 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRT: Learning Compact Representations with Mixed RWKV-Transformer for Extreme Image Compression
Nov 14, 2025Recent advances in extreme image compression have revealed that mapping pixel data into highly compact latent representations can significantly improve coding efficiency. However, most existing methods compress images into 2-D latent spaces via convolutional neural networks (CNNs) or Swin Transformers, which tend to retain substantial spatial redundancy, thereby limiting overall compression performance. In this paper, we propose a novel Mixed RWKV-Transformer (MRT) architecture that encodes images into more compact 1-D latent representations by synergistically integrating the complementary strengths of linear-attention-based RWKV and self-attention-based Transformer models. Specifically, MRT partitions each image into fixed-size windows, utilizing RWKV modules to capture global dependencies across windows and Transformer blocks to model local redundancies within each window. The hierarchical attention mechanism enables more efficient and compact representation learning in the 1-D domain. To further enhance compression efficiency, we introduce a dedicated RWKV Compression Model (RCM) tailored to the structure characteristics of the intermediate 1-D latent features in MRT. Extensive experiments on standard image compression benchmarks validate the effectiveness of our approach. The proposed MRT framework consistently achieves superior reconstruction quality at bitrates below 0.02 bits per pixel (bpp). Quantitative results based on the DISTS metric show that MRT significantly outperforms the state-of-the-art 2-D architecture GLC, achieving bitrate savings of 43.75%, 30.59% on the Kodak and CLIC2020 test datasets, respectively.
An End-to-End Room Geometry Constrained Depth Estimation Framework for Indoor Panorama Images
Oct 09, 2025Predicting spherical pixel depth from monocular $360^{\circ}$ indoor panoramas is critical for many vision applications. However, existing methods focus on pixel-level accuracy, causing oversmoothed room corners and noise sensitivity. In this paper, we propose a depth estimation framework based on room geometry constraints, which extracts room geometry information through layout prediction and integrates those information into the depth estimation process through background segmentation mechanism. At the model level, our framework comprises a shared feature encoder followed by task-specific decoders for layout estimation, depth estimation, and background segmentation. The shared encoder extracts multi-scale features, which are subsequently processed by individual decoders to generate initial predictions: a depth map, a room layout map, and a background segmentation map. Furthermore, our framework incorporates two strategies: a room geometry-based background depth resolving strategy and a background-segmentation-guided fusion mechanism. The proposed room-geometry-based background depth resolving strategy leverages the room layout and the depth decoder's output to generate the corresponding background depth map. Then, a background-segmentation-guided fusion strategy derives fusion weights for the background and coarse depth maps from the segmentation decoder's predictions. Extensive experimental results on the Stanford2D3D, Matterport3D and Structured3D datasets show that our proposed methods can achieve significantly superior performance than current open-source methods. Our code is available at https://github.com/emiyaning/RGCNet.
Region-Level Context-Aware Multimodal Understanding
Aug 17, 2025Despite significant progress, existing research on Multimodal Large Language Models (MLLMs) mainly focuses on general visual understanding, overlooking the ability to integrate textual context associated with objects for a more context-aware multimodal understanding -- an ability we refer to as Region-level Context-aware Multimodal Understanding (RCMU). To address this limitation, we first formulate the RCMU task, which requires models to respond to user instructions by integrating both image content and textual information of regions or objects. To equip MLLMs with RCMU capabilities, we propose Region-level Context-aware Visual Instruction Tuning (RCVIT), which incorporates object information into the model input and enables the model to utilize bounding box coordinates to effectively associate objects' visual content with their textual information. To address the lack of datasets, we introduce the RCMU dataset, a large-scale visual instruction tuning dataset that covers multiple RCMU tasks. We also propose RC\&P-Bench, a comprehensive benchmark that can evaluate the performance of MLLMs in RCMU and multimodal personalized understanding tasks. Additionally, we propose a reference-free evaluation metric to perform a comprehensive and fine-grained evaluation of the region-level context-aware image descriptions. By performing RCVIT on Qwen2-VL models with the RCMU dataset, we developed RC-Qwen2-VL models. Experimental results indicate that RC-Qwen2-VL models not only achieve outstanding performance on multiple RCMU tasks but also demonstrate successful applications in multimodal RAG and personalized conversation. Our data, model and benchmark are available at https://github.com/hongliang-wei/RC-MLLM
T-GVC: Trajectory-Guided Generative Video Coding at Ultra-Low Bitrates
Jul 10, 2025



Recent advances in video generation techniques have given rise to an emerging paradigm of generative video coding, aiming to achieve semantically accurate reconstructions in Ultra-Low Bitrate (ULB) scenarios by leveraging strong generative priors. However, most existing methods are limited by domain specificity (e.g., facial or human videos) or an excessive dependence on high-level text guidance, which often fails to capture motion details and results in unrealistic reconstructions. To address these challenges, we propose a Trajectory-Guided Generative Video Coding framework (dubbed T-GVC). T-GVC employs a semantic-aware sparse motion sampling pipeline to effectively bridge low-level motion tracking with high-level semantic understanding by extracting pixel-wise motion as sparse trajectory points based on their semantic importance, not only significantly reducing the bitrate but also preserving critical temporal semantic information. In addition, by incorporating trajectory-aligned loss constraints into diffusion processes, we introduce a training-free latent space guidance mechanism to ensure physically plausible motion patterns without sacrificing the inherent capabilities of generative models. Experimental results demonstrate that our framework outperforms both traditional codecs and state-of-the-art end-to-end video compression methods under ULB conditions. Furthermore, additional experiments confirm that our approach achieves more precise motion control than existing text-guided methods, paving the way for a novel direction of generative video coding guided by geometric motion modeling.
