 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOVA: Towards Scalable and Synchronized Video-Audio Generation
Feb 09, 2026Audio is indispensable for real-world video, yet generation models have largely overlooked audio components. Current approaches to producing audio-visual content often rely on cascaded pipelines, which increase cost, accumulate errors, and degrade overall quality. While systems such as Veo 3 and Sora 2 emphasize the value of simultaneous generation, joint multimodal modeling introduces unique challenges in architecture, data, and training. Moreover, the closed-source nature of existing systems limits progress in the field. In this work, we introduce MOVA (MOSS Video and Audio), an open-source model capable of generating high-quality, synchronized audio-visual content, including realistic lip-synced speech, environment-aware sound effects, and content-aligned music. MOVA employs a Mixture-of-Experts (MoE) architecture, with a total of 32B parameters, of which 18B are active during inference. It supports IT2VA (Image-Text to Video-Audio) generation task. By releasing the model weights and code, we aim to advance research and foster a vibrant community of creators. The released codebase features comprehensive support for efficient inference, LoRA fine-tuning, and prompt enhancement.
VizDefender: Unmasking Visualization Tampering through Proactive Localization and Intent Inference
Dec 21, 2025
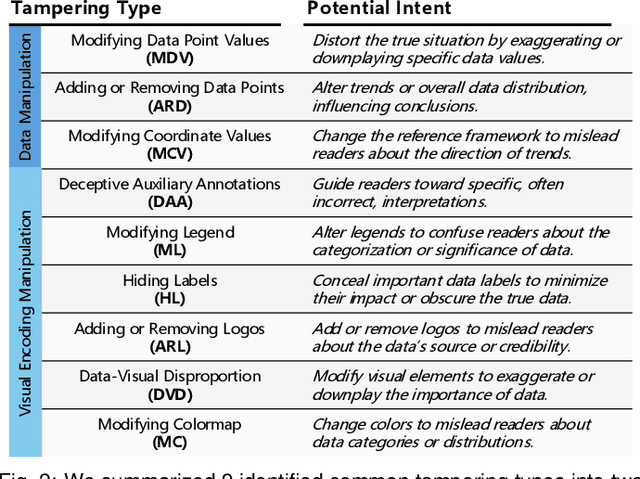
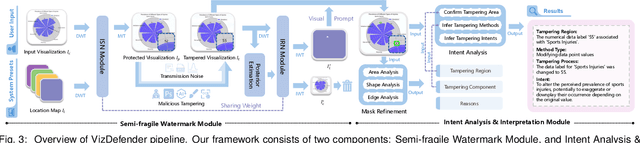
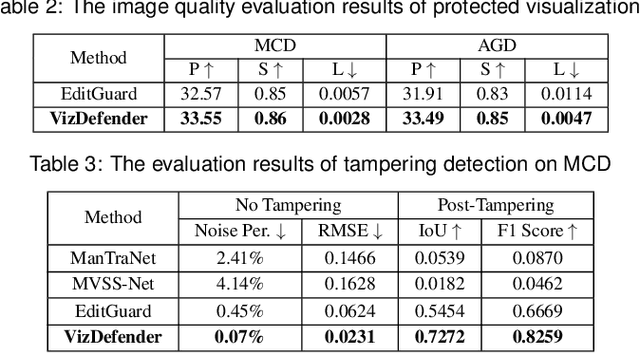
The integrity of data visualizations is increasingly threatened by image editing techniques that enable subtle yet deceptive tampering. Through a formative study, we define this challenge and categorize tampering techniques into two primary types: data manipulation and visual encoding manipulation. To address this, we present VizDefender, a framework for tampering detection and analysis. The framework integrates two core components: 1) a semi-fragile watermark module that protects the visualization by embedding a location map to images, which allows for the precise localization of tampered regions while preserving visual quality, and 2) an intent analysis module that leverages Multimodal Large Language Models (MLLMs) to interpret manipulation, inferring the attacker's intent and misleading effects. Extensive evaluations and user studies demonstrate the effectiveness of our methods.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
MPJudge: Towards Perceptual Assessment of Music-Induced Paintings
Nov 10, 2025Music induced painting is a unique artistic practice, where visual artworks are created under the influence of music. Evaluating whether a painting faithfully reflects the music that inspired it poses a challenging perceptual assessment task. Existing methods primarily rely on emotion recognition models to assess the similarity between music and painting, but such models introduce considerable noise and overlook broader perceptual cues beyond emotion. To address these limitations, we propose a novel framework for music induced painting assessment that directly models perceptual coherence between music and visual art. We introduce MPD, the first large scale dataset of music painting pairs annotated by domain experts based on perceptual coherence. To better handle ambiguous cases, we further collect pairwise preference annotations. Building on this dataset, we present MPJudge, a model that integrates music features into a visual encoder via a modulation based fusion mechanism. To effectively learn from ambiguous cases, we adopt Direct Preference Optimization for training. Extensive experiments demonstrate that our method outperforms existing approaches. Qualitative results further show that our model more accurately identifies music relevant regions in paintings.
