 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCGL: Advancing Continual GUI Learning via Reinforcement Fine-Tuning
Mar 03, 2026Graphical User Interface (GUI) Agents, benefiting from recent advances in multimodal large language models (MLLM), have achieved significant development. However, due to the frequent updates of GUI applications, adapting to new tasks without forgetting old tasks in GUI continual learning remains an open problem. In this work, we reveal that while Supervised Fine-Tuning (SFT) facilitates fast adaptation, it often triggers knowledge overwriting, whereas Reinforcement Learning (RL) demonstrates an inherent resilience that shields prior interaction logic from erasure. Based on this insight, we propose a \textbf{C}ontinual \textbf{G}UI \textbf{L}earning (CGL) framework that dynamically balances adaptation efficiency and skill retention by enhancing the synergy between SFT and RL. Specifically, we introduce an SFT proportion adjustment mechanism guided by policy entropy to dynamically control the weight allocation between the SFT and RL training phases. To resolve explicit gradient interference, we further develop a specialized gradient surgery strategy. By projecting exploratory SFT gradients onto GRPO-based anchor gradients, our method explicitly clips the components of SFT gradients that conflict with GRPO. On top of that, we establish an AndroidControl-CL benchmark, which divides GUI applications into distinct task groups to effectively simulate and evaluate the performance of continual GUI learning. Experimental results demonstrate the effectiveness of our proposed CGL framework across continual learning scenarios. The benchmark, code, and model will be made publicly available.
Mind the Generative Details: Direct Localized Detail Preference Optimization for Video Diffusion Models
Jan 08, 2026Aligning text-to-video diffusion models with human preferences is crucial for generating high-quality videos. Existing Direct Preference Otimization (DPO) methods rely on multi-sample ranking and task-specific critic models, which is inefficient and often yields ambiguous global supervision. To address these limitations, we propose LocalDPO, a novel post-training framework that constructs localized preference pairs from real videos and optimizes alignment at the spatio-temporal region level. We design an automated pipeline to efficiently collect preference pair data that generates preference pairs with a single inference per prompt, eliminating the need for external critic models or manual annotation. Specifically, we treat high-quality real videos as positive samples and generate corresponding negatives by locally corrupting them with random spatio-temporal masks and restoring only the masked regions using the frozen base model. During training, we introduce a region-aware DPO loss that restricts preference learning to corrupted areas for rapid convergence. Experiments on Wan2.1 and CogVideoX demonstrate that LocalDPO consistently improves video fidelity, temporal coherence and human preference scores over other post-training approaches, establishing a more efficient and fine-grained paradigm for video generator alignment.
High-Quality Proposal Encoding and Cascade Denoising for Imaginary Supervised Object Detection
Nov 11, 2025Object detection models demand large-scale annotated datasets, which are costly and labor-intensive to create. This motivated Imaginary Supervised Object Detection (ISOD), where models train on synthetic images and test on real images. However, existing methods face three limitations: (1) synthetic datasets suffer from simplistic prompts, poor image quality, and weak supervision; (2) DETR-based detectors, due to their random query initialization, struggle with slow convergence and overfitting to synthetic patterns, hindering real-world generalization; (3) uniform denoising pressure promotes model overfitting to pseudo-label noise. We propose Cascade HQP-DETR to address these limitations. First, we introduce a high-quality data pipeline using LLaMA-3, Flux, and Grounding DINO to generate the FluxVOC and FluxCOCO datasets, advancing ISOD from weak to full supervision. Second, our High-Quality Proposal guided query encoding initializes object queries with image-specific priors from SAM-generated proposals and RoI-pooled features, accelerating convergence while steering the model to learn transferable features instead of overfitting to synthetic patterns. Third, our cascade denoising algorithm dynamically adjusts training weights through progressively increasing IoU thresholds across decoder layers, guiding the model to learn robust boundaries from reliable visual cues rather than overfitting to noisy labels. Trained for just 12 epochs solely on FluxVOC, Cascade HQP-DETR achieves a SOTA 61.04\% mAP@0.5 on PASCAL VOC 2007, outperforming strong baselines, with its competitive real-data performance confirming the architecture's universal applicability.
