 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrokking or Glitching? How Low-Precision Drives Slingshot Loss Spikes
May 07, 2026Deep neural networks exhibit periodic loss spikes during unregularized long-term training, a phenomenon known as the "Slingshot Mechanism." Existing work usually attributes this to intrinsic optimization dynamics, but its triggering mechanism remains unclear. This paper proves that this phenomenon is a result of floating-point arithmetic precision limits. As training enters a high-confidence stage, the difference between the correct-class logit and the other logits may exceed the absorption-error threshold. Then during backpropagation, the gradient of the correct class is rounded exactly to zero, while the gradients of the incorrect classes remain nonzero. This breaks the zero-sum constraint of gradients across classes and introduces a systematic drift in the parameter update of the classifier layer. We prove that this drift forms a positive feedback loop with the feature, causing the global classifier mean and the global feature mean to grow exponentially. We call this mechanism Numerical Feature Inflation (NFI). This mechanism explains the rapid norm growth before a Slingshot spike, the subsequent reappearance of gradients, and the resulting loss spike. We further show that NFI is not equivalent to an observed loss spike: in more practical tasks, partial absorption may not produce visible spikes, but it can still break the zero-sum constraint and drive rapid growth of parameter norms. Our results reinterpret Slingshot as a numerical dynamic of finite-precision training, and provide a testable explanation for abnormal parameter growth and logit divergence in late-stage training.
THEMIS: Towards Holistic Evaluation of MLLMs for Scientific Paper Fraud Forensics
Mar 26, 2026We present THEMIS, a novel multi-task benchmark designed to comprehensively evaluate multimodal large language models (MLLMs) on visual fraud reasoning within real-world academic scenarios. Compared to existing benchmarks, THEMIS introduces three major advances. (1) Real-World Scenarios and Complexity: Our benchmark comprises over 4,000 questions spanning seven scenarios, derived from authentic retracted-paper cases and carefully curated multimodal synthetic data. With 60.47% complex-texture images, THEMIS bridges the critical gap between existing benchmarks and the complexity of real-world academic fraud. (2) Fraud-Type Diversity and Granularity: THEMIS systematically covers five challenging fraud types and introduces 16 fine-grained manipulation operations. On average, each sample undergoes multiple stacked manipulation operations, with the diversity and difficulty of these manipulations demanding a high level of visual fraud reasoning from the models. (3) Multi-Dimensional Capability Evaluation: We establish a mapping from fraud types to five core visual fraud reasoning capabilities, thereby enabling an evaluation that reveals the distinct strengths and specific weaknesses of different models across these core capabilities. Experiments on 16 leading MLLMs show that even the best-performing model, GPT-5, achieves an overall performance of only 56.15%, demonstrating that our benchmark presents a stringent test. We expect THEMIS to advance the development of MLLMs for complex, real-world fraud reasoning tasks.
FinMMDocR: Benchmarking Financial Multimodal Reasoning with Scenario Awareness, Document Understanding, and Multi-Step Computation
Dec 31, 2025We introduce FinMMDocR, a novel bilingual multimodal benchmark for evaluating multimodal large language models (MLLMs) on real-world financial numerical reasoning. Compared to existing benchmarks, our work delivers three major advancements. (1) Scenario Awareness: 57.9% of 1,200 expert-annotated problems incorporate 12 types of implicit financial scenarios (e.g., Portfolio Management), challenging models to perform expert-level reasoning based on assumptions; (2) Document Understanding: 837 Chinese/English documents spanning 9 types (e.g., Company Research) average 50.8 pages with rich visual elements, significantly surpassing existing benchmarks in both breadth and depth of financial documents; (3) Multi-Step Computation: Problems demand 11-step reasoning on average (5.3 extraction + 5.7 calculation steps), with 65.0% requiring cross-page evidence (2.4 pages average). The best-performing MLLM achieves only 58.0% accuracy, and different retrieval-augmented generation (RAG) methods show significant performance variations on this task. We expect FinMMDocR to drive improvements in MLLMs and reasoning-enhanced methods on complex multimodal reasoning tasks in real-world scenarios.
