 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourierSampler: Unlocking Non-Autoregressive Potential in Diffusion Language Models via Frequency-Guided Generation
Jan 30, 2026Despite the non-autoregressive potential of diffusion language models (dLLMs), existing decoding strategies demonstrate positional bias, failing to fully unlock the potential of arbitrary generation. In this work, we delve into the inherent spectral characteristics of dLLMs and present the first frequency-domain analysis showing that low-frequency components in hidden states primarily encode global structural information and long-range dependencies, while high-frequency components are responsible for characterizing local details. Based on this observation, we propose FourierSampler, which leverages a frequency-domain sliding window mechanism to dynamically guide the model to achieve a "structure-to-detail" generation. FourierSampler outperforms other inference enhancement strategies on LLADA and SDAR, achieving relative improvements of 20.4% on LLaDA1.5-8B and 16.0% on LLaDA-8B-Instruct. It notably surpasses similarly sized autoregressive models like Llama3.1-8B-Instruct.
DiRL: An Efficient Post-Training Framework for Diffusion Language Models
Dec 23, 2025Diffusion Language Models (dLLMs) have emerged as promising alternatives to Auto-Regressive (AR) models. While recent efforts have validated their pre-training potential and accelerated inference speeds, the post-training landscape for dLLMs remains underdeveloped. Existing methods suffer from computational inefficiency and objective mismatches between training and inference, severely limiting performance on complex reasoning tasks such as mathematics. To address this, we introduce DiRL, an efficient post-training framework that tightly integrates FlexAttention-accelerated blockwise training with LMDeploy-optimized inference. This architecture enables a streamlined online model update loop, facilitating efficient two-stage post-training (Supervised Fine-Tuning followed by Reinforcement Learning). Building on this framework, we propose DiPO, the first unbiased Group Relative Policy Optimization (GRPO) implementation tailored for dLLMs. We validate our approach by training DiRL-8B-Instruct on high-quality math data. Our model achieves state-of-the-art math performance among dLLMs and surpasses comparable models in the Qwen2.5 series on several benchmarks.
MPJudge: Towards Perceptual Assessment of Music-Induced Paintings
Nov 10, 2025Music induced painting is a unique artistic practice, where visual artworks are created under the influence of music. Evaluating whether a painting faithfully reflects the music that inspired it poses a challenging perceptual assessment task. Existing methods primarily rely on emotion recognition models to assess the similarity between music and painting, but such models introduce considerable noise and overlook broader perceptual cues beyond emotion. To address these limitations, we propose a novel framework for music induced painting assessment that directly models perceptual coherence between music and visual art. We introduce MPD, the first large scale dataset of music painting pairs annotated by domain experts based on perceptual coherence. To better handle ambiguous cases, we further collect pairwise preference annotations. Building on this dataset, we present MPJudge, a model that integrates music features into a visual encoder via a modulation based fusion mechanism. To effectively learn from ambiguous cases, we adopt Direct Preference Optimization for training. Extensive experiments demonstrate that our method outperforms existing approaches. Qualitative results further show that our model more accurately identifies music relevant regions in paintings.