Dual-Thresholding Heatmaps to Cluster Proposals for Weakly Supervised Object Detection
Sep 10, 2025



Weakly supervised object detection (WSOD) has attracted significant attention in recent years, as it does not require box-level annotations. State-of-the-art methods generally adopt a multi-module network, which employs WSDDN as the multiple instance detection network module and multiple instance refinement modules to refine performance. However, these approaches suffer from three key limitations. First, existing methods tend to generate pseudo GT boxes that either focus only on discriminative parts, failing to capture the whole object, or cover the entire object but fail to distinguish between adjacent intra-class instances. Second, the foundational WSDDN architecture lacks a crucial background class representation for each proposal and exhibits a large semantic gap between its branches. Third, prior methods discard ignored proposals during optimization, leading to slow convergence. To address these challenges, we first design a heatmap-guided proposal selector (HGPS) algorithm, which utilizes dual thresholds on heatmaps to pre-select proposals, enabling pseudo GT boxes to both capture the full object extent and distinguish between adjacent intra-class instances. We then present a weakly supervised basic detection network (WSBDN), which augments each proposal with a background class representation and uses heatmaps for pre-supervision to bridge the semantic gap between matrices. At last, we introduce a negative certainty supervision loss on ignored proposals to accelerate convergence. Extensive experiments on the challenging PASCAL VOC 2007 and 2012 datasets demonstrate the effectiveness of our framework. We achieve mAP/mCorLoc scores of 58.5%/81.8% on VOC 2007 and 55.6%/80.5% on VOC 2012, performing favorably against the state-of-the-art WSOD methods. Our code is publicly available at https://github.com/gyl2565309278/DTH-CP.
SWAT-NN: Simultaneous Weights and Architecture Training for Neural Networks in a Latent Space
Jun 11, 2025Designing neural networks typically relies on manual trial and error or a neural architecture search (NAS) followed by weight training. The former is time-consuming and labor-intensive, while the latter often discretizes architecture search and weight optimization. In this paper, we propose a fundamentally different approach that simultaneously optimizes both the architecture and the weights of a neural network. Our framework first trains a universal multi-scale autoencoder that embeds both architectural and parametric information into a continuous latent space, where functionally similar neural networks are mapped closer together. Given a dataset, we then randomly initialize a point in the embedding space and update it via gradient descent to obtain the optimal neural network, jointly optimizing its structure and weights. The optimization process incorporates sparsity and compactness penalties to promote efficient models. Experiments on synthetic regression tasks demonstrate that our method effectively discovers sparse and compact neural networks with strong performance.
MIRAGE: Assessing Hallucination in Multimodal Reasoning Chains of MLLM
May 30, 2025Multimodal hallucination in multimodal large language models (MLLMs) restricts the correctness of MLLMs. However, multimodal hallucinations are multi-sourced and arise from diverse causes. Existing benchmarks fail to adequately distinguish between perception-induced hallucinations and reasoning-induced hallucinations. This failure constitutes a significant issue and hinders the diagnosis of multimodal reasoning failures within MLLMs. To address this, we propose the {\dataset} benchmark, which isolates reasoning hallucinations by constructing questions where input images are correctly perceived by MLLMs yet reasoning errors persist. {\dataset} introduces multi-granular evaluation metrics: accuracy, factuality, and LLMs hallucination score for hallucination quantification. Our analysis reveals that (1) the model scale, data scale, and training stages significantly affect the degree of logical, fabrication, and factual hallucinations; (2) current MLLMs show no effective improvement on spatial hallucinations caused by misinterpreted spatial relationships, indicating their limited visual reasoning capabilities; and (3) question types correlate with distinct hallucination patterns, highlighting targeted challenges and potential mitigation strategies. To address these challenges, we propose {\method}, a method that combines curriculum reinforcement fine-tuning to encourage models to generate logic-consistent reasoning chains by stepwise reducing learning difficulty, and collaborative hint inference to reduce reasoning complexity. {\method} establishes a baseline on {\dataset}, and reduces the logical hallucinations in original base models.