Triad: Empowering LMM-based Anomaly Detection with Vision Expert-guided Visual Tokenizer and Manufacturing Process
Mar 17, 2025
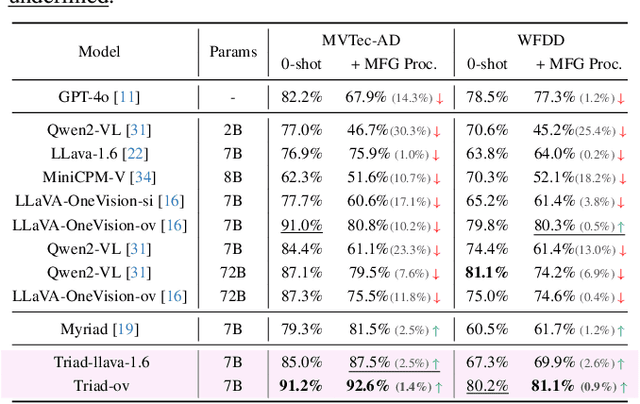
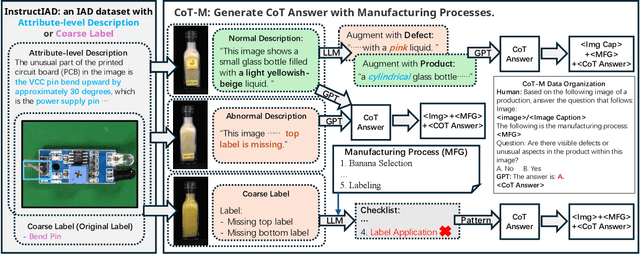
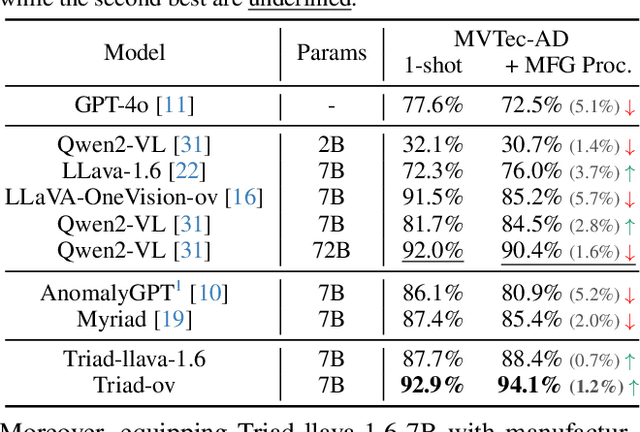
Although recent methods have tried to introduce large multimodal models (LMMs) into industrial anomaly detection (IAD), their generalization in the IAD field is far inferior to that for general purposes. We summarize the main reasons for this gap into two aspects. On one hand, general-purpose LMMs lack cognition of defects in the visual modality, thereby failing to sufficiently focus on defect areas. Therefore, we propose to modify the AnyRes structure of the LLaVA model, providing the potential anomalous areas identified by existing IAD models to the LMMs. On the other hand, existing methods mainly focus on identifying defects by learning defect patterns or comparing with normal samples, yet they fall short of understanding the causes of these defects. Considering that the generation of defects is closely related to the manufacturing process, we propose a manufacturing-driven IAD paradigm. An instruction-tuning dataset for IAD (InstructIAD) and a data organization approach for Chain-of-Thought with manufacturing (CoT-M) are designed to leverage the manufacturing process for IAD. Based on the above two modifications, we present Triad, a novel LMM-based method incorporating an expert-guided region-of-interest tokenizer and manufacturing process for industrial anomaly detection. Extensive experiments show that our Triad not only demonstrates competitive performance against current LMMs but also achieves further improved accuracy when equipped with manufacturing processes. Source code, training data, and pre-trained models will be publicly available at https://github.com/tzjtatata/Triad.
Unprejudiced Training Auxiliary Tasks Makes Primary Better: A Multi-Task Learning Perspective
Dec 27, 2024Human beings can leverage knowledge from relative tasks to improve learning on a primary task. Similarly, multi-task learning methods suggest using auxiliary tasks to enhance a neural network's performance on a specific primary task. However, previous methods often select auxiliary tasks carefully but treat them as secondary during training. The weights assigned to auxiliary losses are typically smaller than the primary loss weight, leading to insufficient training on auxiliary tasks and ultimately failing to support the main task effectively. To address this issue, we propose an uncertainty-based impartial learning method that ensures balanced training across all tasks. Additionally, we consider both gradients and uncertainty information during backpropagation to further improve performance on the primary task. Extensive experiments show that our method achieves performance comparable to or better than state-of-the-art approaches. Moreover, our weighting strategy is effective and robust in enhancing the performance of the primary task regardless the noise auxiliary tasks' pseudo labels.