IFDECORATOR: Wrapping Instruction Following Reinforcement Learning with Verifiable Rewards
Aug 06, 2025Reinforcement Learning with Verifiable Rewards (RLVR) improves instruction following capabilities of large language models (LLMs), but suffers from training inefficiency due to inadequate difficulty assessment. Moreover, RLVR is prone to over-optimization, where LLMs exploit verification shortcuts without aligning to the actual intent of user instructions. We introduce Instruction Following Decorator (IFDecorator}, a framework that wraps RLVR training into a robust and sample-efficient pipeline. It consists of three components: (1) a cooperative-adversarial data flywheel that co-evolves instructions and hybrid verifications, generating progressively more challenging instruction-verification pairs; (2) IntentCheck, a bypass module enforcing intent alignment; and (3) trip wires, a diagnostic mechanism that detects reward hacking via trap instructions, which trigger and capture shortcut exploitation behaviors. Our Qwen2.5-32B-Instruct-IFDecorator achieves 87.43% accuracy on IFEval, outperforming larger proprietary models such as GPT-4o. Additionally, we demonstrate substantial improvements on FollowBench while preserving general capabilities. Our trip wires show significant reductions in reward hacking rates. We will release models, code, and data for future research.
Scientists' First Exam: Probing Cognitive Abilities of MLLM via Perception, Understanding, and Reasoning
Jun 12, 2025Scientific discoveries increasingly rely on complex multimodal reasoning based on information-intensive scientific data and domain-specific expertise. Empowered by expert-level scientific benchmarks, scientific Multimodal Large Language Models (MLLMs) hold the potential to significantly enhance this discovery process in realistic workflows. However, current scientific benchmarks mostly focus on evaluating the knowledge understanding capabilities of MLLMs, leading to an inadequate assessment of their perception and reasoning abilities. To address this gap, we present the Scientists' First Exam (SFE) benchmark, designed to evaluate the scientific cognitive capacities of MLLMs through three interconnected levels: scientific signal perception, scientific attribute understanding, scientific comparative reasoning. Specifically, SFE comprises 830 expert-verified VQA pairs across three question types, spanning 66 multimodal tasks across five high-value disciplines. Extensive experiments reveal that current state-of-the-art GPT-o3 and InternVL-3 achieve only 34.08% and 26.52% on SFE, highlighting significant room for MLLMs to improve in scientific realms. We hope the insights obtained in SFE will facilitate further developments in AI-enhanced scientific discoveries.
