 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIP: Diffusion Learning of Inconsistency Pattern for General DeepFake Detection
Paper and Code
Oct 31, 2024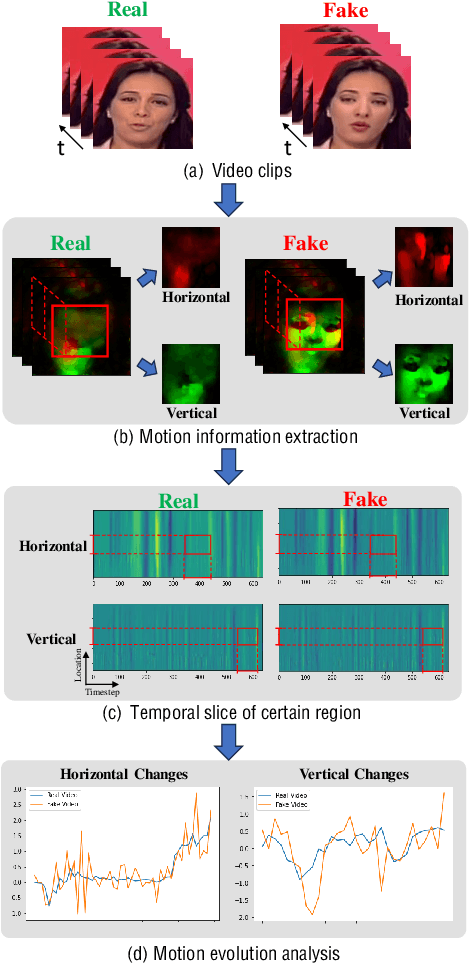

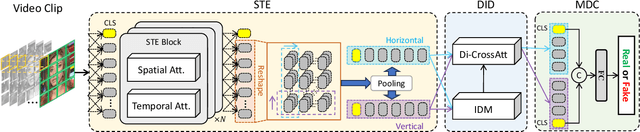
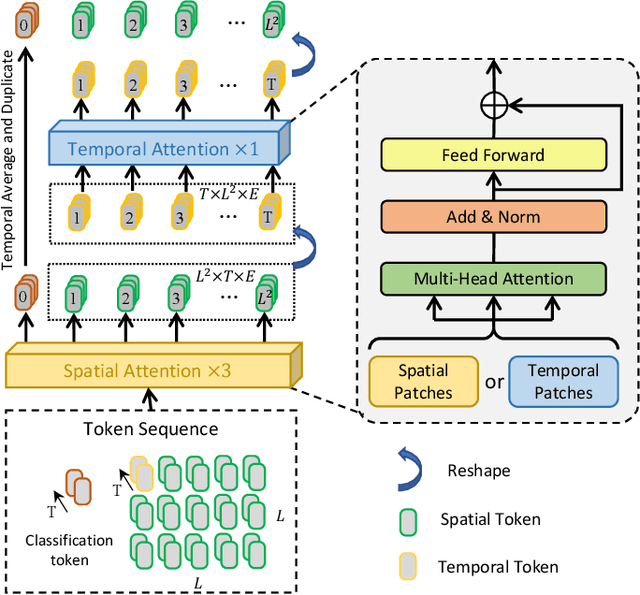
With the advancement of deepfake generation techniques, the importance of deepfake detection in protecting multimedia content integrity has become increasingly obvious. Recently, temporal inconsistency clues have been explored to improve the generalizability of deepfake video detection. According to our observation, the temporal artifacts of forged videos in terms of motion information usually exhibits quite distinct inconsistency patterns along horizontal and vertical directions, which could be leveraged to improve the generalizability of detectors. In this paper, a transformer-based framework for Diffusion Learning of Inconsistency Pattern (DIP) is proposed, which exploits directional inconsistencies for deepfake video detection. Specifically, DIP begins with a spatiotemporal encoder to represent spatiotemporal information. A directional inconsistency decoder is adopted accordingly, where direction-aware attention and inconsistency diffusion are incorporated to explore potential inconsistency patterns and jointly learn the inherent relationships. In addition, the SpatioTemporal Invariant Loss (STI Loss) is introduced to contrast spatiotemporally augmented sample pairs and prevent the model from overfitting nonessential forgery artifacts. Extensive experiments on several public datasets demonstrate that our method could effectively identify directional forgery clues and achieve state-of-the-art performance.