 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnable Lightweight and Precision-Scalable Posit/IEEE-754 Arithmetic in RISC-V Cores for Transprecision Computing
May 25, 2025While posit format offers superior dynamic range and accuracy for transprecision computing, its adoption in RISC-V processors is hindered by the lack of a unified solution for lightweight, precision-scalable, and IEEE-754 arithmetic compatible hardware implementation. To address these challenges, we enhance RISC-V processors by 1) integrating dedicated posit codecs into the original FPU for lightweight implementation, 2) incorporating multi/mixed-precision support with dynamic exponent size for precision-scalability, and 3) reusing and customizing ISA extensions for IEEE-754 compatible posit operations. Our comprehensive evaluation spans the modified FPU, RISC-V core, and SoC levels. It demonstrates that our implementation achieves 47.9% LUTs and 57.4% FFs reduction compared to state-of-the-art posit-enabled RISC-V processors, while achieving up to 2.54$\times$ throughput improvement in various GEMM kernels.
Towards More Efficient Depression Risk Recognition via Gait
Oct 10, 2023



Depression, a highly prevalent mental illness, affects over 280 million individuals worldwide. Early detection and timely intervention are crucial for promoting remission, preventing relapse, and alleviating the emotional and financial burdens associated with depression. However, patients with depression often go undiagnosed in the primary care setting. Unlike many physiological illnesses, depression lacks objective indicators for recognizing depression risk, and existing methods for depression risk recognition are time-consuming and often encounter a shortage of trained medical professionals. The correlation between gait and depression risk has been empirically established. Gait can serve as a promising objective biomarker, offering the advantage of efficient and convenient data collection. However, current methods for recognizing depression risk based on gait have only been validated on small, private datasets, lacking large-scale publicly available datasets for research purposes. Additionally, these methods are primarily limited to hand-crafted approaches. Gait is a complex form of motion, and hand-crafted gait features often only capture a fraction of the intricate associations between gait and depression risk. Therefore, this study first constructs a large-scale gait database, encompassing over 1,200 individuals, 40,000 gait sequences, and covering six perspectives and three types of attire. Two commonly used psychological scales are provided as depression risk annotations. Subsequently, a deep learning-based depression risk recognition model is proposed, overcoming the limitations of hand-crafted approaches. Through experiments conducted on the constructed large-scale database, the effectiveness of the proposed method is validated, and numerous instructive insights are presented in the paper, highlighting the significant potential of gait-based depression risk recognition.
Unidirectional brain-computer interface: Artificial neural network encoding natural images to fMRI response in the visual cortex
Sep 26, 2023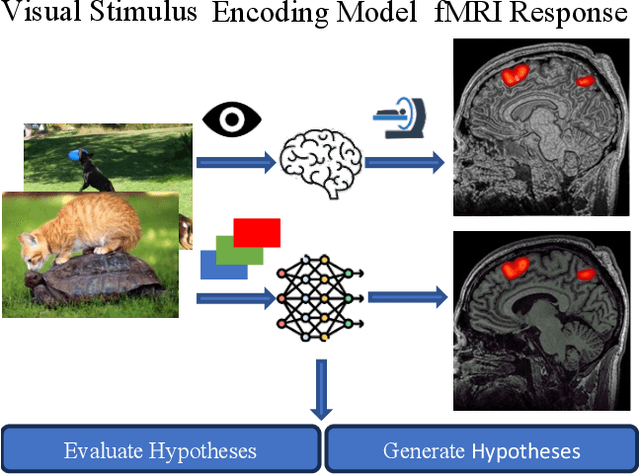

