 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Quality Proposal Encoding and Cascade Denoising for Imaginary Supervised Object Detection
Nov 11, 2025Object detection models demand large-scale annotated datasets, which are costly and labor-intensive to create. This motivated Imaginary Supervised Object Detection (ISOD), where models train on synthetic images and test on real images. However, existing methods face three limitations: (1) synthetic datasets suffer from simplistic prompts, poor image quality, and weak supervision; (2) DETR-based detectors, due to their random query initialization, struggle with slow convergence and overfitting to synthetic patterns, hindering real-world generalization; (3) uniform denoising pressure promotes model overfitting to pseudo-label noise. We propose Cascade HQP-DETR to address these limitations. First, we introduce a high-quality data pipeline using LLaMA-3, Flux, and Grounding DINO to generate the FluxVOC and FluxCOCO datasets, advancing ISOD from weak to full supervision. Second, our High-Quality Proposal guided query encoding initializes object queries with image-specific priors from SAM-generated proposals and RoI-pooled features, accelerating convergence while steering the model to learn transferable features instead of overfitting to synthetic patterns. Third, our cascade denoising algorithm dynamically adjusts training weights through progressively increasing IoU thresholds across decoder layers, guiding the model to learn robust boundaries from reliable visual cues rather than overfitting to noisy labels. Trained for just 12 epochs solely on FluxVOC, Cascade HQP-DETR achieves a SOTA 61.04\% mAP@0.5 on PASCAL VOC 2007, outperforming strong baselines, with its competitive real-data performance confirming the architecture's universal applicability.
Dual-Thresholding Heatmaps to Cluster Proposals for Weakly Supervised Object Detection
Sep 10, 2025



Weakly supervised object detection (WSOD) has attracted significant attention in recent years, as it does not require box-level annotations. State-of-the-art methods generally adopt a multi-module network, which employs WSDDN as the multiple instance detection network module and multiple instance refinement modules to refine performance. However, these approaches suffer from three key limitations. First, existing methods tend to generate pseudo GT boxes that either focus only on discriminative parts, failing to capture the whole object, or cover the entire object but fail to distinguish between adjacent intra-class instances. Second, the foundational WSDDN architecture lacks a crucial background class representation for each proposal and exhibits a large semantic gap between its branches. Third, prior methods discard ignored proposals during optimization, leading to slow convergence. To address these challenges, we first design a heatmap-guided proposal selector (HGPS) algorithm, which utilizes dual thresholds on heatmaps to pre-select proposals, enabling pseudo GT boxes to both capture the full object extent and distinguish between adjacent intra-class instances. We then present a weakly supervised basic detection network (WSBDN), which augments each proposal with a background class representation and uses heatmaps for pre-supervision to bridge the semantic gap between matrices. At last, we introduce a negative certainty supervision loss on ignored proposals to accelerate convergence. Extensive experiments on the challenging PASCAL VOC 2007 and 2012 datasets demonstrate the effectiveness of our framework. We achieve mAP/mCorLoc scores of 58.5%/81.8% on VOC 2007 and 55.6%/80.5% on VOC 2012, performing favorably against the state-of-the-art WSOD methods. Our code is publicly available at https://github.com/gyl2565309278/DTH-CP.
Membership Inference Attack with Partial Features
Aug 08, 2025



Machine learning models have been shown to be susceptible to membership inference attack, which can be used to determine whether a given sample appears in the training data. Existing membership inference methods commonly assume that the adversary has full access to the features of the target sample. This assumption, however, does not hold in many real-world scenarios where only partial features information is available, thereby limiting the applicability of these methods. In this work, we study an inference scenario where the adversary observes only partial features of each sample and aims to infer whether this observed subset was present in the training set of the target model. We define this problem as Partial Feature Membership Inference (PFMI). To address this problem, we propose MRAD (Memory-guided Reconstruction and Anomaly Detection), a two-stage attack framework. In the first stage, MRAD optimizes the unknown feature values to minimize the loss of the sample. In the second stage, it measures the deviation between the reconstructed sample and the training distribution using anomaly detection. Empirical results demonstrate that MRAD is effective across a range of datasets, and maintains compatibility with various off-the-shelf anomaly detection techniques. For example, on STL-10, our attack achieves an AUC of around 0.6 even with 40% of the missing features.