Segmenting Objectiveness and Task-awareness Unknown Region for Autonomous Driving
Apr 27, 2025



With the emergence of transformer-based architectures and large language models (LLMs), the accuracy of road scene perception has substantially advanced. Nonetheless, current road scene segmentation approaches are predominantly trained on closed-set data, resulting in insufficient detection capabilities for out-of-distribution (OOD) objects. To overcome this limitation, road anomaly detection methods have been proposed. However, existing methods primarily depend on image inpainting and OOD distribution detection techniques, facing two critical issues: (1) inadequate consideration of the objectiveness attributes of anomalous regions, causing incomplete segmentation when anomalous objects share similarities with known classes, and (2) insufficient attention to environmental constraints, leading to the detection of anomalies irrelevant to autonomous driving tasks. In this paper, we propose a novel framework termed Segmenting Objectiveness and Task-Awareness (SOTA) for autonomous driving scenes. Specifically, SOTA enhances the segmentation of objectiveness through a Semantic Fusion Block (SFB) and filters anomalies irrelevant to road navigation tasks using a Scene-understanding Guided Prompt-Context Adaptor (SG-PCA). Extensive empirical evaluations on multiple benchmark datasets, including Fishyscapes Lost and Found, Segment-Me-If-You-Can, and RoadAnomaly, demonstrate that the proposed SOTA consistently improves OOD detection performance across diverse detectors, achieving robust and accurate segmentation outcomes.
MR-GDINO: Efficient Open-World Continual Object Detection
Dec 23, 2024



Open-world (OW) recognition and detection models show strong zero- and few-shot adaptation abilities, inspiring their use as initializations in continual learning methods to improve performance. Despite promising results on seen classes, such OW abilities on unseen classes are largely degenerated due to catastrophic forgetting. To tackle this challenge, we propose an open-world continual object detection task, requiring detectors to generalize to old, new, and unseen categories in continual learning scenarios. Based on this task, we present a challenging yet practical OW-COD benchmark to assess detection abilities. The goal is to motivate OW detectors to simultaneously preserve learned classes, adapt to new classes, and maintain open-world capabilities under few-shot adaptations. To mitigate forgetting in unseen categories, we propose MR-GDINO, a strong, efficient and scalable baseline via memory and retrieval mechanisms within a highly scalable memory pool. Experimental results show that existing continual detectors suffer from severe forgetting for both seen and unseen categories. In contrast, MR-GDINO largely mitigates forgetting with only 0.1% activated extra parameters, achieving state-of-the-art performance for old, new, and unseen categories.