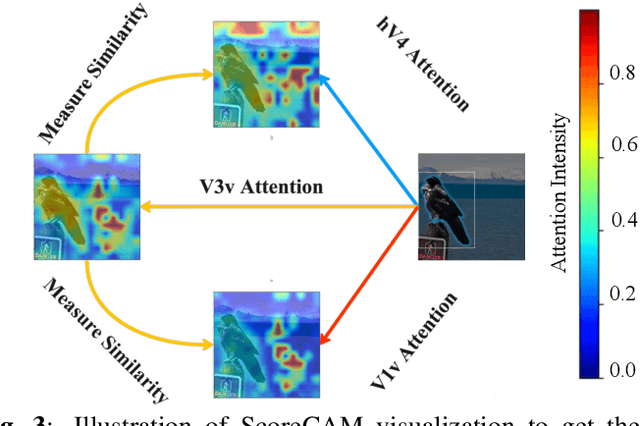
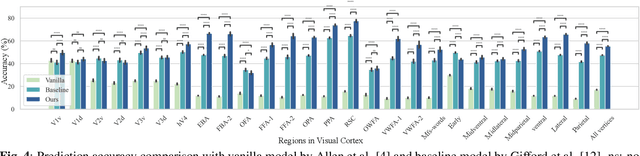
While significant advancements in artificial intelligence (AI) have catalyzed progress across various domains, its full potential in understanding visual perception remains underexplored. We propose an artificial neural network dubbed VISION, an acronym for "Visual Interface System for Imaging Output of Neural activity," to mimic the human brain and show how it can foster neuroscientific inquiries. Using visual and contextual inputs, this multimodal model predicts the brain's functional magnetic resonance imaging (fMRI) scan response to natural images. VISION successfully predicts human hemodynamic responses as fMRI voxel values to visual inputs with an accuracy exceeding state-of-the-art performance by 45%. We further probe the trained networks to reveal representational biases in different visual areas, generate experimentally testable hypotheses, and formulate an interpretable metric to associate these hypotheses with cortical functions. With both a model and evaluation metric, the cost and time burdens associated with designing and implementing functional analysis on the visual cortex could be reduced. Our work suggests that the evolution of computational models may shed light on our fundamental understanding of the visual cortex and provide a viable approach toward reliable brain-machine interfaces.
A Precision-Scalable RISC-V DNN Processor with On-Device Learning Capability at the Extreme Edge
Sep 15, 2023Extreme edge platforms, such as in-vehicle smart devices, require efficient deployment of quantized deep neural networks (DNNs) to enable intelligent applications with limited amounts of energy, memory, and computing resources. However, many edge devices struggle to boost inference throughput of various quantized DNNs due to the varying quantization levels, and these devices lack floating-point (FP) support for on-device learning, which prevents them from improving model accuracy while ensuring data privacy. To tackle the challenges above, we propose a precision-scalable RISC-V DNN processor with on-device learning capability. It facilitates diverse precision levels of fixed-point DNN inference, spanning from 2-bit to 16-bit, and enhances on-device learning through improved support with FP16 operations. Moreover, we employ multiple methods such as FP16 multiplier reuse and multi-precision integer multiplier reuse, along with balanced mapping of FPGA resources, to significantly improve hardware resource utilization. Experimental results on the Xilinx ZCU102 FPGA show that our processor significantly improves inference throughput by 1.6$\sim$14.6$\times$ and energy efficiency by 1.1$\sim$14.6$\times$ across various DNNs, compared to the prior art, XpulpNN. Additionally, our processor achieves a 16.5$\times$ higher FP throughput for on-device learning.
DAG-ACFL: Asynchronous Clustered Federated Learning based on DAG-DLT
Aug 25, 2023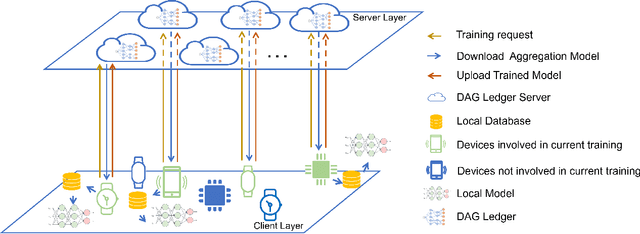
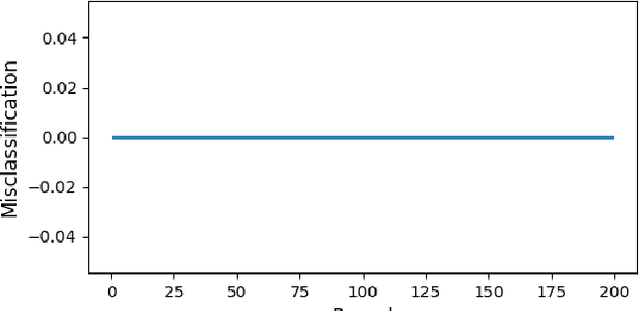


