 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSC-HVPPNet: Spatial and Channel Hybrid-Attention Video Post-Processing Network with CNN and Transformer
Apr 23, 2024Convolutional Neural Network (CNN) and Transformer have attracted much attention recently for video post-processing (VPP). However, the interaction between CNN and Transformer in existing VPP methods is not fully explored, leading to inefficient communication between the local and global extracted features. In this paper, we explore the interaction between CNN and Transformer in the task of VPP, and propose a novel Spatial and Channel Hybrid-Attention Video Post-Processing Network (SC-HVPPNet), which can cooperatively exploit the image priors in both spatial and channel domains. Specifically, in the spatial domain, a novel spatial attention fusion module is designed, in which two attention weights are generated to fuse the local and global representations collaboratively. In the channel domain, a novel channel attention fusion module is developed, which can blend the deep representations at the channel dimension dynamically. Extensive experiments show that SC-HVPPNet notably boosts video restoration quality, with average bitrate savings of 5.29%, 12.42%, and 13.09% for Y, U, and V components in the VTM-11.0-NNVC RA configuration.
Deep Network for Image Compressed Sensing Coding Using Local Structural Sampling
Feb 29, 2024Existing image compressed sensing (CS) coding frameworks usually solve an inverse problem based on measurement coding and optimization-based image reconstruction, which still exist the following two challenges: 1) The widely used random sampling matrix, such as the Gaussian Random Matrix (GRM), usually leads to low measurement coding efficiency. 2) The optimization-based reconstruction methods generally maintain a much higher computational complexity. In this paper, we propose a new CNN based image CS coding framework using local structural sampling (dubbed CSCNet) that includes three functional modules: local structural sampling, measurement coding and Laplacian pyramid reconstruction. In the proposed framework, instead of GRM, a new local structural sampling matrix is first developed, which is able to enhance the correlation between the measurements through a local perceptual sampling strategy. Besides, the designed local structural sampling matrix can be jointly optimized with the other functional modules during training process. After sampling, the measurements with high correlations are produced, which are then coded into final bitstreams by the third-party image codec. At last, a Laplacian pyramid reconstruction network is proposed to efficiently recover the target image from the measurement domain to the image domain. Extensive experimental results demonstrate that the proposed scheme outperforms the existing state-of-the-art CS coding methods, while maintaining fast computational speed.
Deep Unfolding Network for Image Compressed Sensing by Content-adaptive Gradient Updating and Deformation-invariant Non-local Modeling
Oct 16, 2023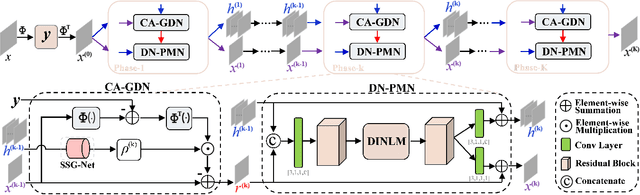


