 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentSPEX: An Agent SPecification and EXecution Language
Apr 14, 2026Language-model agent systems commonly rely on reactive prompting, in which a single instruction guides the model through an open-ended sequence of reasoning and tool-use steps, leaving control flow and intermediate state implicit and making agent behavior potentially difficult to control. Orchestration frameworks such as LangGraph, DSPy, and CrewAI impose greater structure through explicit workflow definitions, but tightly couple workflow logic with Python, making agents difficult to maintain and modify. In this paper, we introduce AgentSPEX, an Agent SPecification and EXecution Language for specifying LLM-agent workflows with explicit control flow and modular structure, along with a customizable agent harness. AgentSPEX supports typed steps, branching and loops, parallel execution, reusable submodules, and explicit state management, and these workflows execute within an agent harness that provides tool access, a sandboxed virtual environment, and support for checkpointing, verification, and logging. Furthermore, we provide a visual editor with synchronized graph and workflow views for authoring and inspection. We include ready-to-use agents for deep research and scientific research, and we evaluate AgentSPEX on 7 benchmarks. Finally, we show through a user study that AgentSPEX provides a more interpretable and accessible workflow-authoring paradigm than a popular existing agent framework.
PhaForce: Phase-Scheduled Visual-Force Policy Learning with Slow Planning and Fast Correction for Contact-Rich Manipulation
Mar 09, 2026Contact-rich manipulation requires not only vision-dominant task semantics but also closed-loop reactions to force/torque (F/T) transients. Yet, generative visuomotor policies are typically constrained to low-frequency updates due to inference latency and action chunking, underutilizing F/T for control-rate feedback. Furthermore, existing force-aware methods often inject force continuously and indiscriminately, lacking an explicit mechanism to schedule when / how much / where to apply force across different task phases. We propose PhaForce, a phase-scheduled visual--force policy that coordinates low-rate chunk-level planning and high-rate residual correction via a unified contact/phase schedule. PhaForce comprises (i) a contact-aware phase predictor (CAP) that estimates contact probability and phase belief, (ii) a Slow diffusion planner that performs dual-gated visual--force fusion with orthogonal residual injection to preserve vision semantics while conditioning on force, and (iii) a Fast corrector that applies control-rate phase-routed residuals in interpretable corrective subspaces for within-chunk micro-adjustments. Across multiple real-robot contact-rich tasks, PhaForce achieves an average success rate of 86% (+40 pp over baselines), while also substantially improving contact quality by regulating interaction forces and exhibiting robust adaptability to OOD geometric shifts.
High-Quality Proposal Encoding and Cascade Denoising for Imaginary Supervised Object Detection
Nov 11, 2025Object detection models demand large-scale annotated datasets, which are costly and labor-intensive to create. This motivated Imaginary Supervised Object Detection (ISOD), where models train on synthetic images and test on real images. However, existing methods face three limitations: (1) synthetic datasets suffer from simplistic prompts, poor image quality, and weak supervision; (2) DETR-based detectors, due to their random query initialization, struggle with slow convergence and overfitting to synthetic patterns, hindering real-world generalization; (3) uniform denoising pressure promotes model overfitting to pseudo-label noise. We propose Cascade HQP-DETR to address these limitations. First, we introduce a high-quality data pipeline using LLaMA-3, Flux, and Grounding DINO to generate the FluxVOC and FluxCOCO datasets, advancing ISOD from weak to full supervision. Second, our High-Quality Proposal guided query encoding initializes object queries with image-specific priors from SAM-generated proposals and RoI-pooled features, accelerating convergence while steering the model to learn transferable features instead of overfitting to synthetic patterns. Third, our cascade denoising algorithm dynamically adjusts training weights through progressively increasing IoU thresholds across decoder layers, guiding the model to learn robust boundaries from reliable visual cues rather than overfitting to noisy labels. Trained for just 12 epochs solely on FluxVOC, Cascade HQP-DETR achieves a SOTA 61.04\% mAP@0.5 on PASCAL VOC 2007, outperforming strong baselines, with its competitive real-data performance confirming the architecture's universal applicability.
