 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-GRPO: Training Autoregressive Image Generation Models via Reinforcement Learning
Aug 09, 2025



Inspired by the success of reinforcement learning (RL) in refining large language models (LLMs), we propose AR-GRPO, an approach to integrate online RL training into autoregressive (AR) image generation models. We adapt the Group Relative Policy Optimization (GRPO) algorithm to refine the vanilla autoregressive models' outputs by carefully designed reward functions that evaluate generated images across multiple quality dimensions, including perceptual quality, realism, and semantic fidelity. We conduct comprehensive experiments on both class-conditional (i.e., class-to-image) and text-conditional (i.e., text-to-image) image generation tasks, demonstrating that our RL-enhanced framework significantly improves both the image quality and human preference of generated images compared to the standard AR baselines. Our results show consistent improvements across various evaluation metrics, establishing the viability of RL-based optimization for AR image generation and opening new avenues for controllable and high-quality image synthesis. The source codes and models are available at: https://github.com/Kwai-Klear/AR-GRPO.
Triad: Empowering LMM-based Anomaly Detection with Vision Expert-guided Visual Tokenizer and Manufacturing Process
Mar 17, 2025
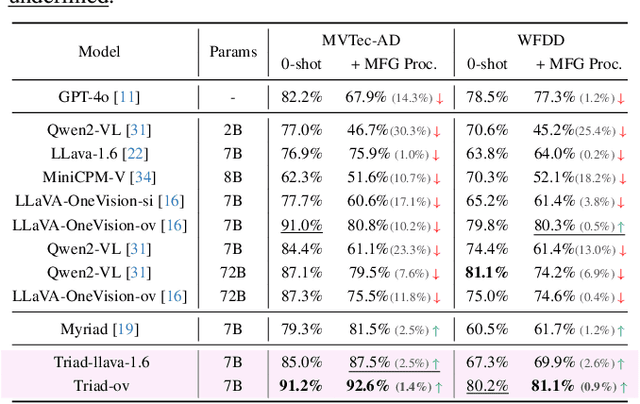
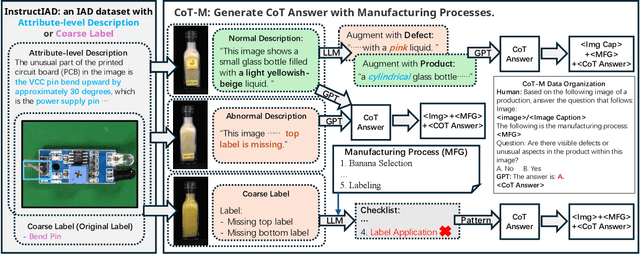
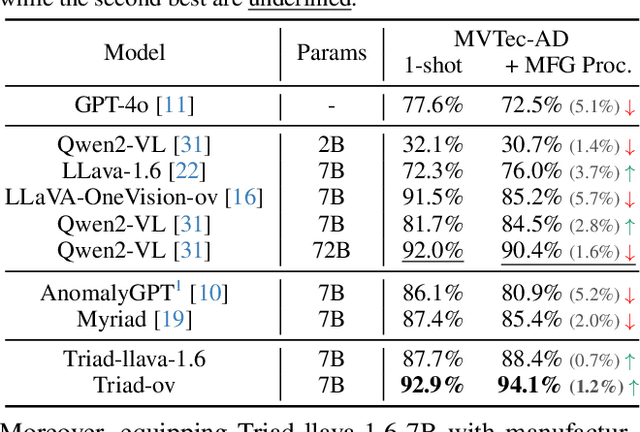
Although recent methods have tried to introduce large multimodal models (LMMs) into industrial anomaly detection (IAD), their generalization in the IAD field is far inferior to that for general purposes. We summarize the main reasons for this gap into two aspects. On one hand, general-purpose LMMs lack cognition of defects in the visual modality, thereby failing to sufficiently focus on defect areas. Therefore, we propose to modify the AnyRes structure of the LLaVA model, providing the potential anomalous areas identified by existing IAD models to the LMMs. On the other hand, existing methods mainly focus on identifying defects by learning defect patterns or comparing with normal samples, yet they fall short of understanding the causes of these defects. Considering that the generation of defects is closely related to the manufacturing process, we propose a manufacturing-driven IAD paradigm. An instruction-tuning dataset for IAD (InstructIAD) and a data organization approach for Chain-of-Thought with manufacturing (CoT-M) are designed to leverage the manufacturing process for IAD. Based on the above two modifications, we present Triad, a novel LMM-based method incorporating an expert-guided region-of-interest tokenizer and manufacturing process for industrial anomaly detection. Extensive experiments show that our Triad not only demonstrates competitive performance against current LMMs but also achieves further improved accuracy when equipped with manufacturing processes. Source code, training data, and pre-trained models will be publicly available at https://github.com/tzjtatata/Triad.