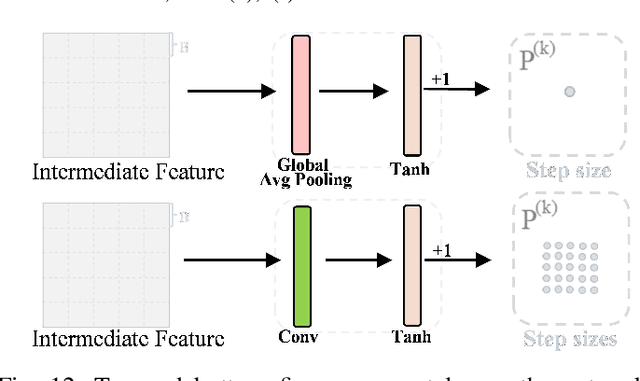
Inspired by certain optimization solvers, the deep unfolding network (DUN) has attracted much attention in recent years for image compressed sensing (CS). However, there still exist the following two issues: 1) In existing DUNs, most hyperparameters are usually content independent, which greatly limits their adaptability for different input contents. 2) In each iteration, a plain convolutional neural network is usually adopted, which weakens the perception of wider context prior and therefore depresses the expressive ability. In this paper, inspired by the traditional Proximal Gradient Descent (PGD) algorithm, a novel DUN for image compressed sensing (dubbed DUN-CSNet) is proposed to solve the above two issues. Specifically, for the first issue, a novel content adaptive gradient descent network is proposed, in which a well-designed step size generation sub-network is developed to dynamically allocate the corresponding step sizes for different textures of input image by generating a content-aware step size map, realizing a content-adaptive gradient updating. For the second issue, considering the fact that many similar patches exist in an image but have undergone a deformation, a novel deformation-invariant non-local proximal mapping network is developed, which can adaptively build the long-range dependencies between the nonlocal patches by deformation-invariant non-local modeling, leading to a wider perception on context priors. Extensive experiments manifest that the proposed DUN-CSNet outperforms existing state-of-the-art CS methods by large margins.
Hierarchical Interactive Reconstruction Network For Video Compressive Sensing
Apr 15, 2023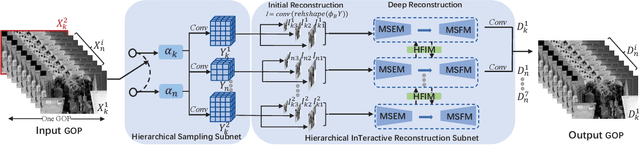
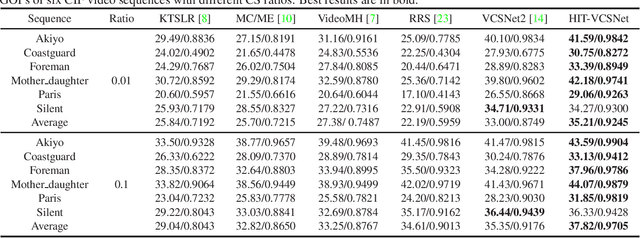
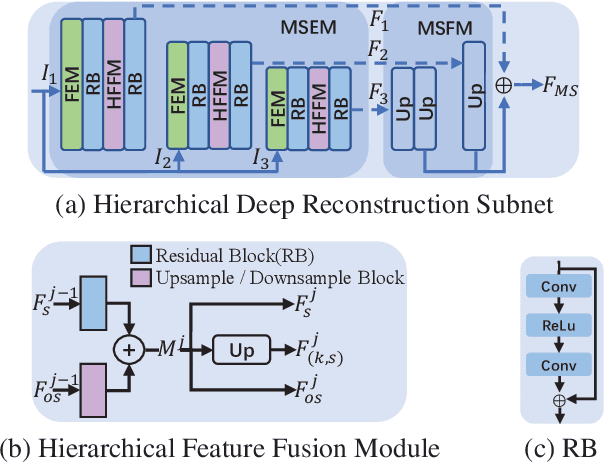
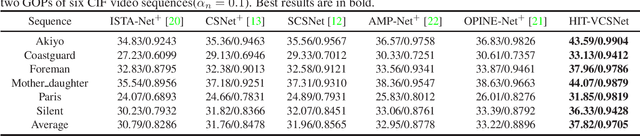
Deep network-based image and video Compressive Sensing(CS) has attracted increasing attentions in recent years. However, in the existing deep network-based CS methods, a simple stacked convolutional network is usually adopted, which not only weakens the perception of rich contextual prior knowledge, but also limits the exploration of the correlations between temporal video frames. In this paper, we propose a novel Hierarchical InTeractive Video CS Reconstruction Network(HIT-VCSNet), which can cooperatively exploit the deep priors in both spatial and temporal domains to improve the reconstruction quality. Specifically, in the spatial domain, a novel hierarchical structure is designed, which can hierarchically extract deep features from keyframes and non-keyframes. In the temporal domain, a novel hierarchical interaction mechanism is proposed, which can cooperatively learn the correlations among different frames in the multiscale space. Extensive experiments manifest that the proposed HIT-VCSNet outperforms the existing state-of-the-art video and image CS methods in a large margin.
Fast Hierarchical Deep Unfolding Network for Image Compressed Sensing
Aug 03, 2022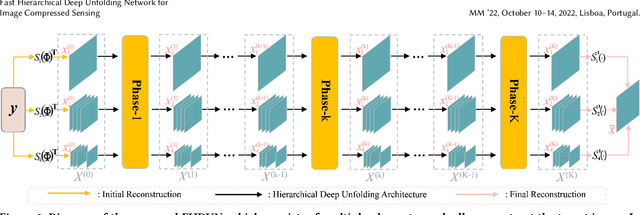

