 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentionVLA: Generalizable and Efficient Embodied Intention Reasoning for Human-Robot Interaction
Oct 09, 2025



Vision-Language-Action (VLA) models leverage pretrained vision-language models (VLMs) to couple perception with robotic control, offering a promising path toward general-purpose embodied intelligence. However, current SOTA VLAs are primarily pretrained on multimodal tasks with limited relevance to embodied scenarios, and then finetuned to map explicit instructions to actions. Consequently, due to the lack of reasoning-intensive pretraining and reasoning-guided manipulation, these models are unable to perform implicit human intention reasoning required for complex, real-world interactions. To overcome these limitations, we propose \textbf{IntentionVLA}, a VLA framework with a curriculum training paradigm and an efficient inference mechanism. Our proposed method first leverages carefully designed reasoning data that combine intention inference, spatial grounding, and compact embodied reasoning, endowing the model with both reasoning and perception capabilities. In the following finetuning stage, IntentionVLA employs the compact reasoning outputs as contextual guidance for action generation, enabling fast inference under indirect instructions. Experimental results show that IntentionVLA substantially outperforms $\pi_0$, achieving 18\% higher success rates with direct instructions and 28\% higher than ECoT under intention instructions. On out-of-distribution intention tasks, IntentionVLA achieves over twice the success rate of all baselines, and further enables zero-shot human-robot interaction with 40\% success rate. These results highlight IntentionVLA as a promising paradigm for next-generation human-robot interaction (HRI) systems.
Riemann-based Multi-scale Attention Reasoning Network for Text-3D Retrieval
Aug 25, 2024
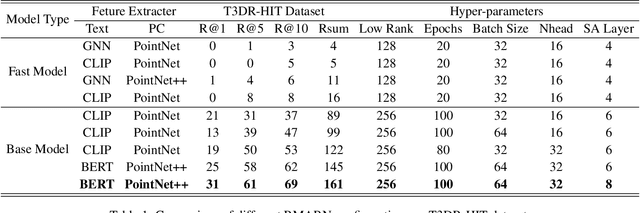


Due to the challenges in acquiring paired Text-3D data and the inherent irregularity of 3D data structures, combined representation learning of 3D point clouds and text remains unexplored. In this paper, we propose a novel Riemann-based Multi-scale Attention Reasoning Network (RMARN) for text-3D retrieval. Specifically, the extracted text and point cloud features are refined by their respective Adaptive Feature Refiner (AFR). Furthermore, we introduce the innovative Riemann Local Similarity (RLS) module and the Global Pooling Similarity (GPS) module. However, as 3D point cloud data and text data often possess complex geometric structures in high-dimensional space, the proposed RLS employs a novel Riemann Attention Mechanism to reflect the intrinsic geometric relationships of the data. Without explicitly defining the manifold, RMARN learns the manifold parameters to better represent the distances between text-point cloud samples. To address the challenges of lacking paired text-3D data, we have created the large-scale Text-3D Retrieval dataset T3DR-HIT, which comprises over 3,380 pairs of text and point cloud data. T3DR-HIT contains coarse-grained indoor 3D scenes and fine-grained Chinese artifact scenes, consisting of 1,380 and over 2,000 text-3D pairs, respectively. Experiments on our custom datasets demonstrate the superior performance of the proposed method. Our code and proposed datasets are available at \url{https://github.com/liwrui/RMARN}.