Myriad: Large Multimodal Model by Applying Vision Experts for Industrial Anomaly Detection
Nov 01, 2023



Existing industrial anomaly detection (IAD) methods predict anomaly scores for both anomaly detection and localization. However, they struggle to perform a multi-turn dialog and detailed descriptions for anomaly regions, e.g., color, shape, and categories of industrial anomalies. Recently, large multimodal (i.e., vision and language) models (LMMs) have shown eminent perception abilities on multiple vision tasks such as image captioning, visual understanding, visual reasoning, etc., making it a competitive potential choice for more comprehensible anomaly detection. However, the knowledge about anomaly detection is absent in existing general LMMs, while training a specific LMM for anomaly detection requires a tremendous amount of annotated data and massive computation resources. In this paper, we propose a novel large multi-modal model by applying vision experts for industrial anomaly detection (dubbed Myriad), which leads to definite anomaly detection and high-quality anomaly description. Specifically, we adopt MiniGPT-4 as the base LMM and design an Expert Perception module to embed the prior knowledge from vision experts as tokens which are intelligible to Large Language Models (LLMs). To compensate for the errors and confusions of vision experts, we introduce a domain adapter to bridge the visual representation gaps between generic and industrial images. Furthermore, we propose a Vision Expert Instructor, which enables the Q-Former to generate IAD domain vision-language tokens according to vision expert prior. Extensive experiments on MVTec-AD and VisA benchmarks demonstrate that our proposed method not only performs favorably against state-of-the-art methods under the 1-class and few-shot settings, but also provide definite anomaly prediction along with detailed descriptions in IAD domain.
Learning Visual Representation of Underwater Acoustic Imagery Using Transformer-Based Style Transfer Method
Nov 10, 2022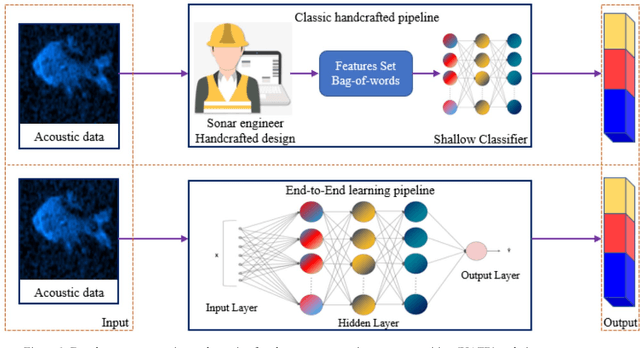
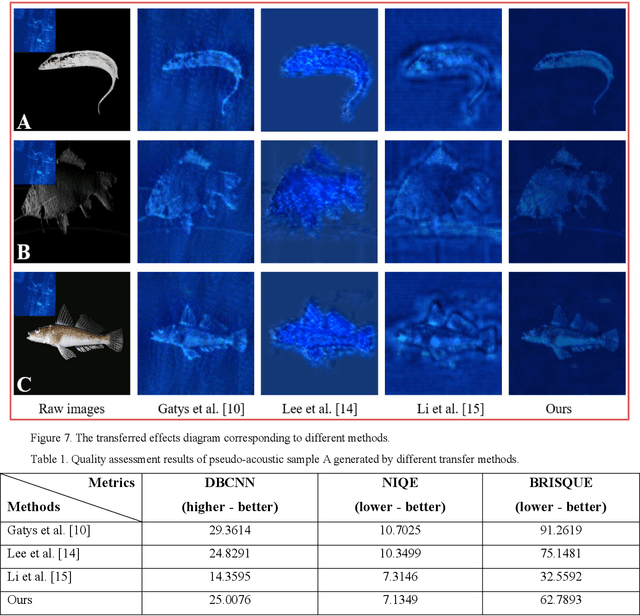
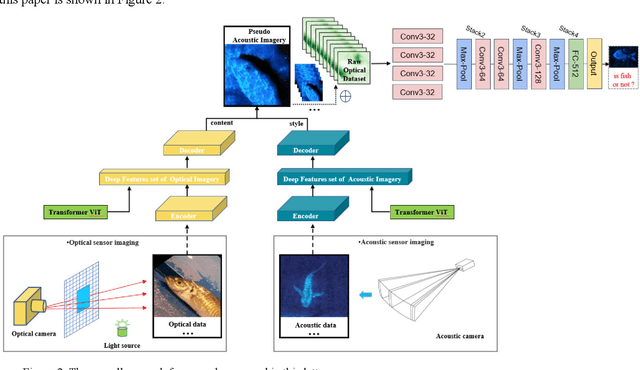
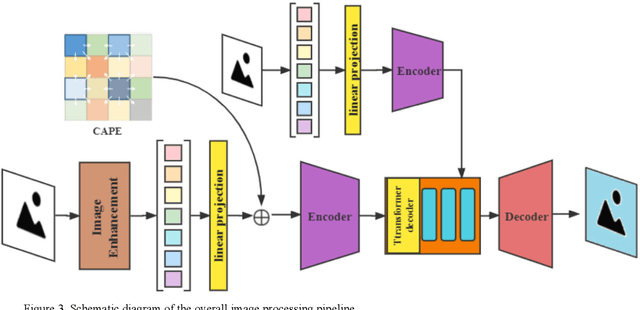
Underwater automatic target recognition (UATR) has been a challenging research topic in ocean engineering. Although deep learning brings opportunities for target recognition on land and in the air, underwater target recognition techniques based on deep learning have lagged due to sensor performance and the size of trainable data. This letter proposed a framework for learning the visual representation of underwater acoustic imageries, which takes a transformer-based style transfer model as the main body. It could replace the low-level texture features of optical images with the visual features of underwater acoustic imageries while preserving their raw high-level semantic content. The proposed framework could fully use the rich optical image dataset to generate a pseudo-acoustic image dataset and use it as the initial sample to train the underwater acoustic target recognition model. The experiments select the dual-frequency identification sonar (DIDSON) as the underwater acoustic data source and also take fish, the most common marine creature, as the research subject. Experimental results show that the proposed method could generate high-quality and high-fidelity pseudo-acoustic samples, achieve the purpose of acoustic data enhancement and provide support for the underwater acoustic-optical images domain transfer research.