Consensus Entropy: Harnessing Multi-VLM Agreement for Self-Verifying and Self-Improving OCR
Apr 16, 2025



The Optical Character Recognition (OCR) task is important for evaluating Vision-Language Models (VLMs) and providing high-quality data sources for LLM training data. While state-of-the-art VLMs show improved average OCR accuracy, they still struggle with sample-level quality degradation and lack reliable automatic detection of low-quality outputs. We introduce Consensus Entropy (CE), a training-free post-inference method that quantifies OCR uncertainty by aggregating outputs from multiple VLMs. Our approach exploits a key insight: correct VLM OCR predictions converge in output space while errors diverge. We develop a lightweight multi-model framework that effectively identifies problematic samples, selects the best outputs and combines model strengths. Experiments across multiple OCR benchmarks and VLMs demonstrate that CE outperforms VLM-as-judge approaches and single-model baselines at the same cost and achieves state-of-the-art results across multiple metrics. For instance, our solution demonstrates: achieving 15.2% higher F1 scores than VLM-as-judge methods in quality verification, delivering 6.0% accuracy gains on mathematical calculation tasks, and requiring rephrasing only 7.3% of inputs while maintaining overall performance. Notably, the entire process requires neither training nor supervision while maintaining plug-and-play functionality throughout.
OpenFly: A Versatile Toolchain and Large-scale Benchmark for Aerial Vision-Language Navigation
Feb 25, 2025Vision-Language Navigation (VLN) aims to guide agents through an environment by leveraging both language instructions and visual cues, playing a pivotal role in embodied AI. Indoor VLN has been extensively studied, whereas outdoor aerial VLN remains underexplored. The potential reason is that outdoor aerial view encompasses vast areas, making data collection more challenging, which results in a lack of benchmarks. To address this problem, we propose OpenFly, a platform comprising a versatile toolchain and large-scale benchmark for aerial VLN. Firstly, we develop a highly automated toolchain for data collection, enabling automatic point cloud acquisition, scene semantic segmentation, flight trajectory creation, and instruction generation. Secondly, based on the toolchain, we construct a large-scale aerial VLN dataset with 100k trajectories, covering diverse heights and lengths across 18 scenes. The corresponding visual data are generated using various rendering engines and advanced techniques, including Unreal Engine, GTA V, Google Earth, and 3D Gaussian Splatting (3D GS). All data exhibit high visual quality. Particularly, 3D GS supports real-to-sim rendering, further enhancing the realism of the dataset. Thirdly, we propose OpenFly-Agent, a keyframe-aware VLN model, which takes language instructions, current observations, and historical keyframes as input, and outputs flight actions directly. Extensive analyses and experiments are conducted, showcasing the superiority of our OpenFly platform and OpenFly-Agent. The toolchain, dataset, and codes will be open-sourced.