Class Balance Matters to Active Class-Incremental Learning
Dec 09, 2024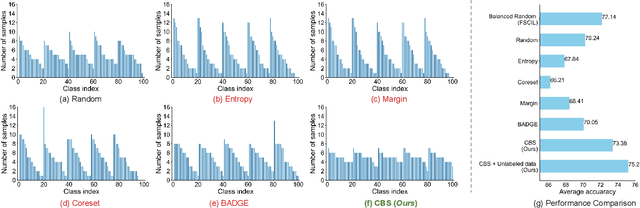
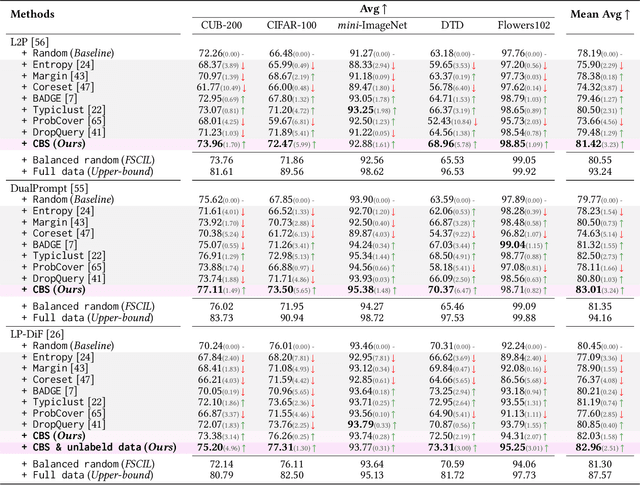

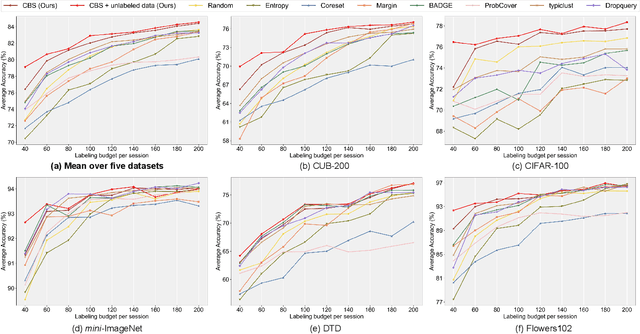
Few-Shot Class-Incremental Learning has shown remarkable efficacy in efficient learning new concepts with limited annotations. Nevertheless, the heuristic few-shot annotations may not always cover the most informative samples, which largely restricts the capability of incremental learner. We aim to start from a pool of large-scale unlabeled data and then annotate the most informative samples for incremental learning. Based on this premise, this paper introduces the Active Class-Incremental Learning (ACIL). The objective of ACIL is to select the most informative samples from the unlabeled pool to effectively train an incremental learner, aiming to maximize the performance of the resulting model. Note that vanilla active learning algorithms suffer from class-imbalanced distribution among annotated samples, which restricts the ability of incremental learning. To achieve both class balance and informativeness in chosen samples, we propose Class-Balanced Selection (CBS) strategy. Specifically, we first cluster the features of all unlabeled images into multiple groups. Then for each cluster, we employ greedy selection strategy to ensure that the Gaussian distribution of the sampled features closely matches the Gaussian distribution of all unlabeled features within the cluster. Our CBS can be plugged and played into those CIL methods which are based on pretrained models with prompts tunning technique. Extensive experiments under ACIL protocol across five diverse datasets demonstrate that CBS outperforms both random selection and other SOTA active learning approaches. Code is publicly available at https://github.com/1170300714/CBS.
Myriad: Large Multimodal Model by Applying Vision Experts for Industrial Anomaly Detection
Nov 01, 2023



Existing industrial anomaly detection (IAD) methods predict anomaly scores for both anomaly detection and localization. However, they struggle to perform a multi-turn dialog and detailed descriptions for anomaly regions, e.g., color, shape, and categories of industrial anomalies. Recently, large multimodal (i.e., vision and language) models (LMMs) have shown eminent perception abilities on multiple vision tasks such as image captioning, visual understanding, visual reasoning, etc., making it a competitive potential choice for more comprehensible anomaly detection. However, the knowledge about anomaly detection is absent in existing general LMMs, while training a specific LMM for anomaly detection requires a tremendous amount of annotated data and massive computation resources. In this paper, we propose a novel large multi-modal model by applying vision experts for industrial anomaly detection (dubbed Myriad), which leads to definite anomaly detection and high-quality anomaly description. Specifically, we adopt MiniGPT-4 as the base LMM and design an Expert Perception module to embed the prior knowledge from vision experts as tokens which are intelligible to Large Language Models (LLMs). To compensate for the errors and confusions of vision experts, we introduce a domain adapter to bridge the visual representation gaps between generic and industrial images. Furthermore, we propose a Vision Expert Instructor, which enables the Q-Former to generate IAD domain vision-language tokens according to vision expert prior. Extensive experiments on MVTec-AD and VisA benchmarks demonstrate that our proposed method not only performs favorably against state-of-the-art methods under the 1-class and few-shot settings, but also provide definite anomaly prediction along with detailed descriptions in IAD domain.