Dual-Thresholding Heatmaps to Cluster Proposals for Weakly Supervised Object Detection
Sep 10, 2025



Weakly supervised object detection (WSOD) has attracted significant attention in recent years, as it does not require box-level annotations. State-of-the-art methods generally adopt a multi-module network, which employs WSDDN as the multiple instance detection network module and multiple instance refinement modules to refine performance. However, these approaches suffer from three key limitations. First, existing methods tend to generate pseudo GT boxes that either focus only on discriminative parts, failing to capture the whole object, or cover the entire object but fail to distinguish between adjacent intra-class instances. Second, the foundational WSDDN architecture lacks a crucial background class representation for each proposal and exhibits a large semantic gap between its branches. Third, prior methods discard ignored proposals during optimization, leading to slow convergence. To address these challenges, we first design a heatmap-guided proposal selector (HGPS) algorithm, which utilizes dual thresholds on heatmaps to pre-select proposals, enabling pseudo GT boxes to both capture the full object extent and distinguish between adjacent intra-class instances. We then present a weakly supervised basic detection network (WSBDN), which augments each proposal with a background class representation and uses heatmaps for pre-supervision to bridge the semantic gap between matrices. At last, we introduce a negative certainty supervision loss on ignored proposals to accelerate convergence. Extensive experiments on the challenging PASCAL VOC 2007 and 2012 datasets demonstrate the effectiveness of our framework. We achieve mAP/mCorLoc scores of 58.5%/81.8% on VOC 2007 and 55.6%/80.5% on VOC 2012, performing favorably against the state-of-the-art WSOD methods. Our code is publicly available at https://github.com/gyl2565309278/DTH-CP.
Steerable Pyramid Weighted Loss: Multi-Scale Adaptive Weighting for Semantic Segmentation
Mar 09, 2025Semantic segmentation is a core task in computer vision with applications in biomedical imaging, remote sensing, and autonomous driving. While standard loss functions such as cross-entropy and Dice loss perform well in general cases, they often struggle with fine structures, particularly in tasks involving thin structures or closely packed objects. Various weight map-based loss functions have been proposed to address this issue by assigning higher loss weights to pixels prone to misclassification. However, these methods typically rely on precomputed or runtime-generated weight maps based on distance transforms, which impose significant computational costs and fail to adapt to evolving network predictions. In this paper, we propose a novel steerable pyramid-based weighted (SPW) loss function that efficiently generates adaptive weight maps. Unlike traditional boundary-aware losses that depend on static or iteratively updated distance maps, our method leverages steerable pyramids to dynamically emphasize regions across multiple frequency bands (capturing features at different scales) while maintaining computational efficiency. Additionally, by incorporating network predictions into the weight computation, our approach enables adaptive refinement during training. We evaluate our method on the SNEMI3D, GlaS, and DRIVE datasets, benchmarking it against 11 state-of-the-art loss functions. Our results demonstrate that the proposed SPW loss function achieves superior pixel precision and segmentation accuracy with minimal computational overhead. This work provides an effective and efficient solution for improving semantic segmentation, particularly for applications requiring multiscale feature representation. The code is avaiable at https://anonymous.4open.science/r/SPW-0884
Offline Goal-Conditioned Reinforcement Learning for Safety-Critical Tasks with Recovery Policy
Mar 04, 2024Offline goal-conditioned reinforcement learning (GCRL) aims at solving goal-reaching tasks with sparse rewards from an offline dataset. While prior work has demonstrated various approaches for agents to learn near-optimal policies, these methods encounter limitations when dealing with diverse constraints in complex environments, such as safety constraints. Some of these approaches prioritize goal attainment without considering safety, while others excessively focus on safety at the expense of training efficiency. In this paper, we study the problem of constrained offline GCRL and propose a new method called Recovery-based Supervised Learning (RbSL) to accomplish safety-critical tasks with various goals. To evaluate the method performance, we build a benchmark based on the robot-fetching environment with a randomly positioned obstacle and use expert or random policies to generate an offline dataset. We compare RbSL with three offline GCRL algorithms and one offline safe RL algorithm. As a result, our method outperforms the existing state-of-the-art methods to a large extent. Furthermore, we validate the practicality and effectiveness of RbSL by deploying it on a real Panda manipulator. Code is available at https://github.com/Sunlighted/RbSL.git.