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Nov 06, 2025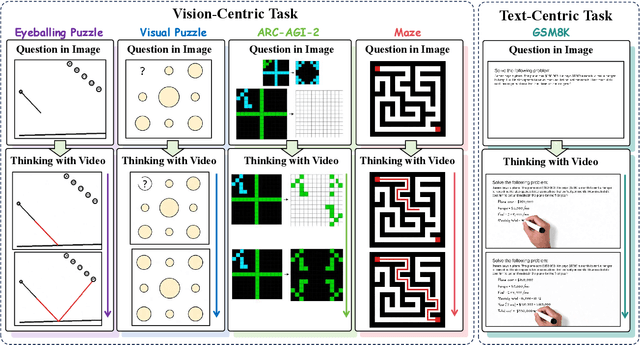
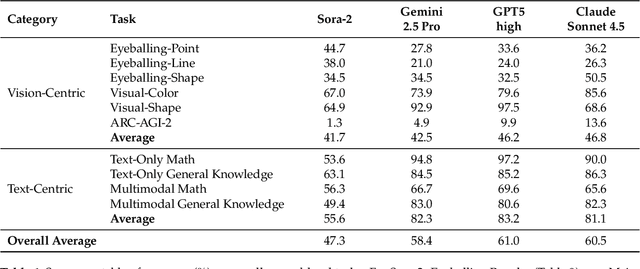
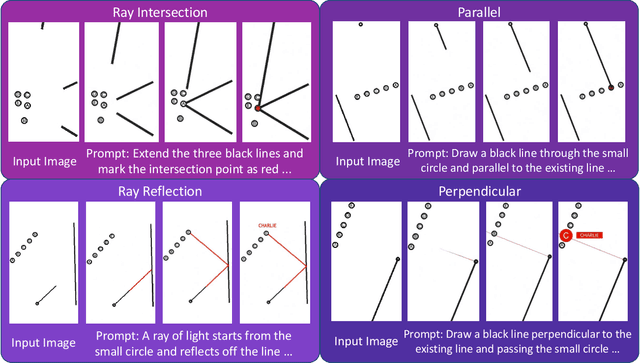
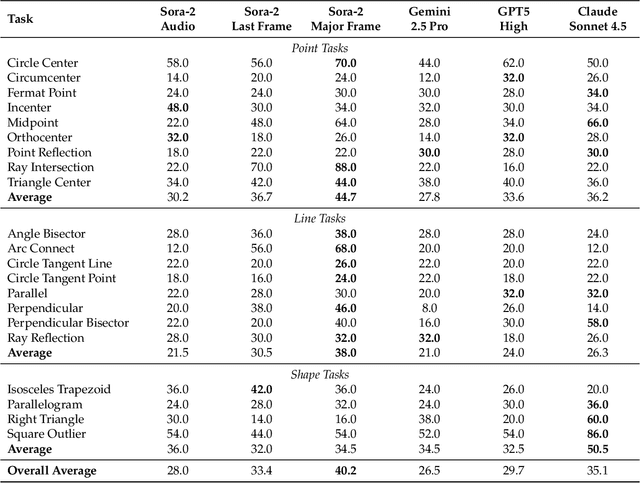
"Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of large language models (LLMs) and Vision Language Models (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU). Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Games. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 75.53% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2's performance. In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positions "thinking with video" as a unified multimodal reasoning paradigm.
IFDECORATOR: Wrapping Instruction Following Reinforcement Learning with Verifiable Rewards
Aug 06, 2025Reinforcement Learning with Verifiable Rewards (RLVR) improves instruction following capabilities of large language models (LLMs), but suffers from training inefficiency due to inadequate difficulty assessment. Moreover, RLVR is prone to over-optimization, where LLMs exploit verification shortcuts without aligning to the actual intent of user instructions. We introduce Instruction Following Decorator (IFDecorator}, a framework that wraps RLVR training into a robust and sample-efficient pipeline. It consists of three components: (1) a cooperative-adversarial data flywheel that co-evolves instructions and hybrid verifications, generating progressively more challenging instruction-verification pairs; (2) IntentCheck, a bypass module enforcing intent alignment; and (3) trip wires, a diagnostic mechanism that detects reward hacking via trap instructions, which trigger and capture shortcut exploitation behaviors. Our Qwen2.5-32B-Instruct-IFDecorator achieves 87.43% accuracy on IFEval, outperforming larger proprietary models such as GPT-4o. Additionally, we demonstrate substantial improvements on FollowBench while preserving general capabilities. Our trip wires show significant reductions in reward hacking rates. We will release models, code, and data for future research.
RouteWinFormer: A Route-Window Transformer for Middle-range Attention in Image Restoration
Apr 23, 2025Transformer models have recently garnered significant attention in image restoration due to their ability to capture long-range pixel dependencies. However, long-range attention often results in computational overhead without practical necessity, as degradation and context are typically localized. Normalized average attention distance across various degradation datasets shows that middle-range attention is enough for image restoration. Building on this insight, we propose RouteWinFormer, a novel window-based Transformer that models middle-range context for image restoration. RouteWinFormer incorporates Route-Windows Attnetion Module, which dynamically selects relevant nearby windows based on regional similarity for attention aggregation, extending the receptive field to a mid-range size efficiently. In addition, we introduce Multi-Scale Structure Regularization during training, enabling the sub-scale of the U-shaped network to focus on structural information, while the original-scale learns degradation patterns based on generalized image structure priors. Extensive experiments demonstrate that RouteWinFormer outperforms state-of-the-art methods across 9 datasets in various image restoration tasks.