Circumventing Backdoor Space via Weight Symmetry
Jun 09, 2025Deep neural networks are vulnerable to backdoor attacks, where malicious behaviors are implanted during training. While existing defenses can effectively purify compromised models, they typically require labeled data or specific training procedures, making them difficult to apply beyond supervised learning settings. Notably, recent studies have shown successful backdoor attacks across various learning paradigms, highlighting a critical security concern. To address this gap, we propose Two-stage Symmetry Connectivity (TSC), a novel backdoor purification defense that operates independently of data format and requires only a small fraction of clean samples. Through theoretical analysis, we prove that by leveraging permutation invariance in neural networks and quadratic mode connectivity, TSC amplifies the loss on poisoned samples while maintaining bounded clean accuracy. Experiments demonstrate that TSC achieves robust performance comparable to state-of-the-art methods in supervised learning scenarios. Furthermore, TSC generalizes to self-supervised learning frameworks, such as SimCLR and CLIP, maintaining its strong defense capabilities. Our code is available at https://github.com/JiePeng104/TSC.
Multimodal Online Federated Learning with Modality Missing in Internet of Things
May 22, 2025The Internet of Things (IoT) ecosystem generates vast amounts of multimodal data from heterogeneous sources such as sensors, cameras, and microphones. As edge intelligence continues to evolve, IoT devices have progressed from simple data collection units to nodes capable of executing complex computational tasks. This evolution necessitates the adoption of distributed learning strategies to effectively handle multimodal data in an IoT environment. Furthermore, the real-time nature of data collection and limited local storage on edge devices in IoT call for an online learning paradigm. To address these challenges, we introduce the concept of Multimodal Online Federated Learning (MMO-FL), a novel framework designed for dynamic and decentralized multimodal learning in IoT environments. Building on this framework, we further account for the inherent instability of edge devices, which frequently results in missing modalities during the learning process. We conduct a comprehensive theoretical analysis under both complete and missing modality scenarios, providing insights into the performance degradation caused by missing modalities. To mitigate the impact of modality missing, we propose the Prototypical Modality Mitigation (PMM) algorithm, which leverages prototype learning to effectively compensate for missing modalities. Experimental results on two multimodal datasets further demonstrate the superior performance of PMM compared to benchmarks.
AudioJailbreak: Jailbreak Attacks against End-to-End Large Audio-Language Models
May 21, 2025



Jailbreak attacks to Large audio-language models (LALMs) are studied recently, but they achieve suboptimal effectiveness, applicability, and practicability, particularly, assuming that the adversary can fully manipulate user prompts. In this work, we first conduct an extensive experiment showing that advanced text jailbreak attacks cannot be easily ported to end-to-end LALMs via text-to speech (TTS) techniques. We then propose AudioJailbreak, a novel audio jailbreak attack, featuring (1) asynchrony: the jailbreak audio does not need to align with user prompts in the time axis by crafting suffixal jailbreak audios; (2) universality: a single jailbreak perturbation is effective for different prompts by incorporating multiple prompts into perturbation generation; (3) stealthiness: the malicious intent of jailbreak audios will not raise the awareness of victims by proposing various intent concealment strategies; and (4) over-the-air robustness: the jailbreak audios remain effective when being played over the air by incorporating the reverberation distortion effect with room impulse response into the generation of the perturbations. In contrast, all prior audio jailbreak attacks cannot offer asynchrony, universality, stealthiness, or over-the-air robustness. Moreover, AudioJailbreak is also applicable to the adversary who cannot fully manipulate user prompts, thus has a much broader attack scenario. Extensive experiments with thus far the most LALMs demonstrate the high effectiveness of AudioJailbreak. We highlight that our work peeks into the security implications of audio jailbreak attacks against LALMs, and realistically fosters improving their security robustness. The implementation and audio samples are available at our website https://audiojailbreak.github.io/AudioJailbreak.