Auction Based Clustered Federated Learning in Mobile Edge Computing System
Mar 12, 2021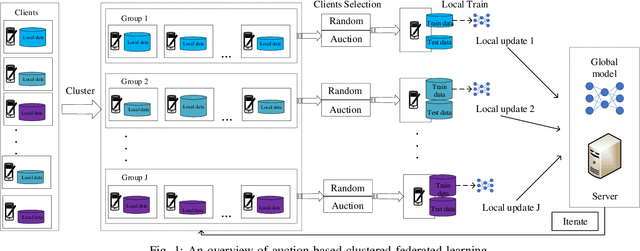
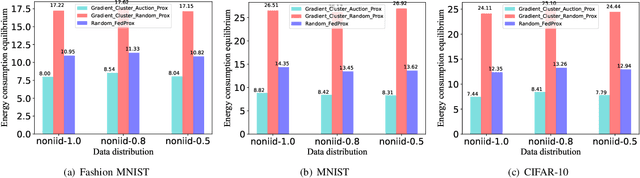
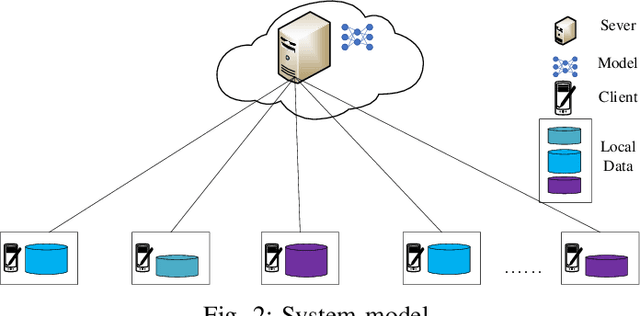
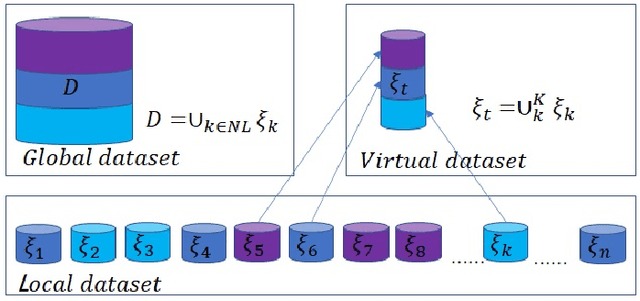
In recent years, mobile clients' computing ability and storage capacity have greatly improved, efficiently dealing with some applications locally. Federated learning is a promising distributed machine learning solution that uses local computing and local data to train the Artificial Intelligence (AI) model. Combining local computing and federated learning can train a powerful AI model under the premise of ensuring local data privacy while making full use of mobile clients' resources. However, the heterogeneity of local data, that is, Non-independent and identical distribution (Non-IID) and imbalance of local data size, may bring a bottleneck hindering the application of federated learning in mobile edge computing (MEC) system. Inspired by this, we propose a cluster-based clients selection method that can generate a federated virtual dataset that satisfies the global distribution to offset the impact of data heterogeneity and proved that the proposed scheme could converge to an approximate optimal solution. Based on the clustering method, we propose an auction-based clients selection scheme within each cluster that fully considers the system's energy heterogeneity and gives the Nash equilibrium solution of the proposed scheme for balance the energy consumption and improving the convergence rate. The simulation results show that our proposed selection methods and auction-based federated learning can achieve better performance with the Convolutional Neural Network model (CNN) under different data distributions.