 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single Solution: Multi-Hypothesis Collaborative Deep Unfolding Network for Image Compressive Sensing
Jun 02, 2026Recent deep unfolding networks (DUNs) have advanced Compressive Sensing (CS) by effectively integrating iterative optimization with deep learning architectures. However, most CS approaches predominantly confine their inference to a single solution space, neglecting the inherent ill-posedness of CS problems that intrinsically permits multiple plausible candidate hypotheses. In this paper, a novel Multi-Hypothesis Collaborative Deep Unfolding CS Network (MHC-DUN) is proposed, which explicitly models and leverages multiple hypotheses by jointly optimizing across diverse solution spaces. Specifically, following the Proximal Gradient Descent algorithm, MHC-DUN jointly performs gradient descent and proximal mapping within this multi-hypothesis paradigm. i) For gradient descent, a well-designed AlphaNet is introduced to dynamically predict spatially varying step sizes for all hypotheses, enabling collaborative gradient updates across multiple solutions. ii) For proximal operator, a sophisticated multi-hypothesis collaborative proximal mapping module is designed, which leverages both intra-hypothesis and inter-hypothesis correlation priors to jointly refine multiple solutions. To enable end-to-end training, a novel composite loss function is designed, which balances measurement fidelity, hypothesis diversity, and reconstruction accuracy, encouraging exploration of complementary solutions while maintaining reconstruction fidelity. Experimental results reveal that the proposed CS method outperforms existing CS networks.
PairDropGS: Paired Dropout-Induced Consistency Regularization for Sparse-View Gaussian Splatting
May 13, 2026Dropout-based sparse-view 3D Gaussian Splatting (3DGS) methods alleviate overfitting by randomly suppressing Gaussian primitives during training. Existing methods mainly focus on designing increasingly sophisticated dropout strategies, while they overlook the resulting inconsistencies among different dropped Gaussian subsets. This oversight often leads to unstable reconstruction and suboptimal Gaussian representation learning.In this paper, we revisit dropout-based sparse-view 3DGS from a consistency regularization perspective and propose PairDropGS, a Paired Dropout-induced Consistency Regularization framework for sparse-view Gaussian splatting. Specifically, PairDropGS first constructs a pair of the dropped Gaussian subsets from a shared Gaussian field and designs a low-frequency consistency regularization to constrain their low-frequency rendered structures. This design encourages the shared Gaussian field to preserve stable scene layout and coarse geometry under different random dropouts, while avoiding excessive constraints on ambiguous high-frequency details. Moreover, we introduce a progressive consistency scheduling strategy to gradually strengthen the consistency regularization during training for stability and robustness of reconstruction. Extensive experiments on widely-used sparse-view benchmarks demonstrate that PairDropGS achieves superior training stability, significantly outperforms existing dropout-based 3DGS methods in reconstruction quality, while exhibiting the simplicity and plug-and-play nature for improving dropout-based optimization.
DOC-GS: Dual-Domain Observation and Calibration for Reliable Sparse-View Gaussian Splatting
Apr 08, 2026Sparse-view reconstruction with 3D Gaussian Splatting (3DGS) is fundamentally ill-posed due to insufficient geometric supervision, often leading to severe overfitting and the emergence of structural distortions and translucent haze-like artifacts. While existing approaches attempt to alleviate this issue via dropout-based regularization, they are largely heuristic and lack a unified understanding of artifact formation. In this paper, we revisit sparse-view 3DGS reconstruction from a new perspective and identify the core challenge as the unobservability of Gaussian primitive reliability. Unreliable Gaussians are insufficiently constrained during optimization and accumulate as haze-like degradations in rendered images. Motivated by this observation, we propose a unified Dual-domain Observation and Calibration (DOC-GS) framework that models and corrects Gaussian reliability through the synergy of optimization-domain inductive bias and observation-domain evidence. Specifically, in the optimization domain, we characterize Gaussian reliability by the degree to which each primitive is constrained during training, and instantiate this signal via a Continuous Depth-Guided Dropout (CDGD) strategy, where the dropout probability serves as an explicit proxy for primitive reliability. This imposes a smooth depth-aware inductive bias to suppress weakly constrained Gaussians and improve optimization stability. In the observation domain, we establish a connection between floater artifacts and atmospheric scattering, and leverage the Dark Channel Prior (DCP) as a structural consistency cue to identify and accumulate anomalous regions. Based on cross-view aggregated evidence, we further design a reliability-driven geometric pruning strategy to remove low-confidence Gaussians.