Class Balance Matters to Active Class-Incremental Learning
Dec 09, 2024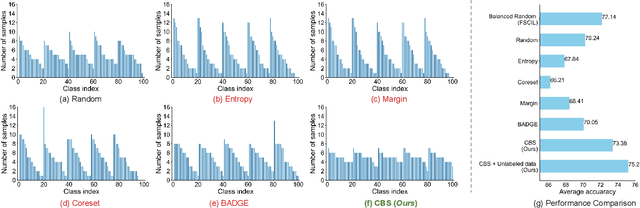
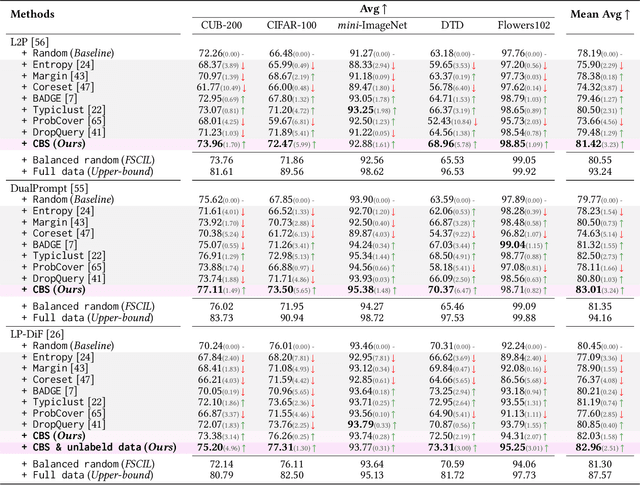

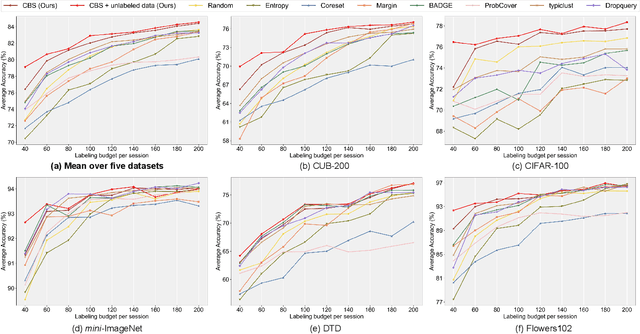
Few-Shot Class-Incremental Learning has shown remarkable efficacy in efficient learning new concepts with limited annotations. Nevertheless, the heuristic few-shot annotations may not always cover the most informative samples, which largely restricts the capability of incremental learner. We aim to start from a pool of large-scale unlabeled data and then annotate the most informative samples for incremental learning. Based on this premise, this paper introduces the Active Class-Incremental Learning (ACIL). The objective of ACIL is to select the most informative samples from the unlabeled pool to effectively train an incremental learner, aiming to maximize the performance of the resulting model. Note that vanilla active learning algorithms suffer from class-imbalanced distribution among annotated samples, which restricts the ability of incremental learning. To achieve both class balance and informativeness in chosen samples, we propose Class-Balanced Selection (CBS) strategy. Specifically, we first cluster the features of all unlabeled images into multiple groups. Then for each cluster, we employ greedy selection strategy to ensure that the Gaussian distribution of the sampled features closely matches the Gaussian distribution of all unlabeled features within the cluster. Our CBS can be plugged and played into those CIL methods which are based on pretrained models with prompts tunning technique. Extensive experiments under ACIL protocol across five diverse datasets demonstrate that CBS outperforms both random selection and other SOTA active learning approaches. Code is publicly available at https://github.com/1170300714/CBS.
InfiniteWorld: A Unified Scalable Simulation Framework for General Visual-Language Robot Interaction
Dec 08, 2024


Realizing scaling laws in embodied AI has become a focus. However, previous work has been scattered across diverse simulation platforms, with assets and models lacking unified interfaces, which has led to inefficiencies in research. To address this, we introduce InfiniteWorld, a unified and scalable simulator for general vision-language robot interaction built on Nvidia Isaac Sim. InfiniteWorld encompasses a comprehensive set of physics asset construction methods and generalized free robot interaction benchmarks. Specifically, we first built a unified and scalable simulation framework for embodied learning that integrates a series of improvements in generation-driven 3D asset construction, Real2Sim, automated annotation framework, and unified 3D asset processing. This framework provides a unified and scalable platform for robot interaction and learning. In addition, to simulate realistic robot interaction, we build four new general benchmarks, including scene graph collaborative exploration and open-world social mobile manipulation. The former is often overlooked as an important task for robots to explore the environment and build scene knowledge, while the latter simulates robot interaction tasks with different levels of knowledge agents based on the former. They can more comprehensively evaluate the embodied agent's capabilities in environmental understanding, task planning and execution, and intelligent interaction. We hope that this work can provide the community with a systematic asset interface, alleviate the dilemma of the lack of high-quality assets, and provide a more comprehensive evaluation of robot interactions.