Multi-Timescale Motion-Decoupled Spiking Transformer for Audio-Visual Zero-Shot Learning
May 26, 2025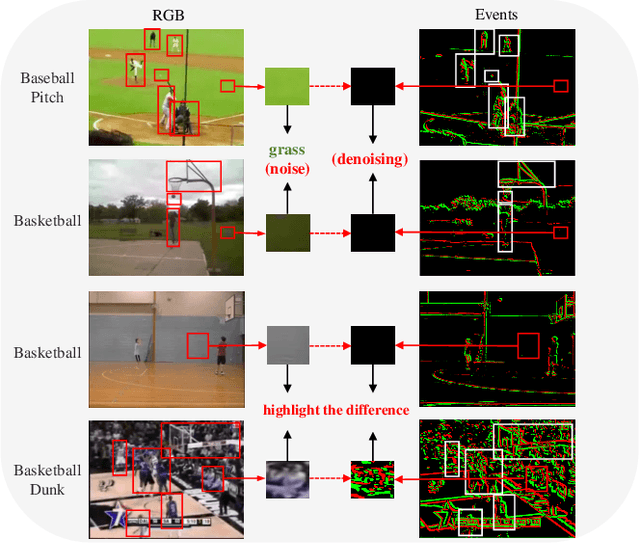



Audio-visual zero-shot learning (ZSL) has been extensively researched for its capability to classify video data from unseen classes during training. Nevertheless, current methodologies often struggle with background scene biases and inadequate motion detail. This paper proposes a novel dual-stream Multi-Timescale Motion-Decoupled Spiking Transformer (MDST++), which decouples contextual semantic information and sparse dynamic motion information. The recurrent joint learning unit is proposed to extract contextual semantic information and capture joint knowledge across various modalities to understand the environment of actions. By converting RGB images to events, our method captures motion information more accurately and mitigates background scene biases. Moreover, we introduce a discrepancy analysis block to model audio motion information. To enhance the robustness of SNNs in extracting temporal and motion cues, we dynamically adjust the threshold of Leaky Integrate-and-Fire neurons based on global motion and contextual semantic information. Our experiments validate the effectiveness of MDST++, demonstrating their consistent superiority over state-of-the-art methods on mainstream benchmarks. Additionally, incorporating motion and multi-timescale information significantly improves HM and ZSL accuracy by 26.2\% and 39.9\%.
RouteWinFormer: A Route-Window Transformer for Middle-range Attention in Image Restoration
Apr 23, 2025Transformer models have recently garnered significant attention in image restoration due to their ability to capture long-range pixel dependencies. However, long-range attention often results in computational overhead without practical necessity, as degradation and context are typically localized. Normalized average attention distance across various degradation datasets shows that middle-range attention is enough for image restoration. Building on this insight, we propose RouteWinFormer, a novel window-based Transformer that models middle-range context for image restoration. RouteWinFormer incorporates Route-Windows Attnetion Module, which dynamically selects relevant nearby windows based on regional similarity for attention aggregation, extending the receptive field to a mid-range size efficiently. In addition, we introduce Multi-Scale Structure Regularization during training, enabling the sub-scale of the U-shaped network to focus on structural information, while the original-scale learns degradation patterns based on generalized image structure priors. Extensive experiments demonstrate that RouteWinFormer outperforms state-of-the-art methods across 9 datasets in various image restoration tasks.