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
MTLSI-Net: A Linear Semantic Interaction Network for Parameter-Efficient Multi-Task Dense Prediction
Apr 02, 2026Multi-task dense prediction aims to perform multiple pixel-level tasks simultaneously. However, capturing global cross-task interactions remains non-trivial due to the quadratic complexity of standard self-attention on high-resolution features. To address this limitation, we propose a Multi-Task Linear Semantic Interaction Network (MTLSI-Net), which facilitates cross-task interaction through linear attention. Specifically, MTLSI-Net incorporates three key components: a Multi-Task Multi-scale Query Linear Fusion Block, which captures cross-task dependencies across multiple scales with linear complexity using a shared global context matrix; a Semantic Token Distiller that compresses redundant features into compact semantic tokens, distilling essential cross-task knowledge; and a Cross-Window Integrated attention Block that injects global semantics into local features via a dual-branch architecture, preserving both global consistency and spatial precision. These components collectively enable the network to capture comprehensive cross-task interactions at linear complexity with reduced parameters. Extensive experiments on NYUDv2 and PASCAL-Context demonstrate that MTLSI-Net achieves state-of-the-art performance, validating its effectiveness and efficiency in multi-task learning.
LG-HCC: Local Geometry-Aware Hierarchical Context Compression for 3D Gaussian Splatting
Apr 01, 2026Although 3D Gaussian Splatting (3DGS) enables high-fidelity real-time rendering, its prohibitive storage overhead severely hinders practical deployment. Recent anchor-based 3DGS compression schemes reduce gaussian redundancy through some advanced context models. However, they overlook explicit geometric dependencies, leading to structural degradation and suboptimal ratedistortion performance. In this paper, we propose a Local Geometry-aware Hierarchical Context Compression framework for 3DGS(LG-HCC) that incorporates inter-anchor geometric correlations into anchor pruning and entropy coding for compact representation. Specifically, we introduce an Neighborhood-Aware Anchor Pruning (NAAP) strategy, which evaluates anchor importance via weighted neighborhood feature aggregation and then merges low-contribution anchors into salient neighbors, yielding a compact yet geometry-consistent anchor set. Moreover, we further develop a hierarchical entropy coding scheme, in which coarse-to-fine priors are exploited through a lightweight Geometry-Guided Convolution(GG-Conv) operator to enable spatially adaptive context modeling and rate-distortion optimization. Extensive experiments show that LG-HCC effectively alleviates structural preservation issues,achieving superior geometric integrity and rendering fidelity while reducing storage by up to 30.85x compared to the Scaffold-GS baseline on the Mip-NeRF360 dataset
MRT: Learning Compact Representations with Mixed RWKV-Transformer for Extreme Image Compression
Nov 14, 2025Recent advances in extreme image compression have revealed that mapping pixel data into highly compact latent representations can significantly improve coding efficiency. However, most existing methods compress images into 2-D latent spaces via convolutional neural networks (CNNs) or Swin Transformers, which tend to retain substantial spatial redundancy, thereby limiting overall compression performance. In this paper, we propose a novel Mixed RWKV-Transformer (MRT) architecture that encodes images into more compact 1-D latent representations by synergistically integrating the complementary strengths of linear-attention-based RWKV and self-attention-based Transformer models. Specifically, MRT partitions each image into fixed-size windows, utilizing RWKV modules to capture global dependencies across windows and Transformer blocks to model local redundancies within each window. The hierarchical attention mechanism enables more efficient and compact representation learning in the 1-D domain. To further enhance compression efficiency, we introduce a dedicated RWKV Compression Model (RCM) tailored to the structure characteristics of the intermediate 1-D latent features in MRT. Extensive experiments on standard image compression benchmarks validate the effectiveness of our approach. The proposed MRT framework consistently achieves superior reconstruction quality at bitrates below 0.02 bits per pixel (bpp). Quantitative results based on the DISTS metric show that MRT significantly outperforms the state-of-the-art 2-D architecture GLC, achieving bitrate savings of 43.75%, 30.59% on the Kodak and CLIC2020 test datasets, respectively.