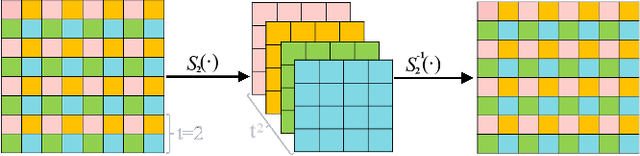
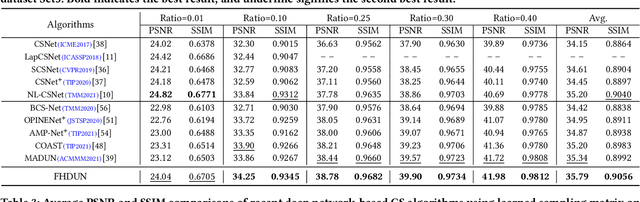
By integrating certain optimization solvers with deep neural network, deep unfolding network (DUN) has attracted much attention in recent years for image compressed sensing (CS). However, there still exist several issues in existing DUNs: 1) For each iteration, a simple stacked convolutional network is usually adopted, which apparently limits the expressiveness of these models. 2) Once the training is completed, most hyperparameters of existing DUNs are fixed for any input content, which significantly weakens their adaptability. In this paper, by unfolding the Fast Iterative Shrinkage-Thresholding Algorithm (FISTA), a novel fast hierarchical DUN, dubbed FHDUN, is proposed for image compressed sensing, in which a well-designed hierarchical unfolding architecture is developed to cooperatively explore richer contextual prior information in multi-scale spaces. To further enhance the adaptability, series of hyperparametric generation networks are developed in our framework to dynamically produce the corresponding optimal hyperparameters according to the input content. Furthermore, due to the accelerated policy in FISTA, the newly embedded acceleration module makes the proposed FHDUN save more than 50% of the iterative loops against recent DUNs. Extensive CS experiments manifest that the proposed FHDUN outperforms existing state-of-the-art CS methods, while maintaining fewer iterations.
Image Compressed Sensing Using Non-local Neural Network
Dec 07, 2021
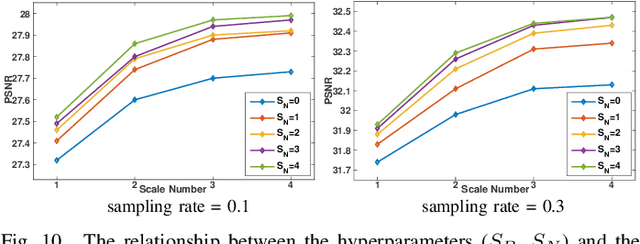


Deep network-based image Compressed Sensing (CS) has attracted much attention in recent years. However, the existing deep network-based CS schemes either reconstruct the target image in a block-by-block manner that leads to serious block artifacts or train the deep network as a black box that brings about limited insights of image prior knowledge. In this paper, a novel image CS framework using non-local neural network (NL-CSNet) is proposed, which utilizes the non-local self-similarity priors with deep network to improve the reconstruction quality. In the proposed NL-CSNet, two non-local subnetworks are constructed for utilizing the non-local self-similarity priors in the measurement domain and the multi-scale feature domain respectively. Specifically, in the subnetwork of measurement domain, the long-distance dependencies between the measurements of different image blocks are established for better initial reconstruction. Analogically, in the subnetwork of multi-scale feature domain, the affinities between the dense feature representations are explored in the multi-scale space for deep reconstruction. Furthermore, a novel loss function is developed to enhance the coupling between the non-local representations, which also enables an end-to-end training of NL-CSNet. Extensive experiments manifest that NL-CSNet outperforms existing state-of-the-art CS methods, while maintaining fast computational speed.
* 14 pages, 11 figures, 7 tables
Multi-Stage Residual Hiding for Image-into-Audio Steganography
Jan 06, 2021



The widespread application of audio communication technologies has speeded up audio data flowing across the Internet, which made it a popular carrier for covert communication. In this paper, we present a cross-modal steganography method for hiding image content into audio carriers while preserving the perceptual fidelity of the cover audio. In our framework, two multi-stage networks are designed: the first network encodes the decreasing multilevel residual errors inside different audio subsequences with the corresponding stage sub-networks, while the second network decodes the residual errors from the modified carrier with the corresponding stage sub-networks to produce the final revealed results. The multi-stage design of proposed framework not only make the controlling of payload capacity more flexible, but also make hiding easier because of the gradual sparse characteristic of residual errors. Qualitative experiments suggest that modifications to the carrier are unnoticeable by human listeners and that the decoded images are highly intelligible.
Convolutional Neural Networks based Intra Prediction for HEVC
Aug 17, 2018



