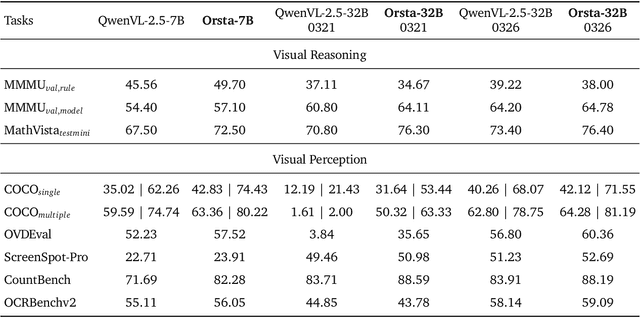
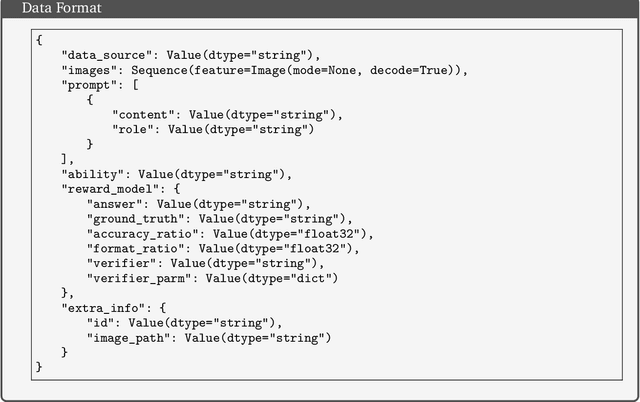
Reinforcement learning (RL) has significantly advanced the reasoning capabilities of vision-language models (VLMs). However, the use of RL beyond reasoning tasks remains largely unexplored, especially for perceptionintensive tasks like object detection and grounding. We propose V-Triune, a Visual Triple Unified Reinforcement Learning system that enables VLMs to jointly learn visual reasoning and perception tasks within a single training pipeline. V-Triune comprises triple complementary components: Sample-Level Data Formatting (to unify diverse task inputs), Verifier-Level Reward Computation (to deliver custom rewards via specialized verifiers) , and Source-Level Metric Monitoring (to diagnose problems at the data-source level). We further introduce a novel Dynamic IoU reward, which provides adaptive, progressive, and definite feedback for perception tasks handled by V-Triune. Our approach is instantiated within off-the-shelf RL training framework using open-source 7B and 32B backbone models. The resulting model, dubbed Orsta (One RL to See Them All), demonstrates consistent improvements across both reasoning and perception tasks. This broad capability is significantly shaped by its training on a diverse dataset, constructed around four representative visual reasoning tasks (Math, Puzzle, Chart, and Science) and four visual perception tasks (Grounding, Detection, Counting, and OCR). Subsequently, Orsta achieves substantial gains on MEGA-Bench Core, with improvements ranging from +2.1 to an impressive +14.1 across its various 7B and 32B model variants, with performance benefits extending to a wide range of downstream tasks. These results highlight the effectiveness and scalability of our unified RL approach for VLMs. The V-Triune system, along with the Orsta models, is publicly available at https://github.com/MiniMax-AI.
UniToken: Harmonizing Multimodal Understanding and Generation through Unified Visual Encoding
Apr 06, 2025We introduce UniToken, an auto-regressive generation model that encodes visual inputs through a combination of discrete and continuous representations, enabling seamless integration of unified visual understanding and image generation tasks. Unlike previous approaches that rely on unilateral visual representations, our unified visual encoding framework captures both high-level semantics and low-level details, delivering multidimensional information that empowers heterogeneous tasks to selectively assimilate domain-specific knowledge based on their inherent characteristics. Through in-depth experiments, we uncover key principles for developing a unified model capable of both visual understanding and image generation. Extensive evaluations across a diverse range of prominent benchmarks demonstrate that UniToken achieves state-of-the-art performance, surpassing existing approaches. These results establish UniToken as a robust foundation for future research in this domain. The code and models are available at https://github.com/SxJyJay/UniToken.