Open-Vocabulary Octree-Graph for 3D Scene Understanding
Nov 25, 2024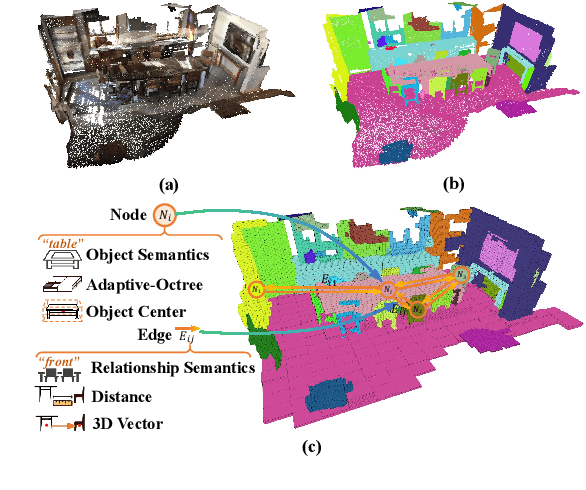
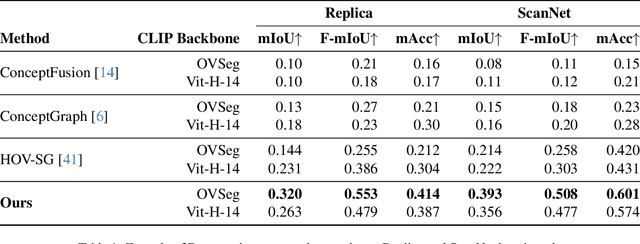
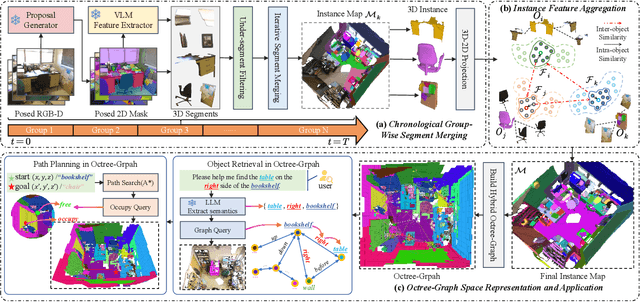
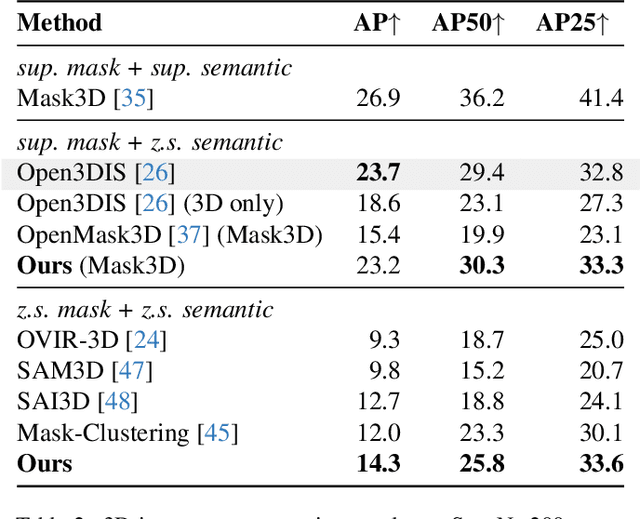
Open-vocabulary 3D scene understanding is indispensable for embodied agents. Recent works leverage pretrained vision-language models (VLMs) for object segmentation and project them to point clouds to build 3D maps. Despite progress, a point cloud is a set of unordered coordinates that requires substantial storage space and does not directly convey occupancy information or spatial relation, making existing methods inefficient for downstream tasks, e.g., path planning and complex text-based object retrieval. To address these issues, we propose Octree-Graph, a novel scene representation for open-vocabulary 3D scene understanding. Specifically, a Chronological Group-wise Segment Merging (CGSM) strategy and an Instance Feature Aggregation (IFA) algorithm are first designed to get 3D instances and corresponding semantic features. Subsequently, an adaptive-octree structure is developed that stores semantics and depicts the occupancy of an object adjustably according to its shape. Finally, the Octree-Graph is constructed where each adaptive-octree acts as a graph node, and edges describe the spatial relations among nodes. Extensive experiments on various tasks are conducted on several widely-used datasets, demonstrating the versatility and effectiveness of our method.
ChatTracker: Enhancing Visual Tracking Performance via Chatting with Multimodal Large Language Model
Nov 04, 2024



Visual object tracking aims to locate a targeted object in a video sequence based on an initial bounding box. Recently, Vision-Language~(VL) trackers have proposed to utilize additional natural language descriptions to enhance versatility in various applications. However, VL trackers are still inferior to State-of-The-Art (SoTA) visual trackers in terms of tracking performance. We found that this inferiority primarily results from their heavy reliance on manual textual annotations, which include the frequent provision of ambiguous language descriptions. In this paper, we propose ChatTracker to leverage the wealth of world knowledge in the Multimodal Large Language Model (MLLM) to generate high-quality language descriptions and enhance tracking performance. To this end, we propose a novel reflection-based prompt optimization module to iteratively refine the ambiguous and inaccurate descriptions of the target with tracking feedback. To further utilize semantic information produced by MLLM, a simple yet effective VL tracking framework is proposed and can be easily integrated as a plug-and-play module to boost the performance of both VL and visual trackers. Experimental results show that our proposed ChatTracker achieves a performance comparable to existing methods.