Traditional intra prediction methods for HEVC rely on using the nearest reference lines for predicting a block, which ignore much richer context between the current block and its neighboring blocks and therefore cause inaccurate prediction especially when weak spatial correlation exists between the current block and the reference lines. To overcome this problem, in this paper, an intra prediction convolutional neural network (IPCNN) is proposed for intra prediction, which exploits the rich context of the current block and therefore is capable of improving the accuracy of predicting the current block. Meanwhile, the predictions of the three nearest blocks can also be refined. To the best of our knowledge, this is the first paper that directly applies CNNs to intra prediction for HEVC. Experimental results validate the effectiveness of applying CNNs to intra prediction and achieved significant performance improvement compared to traditional intra prediction methods.
Deep neural network based sparse measurement matrix for image compressed sensing
Jun 19, 2018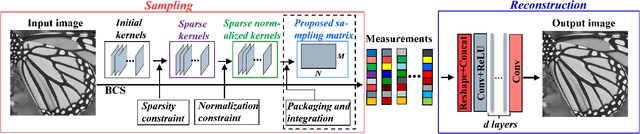
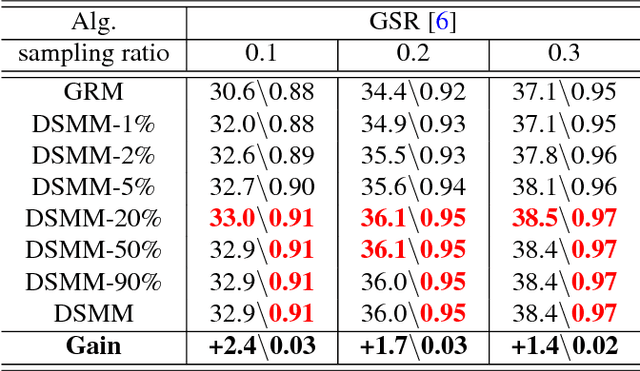

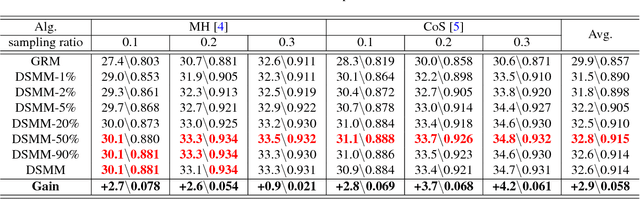
Gaussian random matrix (GRM) has been widely used to generate linear measurements in compressed sensing (CS) of natural images. However, there actually exist two disadvantages with GRM in practice. One is that GRM has large memory requirement and high computational complexity, which restrict the applications of CS. Another is that the CS measurements randomly obtained by GRM cannot provide sufficient reconstruction performances. In this paper, a Deep neural network based Sparse Measurement Matrix (DSMM) is learned by the proposed convolutional network to reduce the sampling computational complexity and improve the CS reconstruction performance. Two sub networks are included in the proposed network, which are the sampling sub-network and the reconstruction sub-network. In the sampling sub-network, the sparsity and the normalization are both considered by the limitation of the storage and the computational complexity. In order to improve the CS reconstruction performance, a reconstruction sub-network are introduced to help enhance the sampling sub-network. So by the offline iterative training of the proposed end-to-end network, the DSMM is generated for accurate measurement and excellent reconstruction. Experimental results demonstrate that the proposed DSMM outperforms GRM greatly on representative CS reconstruction methods
An efficient deep convolutional laplacian pyramid architecture for CS reconstruction at low sampling ratios
Apr 13, 2018

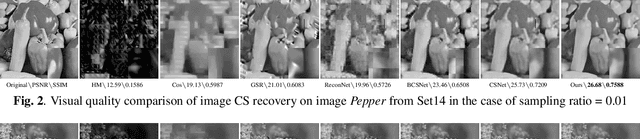

The compressed sensing (CS) has been successfully applied to image compression in the past few years as most image signals are sparse in a certain domain. Several CS reconstruction models have been proposed and obtained superior performance. However, these methods suffer from blocking artifacts or ringing effects at low sampling ratios in most cases. To address this problem, we propose a deep convolutional Laplacian Pyramid Compressed Sensing Network (LapCSNet) for CS, which consists of a sampling sub-network and a reconstruction sub-network. In the sampling sub-network, we utilize a convolutional layer to mimic the sampling operator. In contrast to the fixed sampling matrices used in traditional CS methods, the filters used in our convolutional layer are jointly optimized with the reconstruction sub-network. In the reconstruction sub-network, two branches are designed to reconstruct multi-scale residual images and muti-scale target images progressively using a Laplacian pyramid architecture. The proposed LapCSNet not only integrates multi-scale information to achieve better performance but also reduces computational cost dramatically. Experimental results on benchmark datasets demonstrate that the proposed method is capable of reconstructing more details and sharper edges against the state-of-the-arts methods.