ChatTracker: Enhancing Visual Tracking Performance via Chatting with Multimodal Large Language Model
Nov 04, 2024



Visual object tracking aims to locate a targeted object in a video sequence based on an initial bounding box. Recently, Vision-Language~(VL) trackers have proposed to utilize additional natural language descriptions to enhance versatility in various applications. However, VL trackers are still inferior to State-of-The-Art (SoTA) visual trackers in terms of tracking performance. We found that this inferiority primarily results from their heavy reliance on manual textual annotations, which include the frequent provision of ambiguous language descriptions. In this paper, we propose ChatTracker to leverage the wealth of world knowledge in the Multimodal Large Language Model (MLLM) to generate high-quality language descriptions and enhance tracking performance. To this end, we propose a novel reflection-based prompt optimization module to iteratively refine the ambiguous and inaccurate descriptions of the target with tracking feedback. To further utilize semantic information produced by MLLM, a simple yet effective VL tracking framework is proposed and can be easily integrated as a plug-and-play module to boost the performance of both VL and visual trackers. Experimental results show that our proposed ChatTracker achieves a performance comparable to existing methods.
EAGLE: Towards Efficient Arbitrary Referring Visual Prompts Comprehension for Multimodal Large Language Models
Sep 26, 2024



Recently, Multimodal Large Language Models (MLLMs) have sparked great research interests owing to their exceptional content-reasoning and instruction-following capabilities. To effectively instruct an MLLM, in addition to conventional language expressions, the practice of referring to objects by painting with brushes on images has emerged as a prevalent tool (referred to as "referring visual prompts") due to its efficacy in aligning the user's intention with specific image regions. To accommodate the most common referring visual prompts, namely points, boxes, and masks, existing approaches initially utilize specialized feature encoding modules to capture the semantics of the highlighted areas indicated by these prompts. Subsequently, these encoded region features are adapted to MLLMs through fine-tuning on a meticulously curated multimodal instruction dataset. However, such designs suffer from redundancy in architecture. Moreover, they face challenges in effectively generalizing when encountering a diverse range of arbitrary referring visual prompts in real-life scenarios. To address the above issues, we propose EAGLE, a novel MLLM that empowers comprehension of arbitrary referring visual prompts with less training efforts than existing approaches. Specifically, our EAGLE maintains the innate format of the referring visual prompts as colored patches rendered on the given image for conducting the instruction tuning. Our approach embeds referring visual prompts as spatial concepts conveying specific spatial areas comprehensible to the MLLM, with the semantic comprehension of these regions originating from the MLLM itself. Besides, we also propose a Geometry-Agnostic Learning paradigm (GAL) to further disentangle the MLLM's region-level comprehension with the specific formats of referring visual prompts. Extensive experiments are conducted to prove the effectiveness of our proposed method.