Consensus Entropy: Harnessing Multi-VLM Agreement for Self-Verifying and Self-Improving OCR
Apr 16, 2025



The Optical Character Recognition (OCR) task is important for evaluating Vision-Language Models (VLMs) and providing high-quality data sources for LLM training data. While state-of-the-art VLMs show improved average OCR accuracy, they still struggle with sample-level quality degradation and lack reliable automatic detection of low-quality outputs. We introduce Consensus Entropy (CE), a training-free post-inference method that quantifies OCR uncertainty by aggregating outputs from multiple VLMs. Our approach exploits a key insight: correct VLM OCR predictions converge in output space while errors diverge. We develop a lightweight multi-model framework that effectively identifies problematic samples, selects the best outputs and combines model strengths. Experiments across multiple OCR benchmarks and VLMs demonstrate that CE outperforms VLM-as-judge approaches and single-model baselines at the same cost and achieves state-of-the-art results across multiple metrics. For instance, our solution demonstrates: achieving 15.2% higher F1 scores than VLM-as-judge methods in quality verification, delivering 6.0% accuracy gains on mathematical calculation tasks, and requiring rephrasing only 7.3% of inputs while maintaining overall performance. Notably, the entire process requires neither training nor supervision while maintaining plug-and-play functionality throughout.
CritiQ: Mining Data Quality Criteria from Human Preferences
Feb 26, 2025Language model heavily depends on high-quality data for optimal performance. Existing approaches rely on manually designed heuristics, the perplexity of existing models, training classifiers, or careful prompt engineering, which require significant expert experience and human annotation effort while introduce biases. We introduce CritiQ, a novel data selection method that automatically mines criteria from human preferences for data quality with only $\sim$30 human-annotated pairs and performs efficient data selection. The main component, CritiQ Flow, employs a manager agent to evolve quality criteria and worker agents to make pairwise judgments. We build a knowledge base that extracts quality criteria from previous work to boost CritiQ Flow. Compared to perplexity- and classifier- based methods, verbal criteria are more interpretable and possess reusable value. After deriving the criteria, we train the CritiQ Scorer to give quality scores and perform efficient data selection. We demonstrate the effectiveness of our method in the code, math, and logic domains, achieving high accuracy on human-annotated test sets. To validate the quality of the selected data, we continually train Llama 3.1 models and observe improved performance on downstream tasks compared to uniform sampling. Ablation studies validate the benefits of the knowledge base and the reflection process. We analyze how criteria evolve and the effectiveness of majority voting.
GAOKAO-Eval: Does high scores truly reflect strong capabilities in LLMs?
Dec 13, 2024Large Language Models (LLMs) are commonly evaluated using human-crafted benchmarks, under the premise that higher scores implicitly reflect stronger human-like performance. However, there is growing concern that LLMs may ``game" these benchmarks due to data leakage, achieving high scores while struggling with tasks simple for humans. To substantively address the problem, we create GAOKAO-Eval, a comprehensive benchmark based on China's National College Entrance Examination (Gaokao), and conduct ``closed-book" evaluations for representative models released prior to Gaokao. Contrary to prevailing consensus, even after addressing data leakage and comprehensiveness, GAOKAO-Eval reveals that high scores still fail to truly reflect human-aligned capabilities. To better understand this mismatch, We introduce the Rasch model from cognitive psychology to analyze LLM scoring patterns and identify two key discrepancies: 1) anomalous consistent performance across various question difficulties, and 2) high variance in performance on questions of similar difficulty. In addition, We identified inconsistent grading of LLM-generated answers among teachers and recurring mistake patterns. we find that the phenomenons are well-grounded in the motivations behind OpenAI o1, and o1's reasoning-as-difficulties can mitigate the mismatch. These results show that GAOKAO-Eval can reveal limitations in LLM capabilities not captured by current benchmarks and highlight the need for more LLM-aligned difficulty analysis.
TextCenGen: Attention-Guided Text-Centric Background Adaptation for Text-to-Image Generation
Apr 18, 2024Recent advancements in Text-to-image (T2I) generation have witnessed a shift from adapting text to fixed backgrounds to creating images around text. Traditional approaches are often limited to generate layouts within static images for effective text placement. Our proposed approach, TextCenGen, introduces a dynamic adaptation of the blank region for text-friendly image generation, emphasizing text-centric design and visual harmony generation. Our method employs force-directed attention guidance in T2I models to generate images that strategically reserve whitespace for pre-defined text areas, even for text or icons at the golden ratio. Observing how cross-attention maps affect object placement, we detect and repel conflicting objects using a force-directed graph approach, combined with a Spatial Excluding Cross-Attention Constraint for smooth attention in whitespace areas. As a novel task in graphic design, experiments indicate that TextCenGen outperforms existing methods with more harmonious compositions. Furthermore, our method significantly enhances T2I model outcomes on our specially collected prompt datasets, catering to varied text positions. These results demonstrate the efficacy of TextCenGen in creating more harmonious and integrated text-image compositions.