 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventHallusion: Diagnosing Event Hallucinations in Video LLMs
Paper and Code

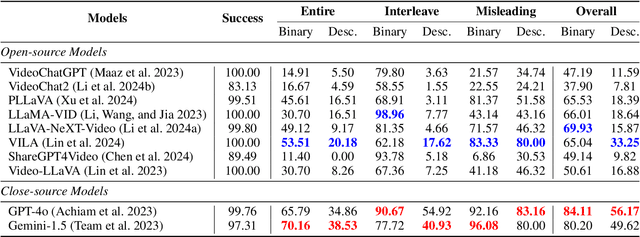

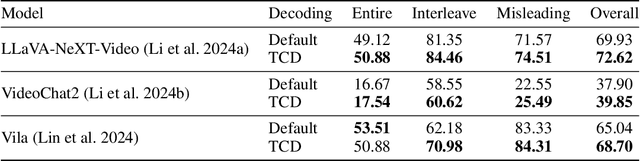
Recently, Multimodal Large Language Models (MLLMs) have made significant progress in the video comprehension field. Despite remarkable content reasoning and instruction following capabilities they demonstrated, the hallucination problem of these VideoLLMs is less explored compared with its counterpart in the image domain. To mitigate this gap, we first propose EventHallusion, a novel benchmark that focuses on assessing the VideoLMMs' hallucination phenomenon on video event comprehension. Based on the observation that existing VideoLLMs are entangled with the priors stemming from their foundation models, our EventHallusion is curated by meticulously collecting videos and annotating questions to intentionally mislead the VideoLLMs into interpreting events based on these priors rather than accurately understanding the video content. On the other hand, we also propose a simple yet effective method, called Temporal Contrastive Decoding (TCD), to tackle the hallucination problems of VideoLLMs. The proposed TCD suppresses the model's preference toward their priors by comparing the original video with a constructed counterpart, whose temporal cues are disrupted, during the autoregressive decoding stage. Through comprehensive evaluation of eight open-source and two closed-source VideoLLMs on the proposed EventHallusion benchmark, we find that the open-source models suffer significantly from hallucination problems, whereas the closed-source models perform markedly better. By further equipping open-sourced VideoLLMs with the proposed TCD approach, evident performance improvements are achieved across most metrics in the EventHallusion benchmark. Our codes and benchmark data are available at https://github.com/Stevetich/EventHallusion.