EventHallusion: Diagnosing Event Hallucinations in Video LLMs
Sep 25, 2024
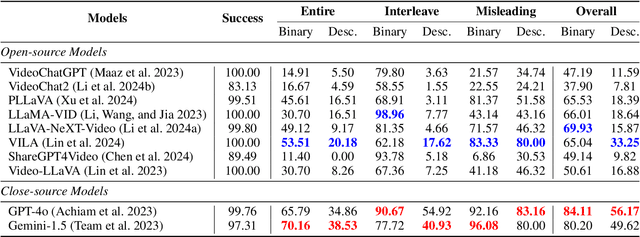

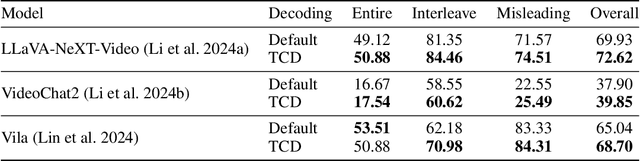
Recently, Multimodal Large Language Models (MLLMs) have made significant progress in the video comprehension field. Despite remarkable content reasoning and instruction following capabilities they demonstrated, the hallucination problem of these VideoLLMs is less explored compared with its counterpart in the image domain. To mitigate this gap, we first propose EventHallusion, a novel benchmark that focuses on assessing the VideoLMMs' hallucination phenomenon on video event comprehension. Based on the observation that existing VideoLLMs are entangled with the priors stemming from their foundation models, our EventHallusion is curated by meticulously collecting videos and annotating questions to intentionally mislead the VideoLLMs into interpreting events based on these priors rather than accurately understanding the video content. On the other hand, we also propose a simple yet effective method, called Temporal Contrastive Decoding (TCD), to tackle the hallucination problems of VideoLLMs. The proposed TCD suppresses the model's preference toward their priors by comparing the original video with a constructed counterpart, whose temporal cues are disrupted, during the autoregressive decoding stage. Through comprehensive evaluation of eight open-source and two closed-source VideoLLMs on the proposed EventHallusion benchmark, we find that the open-source models suffer significantly from hallucination problems, whereas the closed-source models perform markedly better. By further equipping open-sourced VideoLLMs with the proposed TCD approach, evident performance improvements are achieved across most metrics in the EventHallusion benchmark. Our codes and benchmark data are available at https://github.com/Stevetich/EventHallusion.
Making Large Language Models Better Planners with Reasoning-Decision Alignment
Aug 25, 2024Data-driven approaches for autonomous driving (AD) have been widely adopted in the past decade but are confronted with dataset bias and uninterpretability. Inspired by the knowledge-driven nature of human driving, recent approaches explore the potential of large language models (LLMs) to improve understanding and decision-making in traffic scenarios. They find that the pretrain-finetune paradigm of LLMs on downstream data with the Chain-of-Thought (CoT) reasoning process can enhance explainability and scene understanding. However, such a popular strategy proves to suffer from the notorious problems of misalignment between the crafted CoTs against the consequent decision-making, which remains untouched by previous LLM-based AD methods. To address this problem, we motivate an end-to-end decision-making model based on multimodality-augmented LLM, which simultaneously executes CoT reasoning and carries out planning results. Furthermore, we propose a reasoning-decision alignment constraint between the paired CoTs and planning results, imposing the correspondence between reasoning and decision-making. Moreover, we redesign the CoTs to enable the model to comprehend complex scenarios and enhance decision-making performance. We dub our proposed large language planners with reasoning-decision alignment as RDA-Driver. Experimental evaluations on the nuScenes and DriveLM-nuScenes benchmarks demonstrate the effectiveness of our RDA-Driver in enhancing the performance of end-to-end AD systems. Specifically, our RDA-Driver achieves state-of-the-art planning performance on the nuScenes dataset with 0.80 L2 error and 0.32 collision rate, and also achieves leading results on challenging DriveLM-nuScenes benchmarks with 0.82 L2 error and 0.38 collision rate.
MindBench: A Comprehensive Benchmark for Mind Map Structure Recognition and Analysis
Jul 03, 2024Multimodal Large Language Models (MLLM) have made significant progress in the field of document analysis. Despite this, existing benchmarks typically focus only on extracting text and simple layout information, neglecting the complex interactions between elements in structured documents such as mind maps and flowcharts. To address this issue, we introduce the new benchmark named MindBench, which not only includes meticulously constructed bilingual authentic or synthetic images, detailed annotations, evaluation metrics and baseline models, but also specifically designs five types of structured understanding and parsing tasks. These tasks include full parsing, partial parsing, position-related parsing, structured Visual Question Answering (VQA), and position-related VQA, covering key areas such as text recognition, spatial awareness, relationship discernment, and structured parsing. Extensive experimental results demonstrate the substantial potential and significant room for improvement in current models' ability to handle structured document information. We anticipate that the launch of MindBench will significantly advance research and application development in structured document analysis technology. MindBench is available at: https://miasanlei.github.io/MindBench.github.io/.