Denoising and Adaptive Online Vertical Federated Learning for Sequential Multi-Sensor Data in Industrial Internet of Things
Jan 03, 2025



With the continuous improvement in the computational capabilities of edge devices such as intelligent sensors in the Industrial Internet of Things, these sensors are no longer limited to mere data collection but are increasingly capable of performing complex computational tasks. This advancement provides both the motivation and the foundation for adopting distributed learning approaches. This study focuses on an industrial assembly line scenario where multiple sensors, distributed across various locations, sequentially collect real-time data characterized by distinct feature spaces. To leverage the computational potential of these sensors while addressing the challenges of communication overhead and privacy concerns inherent in centralized learning, we propose the Denoising and Adaptive Online Vertical Federated Learning (DAO-VFL) algorithm. Tailored to the industrial assembly line scenario, DAO-VFL effectively manages continuous data streams and adapts to shifting learning objectives. Furthermore, it can address critical challenges prevalent in industrial environment, such as communication noise and heterogeneity of sensor capabilities. To support the proposed algorithm, we provide a comprehensive theoretical analysis, highlighting the effects of noise reduction and adaptive local iteration decisions on the regret bound. Experimental results on two real-world datasets further demonstrate the superior performance of DAO-VFL compared to benchmarks algorithms.
How to Bridge Spatial and Temporal Heterogeneity in Link Prediction? A Contrastive Method
Nov 01, 2024


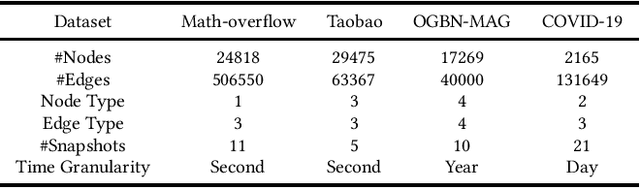
Temporal Heterogeneous Networks play a crucial role in capturing the dynamics and heterogeneity inherent in various real-world complex systems, rendering them a noteworthy research avenue for link prediction. However, existing methods fail to capture the fine-grained differential distribution patterns and temporal dynamic characteristics, which we refer to as spatial heterogeneity and temporal heterogeneity. To overcome such limitations, we propose a novel \textbf{C}ontrastive Learning-based \textbf{L}ink \textbf{P}rediction model, \textbf{CLP}, which employs a multi-view hierarchical self-supervised architecture to encode spatial and temporal heterogeneity. Specifically, aiming at spatial heterogeneity, we develop a spatial feature modeling layer to capture the fine-grained topological distribution patterns from node- and edge-level representations, respectively. Furthermore, aiming at temporal heterogeneity, we devise a temporal information modeling layer to perceive the evolutionary dependencies of dynamic graph topologies from time-level representations. Finally, we encode the spatial and temporal distribution heterogeneity from a contrastive learning perspective, enabling a comprehensive self-supervised hierarchical relation modeling for the link prediction task. Extensive experiments conducted on four real-world dynamic heterogeneous network datasets verify that our \mymodel consistently outperforms the state-of-the-art models, demonstrating an average improvement of 10.10\%, 13.44\% in terms of AUC and AP, respectively.