Perceptual Quality Assessment of 3D Gaussian Splatting: A Subjective Dataset and Prediction Metric
Nov 11, 2025
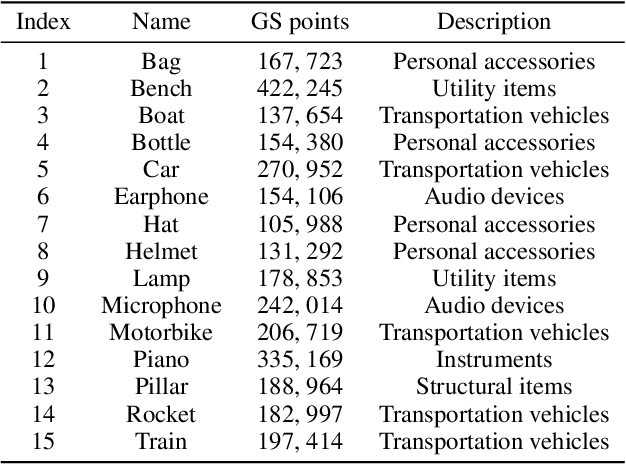
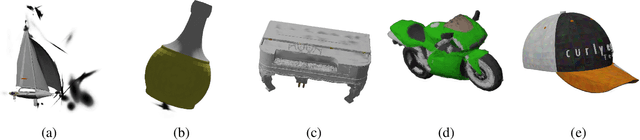
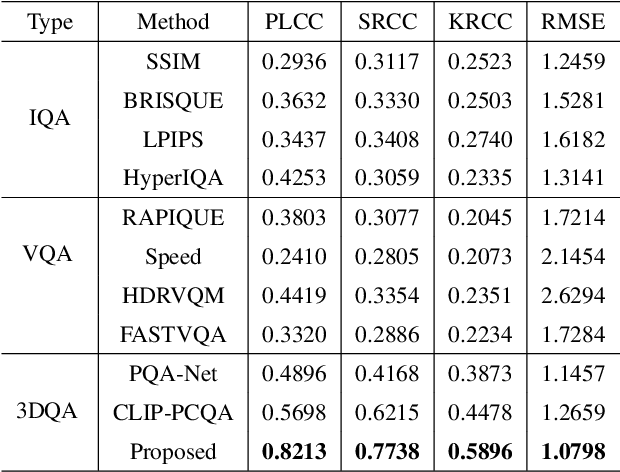
With the rapid advancement of 3D visualization, 3D Gaussian Splatting (3DGS) has emerged as a leading technique for real-time, high-fidelity rendering. While prior research has emphasized algorithmic performance and visual fidelity, the perceptual quality of 3DGS-rendered content, especially under varying reconstruction conditions, remains largely underexplored. In practice, factors such as viewpoint sparsity, limited training iterations, point downsampling, noise, and color distortions can significantly degrade visual quality, yet their perceptual impact has not been systematically studied. To bridge this gap, we present 3DGS-QA, the first subjective quality assessment dataset for 3DGS. It comprises 225 degraded reconstructions across 15 object types, enabling a controlled investigation of common distortion factors. Based on this dataset, we introduce a no-reference quality prediction model that directly operates on native 3D Gaussian primitives, without requiring rendered images or ground-truth references. Our model extracts spatial and photometric cues from the Gaussian representation to estimate perceived quality in a structure-aware manner. We further benchmark existing quality assessment methods, spanning both traditional and learning-based approaches. Experimental results show that our method consistently achieves superior performance, highlighting its robustness and effectiveness for 3DGS content evaluation. The dataset and code are made publicly available at https://github.com/diaoyn/3DGSQA to facilitate future research in 3DGS quality assessment.
Feature-aligned Motion Transformation for Efficient Dynamic Point Cloud Compression
Sep 18, 2025Dynamic point clouds are widely used in applications such as immersive reality, robotics, and autonomous driving. Efficient compression largely depends on accurate motion estimation and compensation, yet the irregular structure and significant local variations of point clouds make this task highly challenging. Current methods often rely on explicit motion estimation, whose encoded vectors struggle to capture intricate dynamics and fail to fully exploit temporal correlations. To overcome these limitations, we introduce a Feature-aligned Motion Transformation (FMT) framework for dynamic point cloud compression. FMT replaces explicit motion vectors with a spatiotemporal alignment strategy that implicitly models continuous temporal variations, using aligned features as temporal context within a latent-space conditional encoding framework. Furthermore, we design a random access (RA) reference strategy that enables bidirectional motion referencing and layered encoding, thereby supporting frame-level parallel compression. Extensive experiments demonstrate that our method surpasses D-DPCC and AdaDPCC in both encoding and decoding efficiency, while also achieving BD-Rate reductions of 20% and 9.4%, respectively. These results highlight the effectiveness of FMT in jointly improving compression efficiency and processing performance.
Region-Level Context-Aware Multimodal Understanding
Aug 17, 2025Despite significant progress, existing research on Multimodal Large Language Models (MLLMs) mainly focuses on general visual understanding, overlooking the ability to integrate textual context associated with objects for a more context-aware multimodal understanding -- an ability we refer to as Region-level Context-aware Multimodal Understanding (RCMU). To address this limitation, we first formulate the RCMU task, which requires models to respond to user instructions by integrating both image content and textual information of regions or objects. To equip MLLMs with RCMU capabilities, we propose Region-level Context-aware Visual Instruction Tuning (RCVIT), which incorporates object information into the model input and enables the model to utilize bounding box coordinates to effectively associate objects' visual content with their textual information. To address the lack of datasets, we introduce the RCMU dataset, a large-scale visual instruction tuning dataset that covers multiple RCMU tasks. We also propose RC\&P-Bench, a comprehensive benchmark that can evaluate the performance of MLLMs in RCMU and multimodal personalized understanding tasks. Additionally, we propose a reference-free evaluation metric to perform a comprehensive and fine-grained evaluation of the region-level context-aware image descriptions. By performing RCVIT on Qwen2-VL models with the RCMU dataset, we developed RC-Qwen2-VL models. Experimental results indicate that RC-Qwen2-VL models not only achieve outstanding performance on multiple RCMU tasks but also demonstrate successful applications in multimodal RAG and personalized conversation. Our data, model and benchmark are available at https://github.com/hongliang-wei/RC-MLLM