FLAM: Foundation Model-Based Body Stabilization for Humanoid Locomotion and Manipulation
Mar 28, 2025Humanoid robots have attracted significant attention in recent years. Reinforcement Learning (RL) is one of the main ways to control the whole body of humanoid robots. RL enables agents to complete tasks by learning from environment interactions, guided by task rewards. However, existing RL methods rarely explicitly consider the impact of body stability on humanoid locomotion and manipulation. Achieving high performance in whole-body control remains a challenge for RL methods that rely solely on task rewards. In this paper, we propose a Foundation model-based method for humanoid Locomotion And Manipulation (FLAM for short). FLAM integrates a stabilizing reward function with a basic policy. The stabilizing reward function is designed to encourage the robot to learn stable postures, thereby accelerating the learning process and facilitating task completion. Specifically, the robot pose is first mapped to the 3D virtual human model. Then, the human pose is stabilized and reconstructed through a human motion reconstruction model. Finally, the pose before and after reconstruction is used to compute the stabilizing reward. By combining this stabilizing reward with the task reward, FLAM effectively guides policy learning. Experimental results on a humanoid robot benchmark demonstrate that FLAM outperforms state-of-the-art RL methods, highlighting its effectiveness in improving stability and overall performance.
Hyperbolic-constraint Point Cloud Reconstruction from Single RGB-D Images
Dec 12, 2024Reconstructing desired objects and scenes has long been a primary goal in 3D computer vision. Single-view point cloud reconstruction has become a popular technique due to its low cost and accurate results. However, single-view reconstruction methods often rely on expensive CAD models and complex geometric priors. Effectively utilizing prior knowledge about the data remains a challenge. In this paper, we introduce hyperbolic space to 3D point cloud reconstruction, enabling the model to represent and understand complex hierarchical structures in point clouds with low distortion. We build upon previous methods by proposing a hyperbolic Chamfer distance and a regularized triplet loss to enhance the relationship between partial and complete point clouds. Additionally, we design adaptive boundary conditions to improve the model's understanding and reconstruction of 3D structures. Our model outperforms most existing models, and ablation studies demonstrate the significance of our model and its components. Experimental results show that our method significantly improves feature extraction capabilities. Our model achieves outstanding performance in 3D reconstruction tasks.
Digging into Intrinsic Contextual Information for High-fidelity 3D Point Cloud Completion
Dec 11, 2024



The common occurrence of occlusion-induced incompleteness in point clouds has made point cloud completion (PCC) a highly-concerned task in the field of geometric processing. Existing PCC methods typically produce complete point clouds from partial point clouds in a coarse-to-fine paradigm, with the coarse stage generating entire shapes and the fine stage improving texture details. Though diffusion models have demonstrated effectiveness in the coarse stage, the fine stage still faces challenges in producing high-fidelity results due to the ill-posed nature of PCC. The intrinsic contextual information for texture details in partial point clouds is the key to solving the challenge. In this paper, we propose a high-fidelity PCC method that digs into both short and long-range contextual information from the partial point cloud in the fine stage. Specifically, after generating the coarse point cloud via a diffusion-based coarse generator, a mixed sampling module introduces short-range contextual information from partial point clouds into the fine stage. A surface freezing modules safeguards points from noise-free partial point clouds against disruption. As for the long-range contextual information, we design a similarity modeling module to derive similarity with rigid transformation invariance between points, conducting effective matching of geometric manifold features globally. In this way, the high-quality components present in the partial point cloud serve as valuable references for refining the coarse point cloud with high fidelity. Extensive experiments have demonstrated the superiority of the proposed method over SOTA competitors. Our code is available at https://github.com/JS-CHU/ContextualCompletion.
SceneDreamer360: Text-Driven 3D-Consistent Scene Generation with Panoramic Gaussian Splatting
Aug 25, 2024



Text-driven 3D scene generation has seen significant advancements recently. However, most existing methods generate single-view images using generative models and then stitch them together in 3D space. This independent generation for each view often results in spatial inconsistency and implausibility in the 3D scenes. To address this challenge, we proposed a novel text-driven 3D-consistent scene generation model: SceneDreamer360. Our proposed method leverages a text-driven panoramic image generation model as a prior for 3D scene generation and employs 3D Gaussian Splatting (3DGS) to ensure consistency across multi-view panoramic images. Specifically, SceneDreamer360 enhances the fine-tuned Panfusion generator with a three-stage panoramic enhancement, enabling the generation of high-resolution, detail-rich panoramic images. During the 3D scene construction, a novel point cloud fusion initialization method is used, producing higher quality and spatially consistent point clouds. Our extensive experiments demonstrate that compared to other methods, SceneDreamer360 with its panoramic image generation and 3DGS can produce higher quality, spatially consistent, and visually appealing 3D scenes from any text prompt. Our codes are available at \url{https://github.com/liwrui/SceneDreamer360}.