 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeniMV: A Multi-view Benchmark for Meniscus Injury Severity Grading
Dec 20, 2025Precise grading of meniscal horn tears is critical in knee injury diagnosis but remains underexplored in automated MRI analysis. Existing methods often rely on coarse study-level labels or binary classification, lacking localization and severity information. In this paper, we introduce MeniMV, a multi-view benchmark dataset specifically designed for horn-specific meniscus injury grading. MeniMV comprises 3,000 annotated knee MRI exams from 750 patients across three medical centers, providing 6,000 co-registered sagittal and coronal images. Each exam is meticulously annotated with four-tier (grade 0-3) severity labels for both anterior and posterior meniscal horns, verified by chief orthopedic physicians. Notably, MeniMV offers more than double the pathology-labeled data volume of prior datasets while uniquely capturing the dual-view diagnostic context essential in clinical practice. To demonstrate the utility of MeniMV, we benchmark multiple state-of-the-art CNN and Transformer-based models. Our extensive experiments establish strong baselines and highlight challenges in severity grading, providing a valuable foundation for future research in automated musculoskeletal imaging.
Circumventing Backdoor Space via Weight Symmetry
Jun 09, 2025Deep neural networks are vulnerable to backdoor attacks, where malicious behaviors are implanted during training. While existing defenses can effectively purify compromised models, they typically require labeled data or specific training procedures, making them difficult to apply beyond supervised learning settings. Notably, recent studies have shown successful backdoor attacks across various learning paradigms, highlighting a critical security concern. To address this gap, we propose Two-stage Symmetry Connectivity (TSC), a novel backdoor purification defense that operates independently of data format and requires only a small fraction of clean samples. Through theoretical analysis, we prove that by leveraging permutation invariance in neural networks and quadratic mode connectivity, TSC amplifies the loss on poisoned samples while maintaining bounded clean accuracy. Experiments demonstrate that TSC achieves robust performance comparable to state-of-the-art methods in supervised learning scenarios. Furthermore, TSC generalizes to self-supervised learning frameworks, such as SimCLR and CLIP, maintaining its strong defense capabilities. Our code is available at https://github.com/JiePeng104/TSC.
How to Bridge Spatial and Temporal Heterogeneity in Link Prediction? A Contrastive Method
Nov 01, 2024


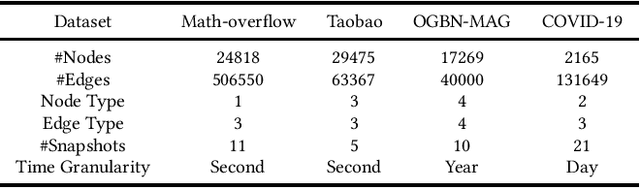
Temporal Heterogeneous Networks play a crucial role in capturing the dynamics and heterogeneity inherent in various real-world complex systems, rendering them a noteworthy research avenue for link prediction. However, existing methods fail to capture the fine-grained differential distribution patterns and temporal dynamic characteristics, which we refer to as spatial heterogeneity and temporal heterogeneity. To overcome such limitations, we propose a novel \textbf{C}ontrastive Learning-based \textbf{L}ink \textbf{P}rediction model, \textbf{CLP}, which employs a multi-view hierarchical self-supervised architecture to encode spatial and temporal heterogeneity. Specifically, aiming at spatial heterogeneity, we develop a spatial feature modeling layer to capture the fine-grained topological distribution patterns from node- and edge-level representations, respectively. Furthermore, aiming at temporal heterogeneity, we devise a temporal information modeling layer to perceive the evolutionary dependencies of dynamic graph topologies from time-level representations. Finally, we encode the spatial and temporal distribution heterogeneity from a contrastive learning perspective, enabling a comprehensive self-supervised hierarchical relation modeling for the link prediction task. Extensive experiments conducted on four real-world dynamic heterogeneous network datasets verify that our \mymodel consistently outperforms the state-of-the-art models, demonstrating an average improvement of 10.10\%, 13.44\% in terms of AUC and AP, respectively.
Towards Bridging the Cross-modal Semantic Gap for Multi-modal Recommendation
Jul 07, 2024Multi-modal recommendation greatly enhances the performance of recommender systems by modeling the auxiliary information from multi-modality contents. Most existing multi-modal recommendation models primarily exploit multimedia information propagation processes to enrich item representations and directly utilize modal-specific embedding vectors independently obtained from upstream pre-trained models. However, this might be inappropriate since the abundant task-specific semantics remain unexplored, and the cross-modality semantic gap hinders the recommendation performance. Inspired by the recent progress of the cross-modal alignment model CLIP, in this paper, we propose a novel \textbf{CLIP} \textbf{E}nhanced \textbf{R}ecommender (\textbf{CLIPER}) framework to bridge the semantic gap between modalities and extract fine-grained multi-view semantic information. Specifically, we introduce a multi-view modality-alignment approach for representation extraction and measure the semantic similarity between modalities. Furthermore, we integrate the multi-view multimedia representations into downstream recommendation models. Extensive experiments conducted on three public datasets demonstrate the consistent superiority of our model over state-of-the-art multi-modal recommendation models.