DIP: Diffusion Learning of Inconsistency Pattern for General DeepFake Detection
Oct 31, 2024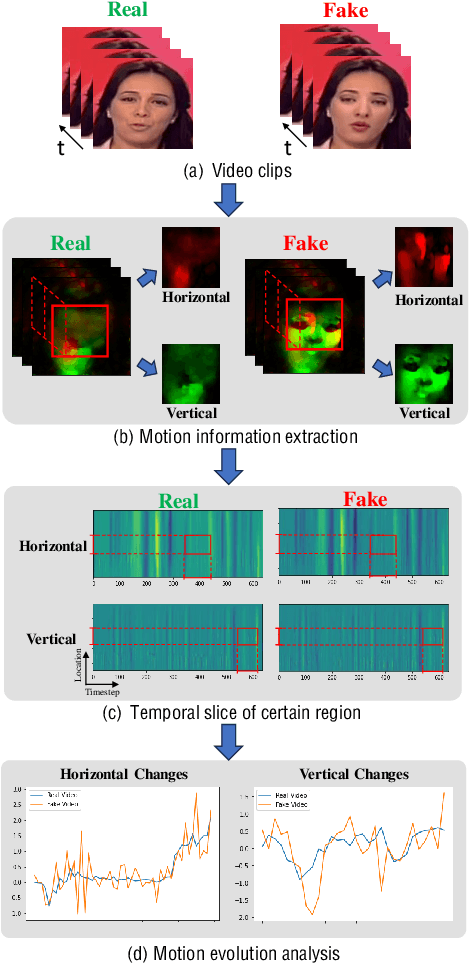

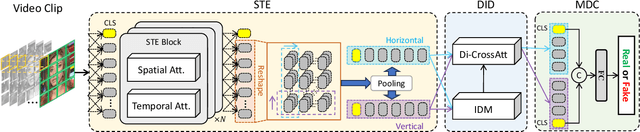
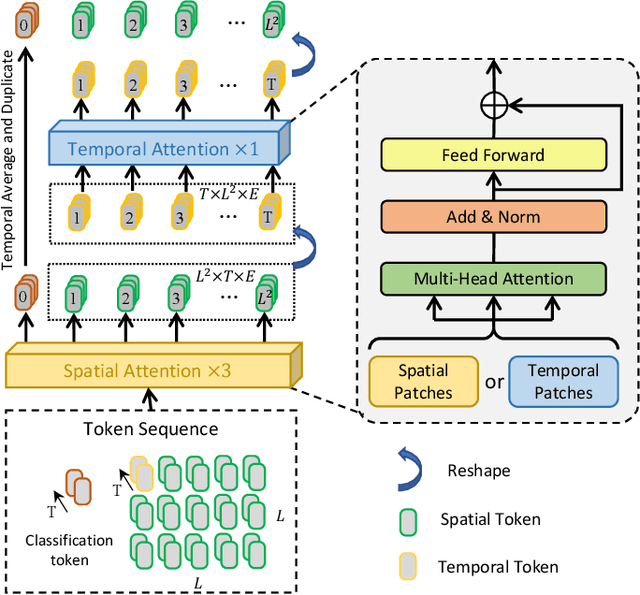
With the advancement of deepfake generation techniques, the importance of deepfake detection in protecting multimedia content integrity has become increasingly obvious. Recently, temporal inconsistency clues have been explored to improve the generalizability of deepfake video detection. According to our observation, the temporal artifacts of forged videos in terms of motion information usually exhibits quite distinct inconsistency patterns along horizontal and vertical directions, which could be leveraged to improve the generalizability of detectors. In this paper, a transformer-based framework for Diffusion Learning of Inconsistency Pattern (DIP) is proposed, which exploits directional inconsistencies for deepfake video detection. Specifically, DIP begins with a spatiotemporal encoder to represent spatiotemporal information. A directional inconsistency decoder is adopted accordingly, where direction-aware attention and inconsistency diffusion are incorporated to explore potential inconsistency patterns and jointly learn the inherent relationships. In addition, the SpatioTemporal Invariant Loss (STI Loss) is introduced to contrast spatiotemporally augmented sample pairs and prevent the model from overfitting nonessential forgery artifacts. Extensive experiments on several public datasets demonstrate that our method could effectively identify directional forgery clues and achieve state-of-the-art performance.
Towards Bridging the Cross-modal Semantic Gap for Multi-modal Recommendation
Jul 07, 2024Multi-modal recommendation greatly enhances the performance of recommender systems by modeling the auxiliary information from multi-modality contents. Most existing multi-modal recommendation models primarily exploit multimedia information propagation processes to enrich item representations and directly utilize modal-specific embedding vectors independently obtained from upstream pre-trained models. However, this might be inappropriate since the abundant task-specific semantics remain unexplored, and the cross-modality semantic gap hinders the recommendation performance. Inspired by the recent progress of the cross-modal alignment model CLIP, in this paper, we propose a novel \textbf{CLIP} \textbf{E}nhanced \textbf{R}ecommender (\textbf{CLIPER}) framework to bridge the semantic gap between modalities and extract fine-grained multi-view semantic information. Specifically, we introduce a multi-view modality-alignment approach for representation extraction and measure the semantic similarity between modalities. Furthermore, we integrate the multi-view multimedia representations into downstream recommendation models. Extensive experiments conducted on three public datasets demonstrate the consistent superiority of our model over state-of-the-art multi-modal recommendation models.