On Steering Multi-Annotations per Sample for Multi-Task Learning
Mar 06, 2022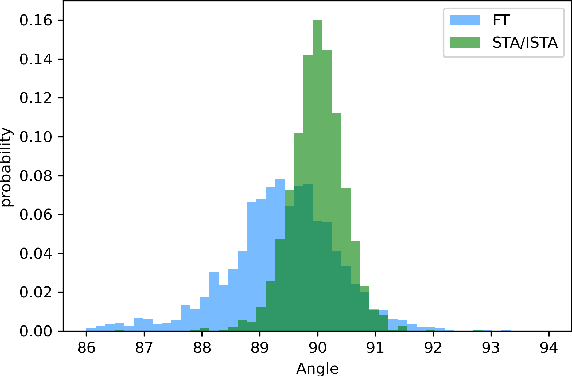
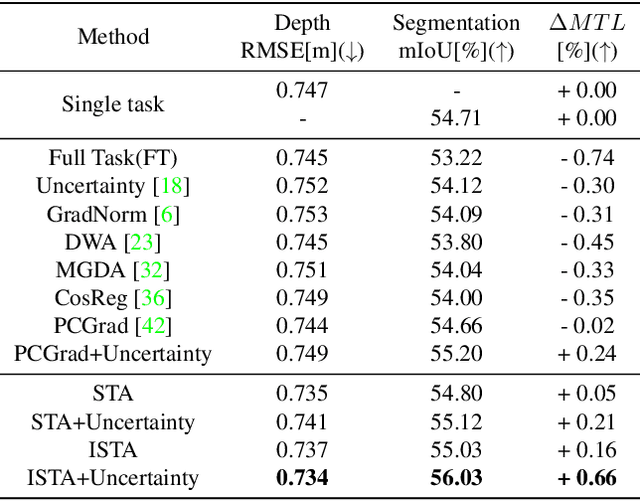
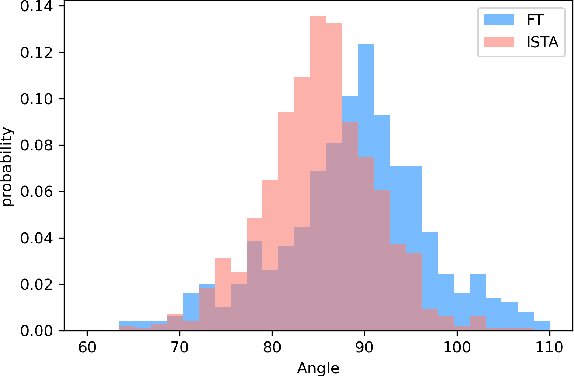
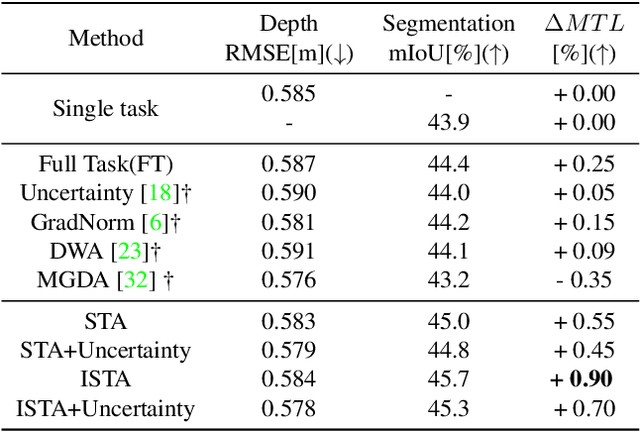
The study of multi-task learning has drawn great attention from the community. Despite the remarkable progress, the challenge of optimally learning different tasks simultaneously remains to be explored. Previous works attempt to modify the gradients from different tasks. Yet these methods give a subjective assumption of the relationship between tasks, and the modified gradient may be less accurate. In this paper, we introduce Stochastic Task Allocation~(STA), a mechanism that addresses this issue by a task allocation approach, in which each sample is randomly allocated a subset of tasks. For further progress, we propose Interleaved Stochastic Task Allocation~(ISTA) to iteratively allocate all tasks to each example during several consecutive iterations. We evaluate STA and ISTA on various datasets and applications: NYUv2, Cityscapes, and COCO for scene understanding and instance segmentation. Our experiments show both STA and ISTA outperform current state-of-the-art methods. The code will be available.