Federated learning (FL) aims to collaboratively train a global model while ensuring client data privacy. However, FL faces challenges from the non-IID data distribution among clients. Clustered FL (CFL) has emerged as a promising solution, but most existing CFL frameworks adopt synchronous frameworks lacking asynchrony. An asynchronous CFL framework called SDAGFL based on directed acyclic graph distributed ledger techniques (DAG-DLT) was proposed, but its complete decentralization leads to high communication and storage costs. We propose DAG-ACFL, an asynchronous clustered FL framework based on directed acyclic graph distributed ledger techniques (DAG-DLT). We first detail the components of DAG-ACFL. A tip selection algorithm based on the cosine similarity of model parameters is then designed to aggregate models from clients with similar distributions. An adaptive tip selection algorithm leveraging change-point detection dynamically determines the number of selected tips. We evaluate the clustering and training performance of DAG-ACFL on multiple datasets and analyze its communication and storage costs. Experiments show the superiority of DAG-ACFL in asynchronous clustered FL. By combining DAG-DLT with clustered FL, DAG-ACFL realizes robust, decentralized and private model training with efficient performance.
PDPU: An Open-Source Posit Dot-Product Unit for Deep Learning Applications
Feb 03, 2023Posit has been a promising alternative to the IEEE-754 floating point format for deep learning applications due to its better trade-off between dynamic range and accuracy. However, hardware implementation of posit arithmetic requires further exploration, especially for the dot-product operations dominated in deep neural networks (DNNs). It has been implemented by either the combination of multipliers and an adder tree or cascaded fused multiply-add units, leading to poor computational efficiency and excessive hardware overhead. To address this issue, we propose an open-source posit dot-product unit, namely PDPU, that facilitates resource-efficient and high-throughput dot-product hardware implementation. PDPU not only features the fused and mixed-precision architecture that eliminates redundant latency and hardware resources, but also has a fine-grained 6-stage pipeline, improving computational efficiency. A configurable PDPU generator is further developed to meet the diverse needs of various DNNs for computational accuracy. Experimental results evaluated under the 28nm CMOS process show that PDPU reduces area, latency, and power by up to 43%, 64%, and 70%, respectively, compared to the existing implementations. Hence, PDPU has great potential as the computing core of posit-based accelerators for deep learning applications.
An Energy Optimized Specializing DAG Federated Learning based on Event Triggered Communication
Sep 26, 2022

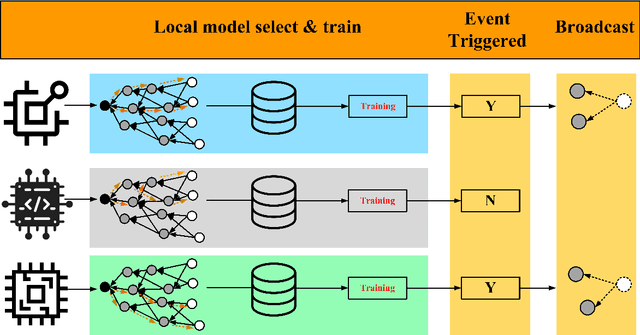

Specializing Directed Acyclic Graph Federated Learning(SDAGFL) is a new federated learning framework which updates model from the devices with similar data distribution through Directed Acyclic Graph Distributed Ledger Technology (DAG-DLT). SDAGFL has the advantage of personalization, resisting single point of failure and poisoning attack in fully decentralized federated learning. Because of these advantages, the SDAGFL is suitable for the federated learning in IoT scenario where the device is usually battery-powered. To promote the application of SDAGFL in IoT, we propose an energy optimized SDAGFL based event-triggered communication mechanism, called ESDAGFL. In ESDAGFL, the new model is broadcasted only when it is significantly changed. We evaluate the ESDAGFL on a clustered synthetically FEMNIST dataset and a dataset from texts by Shakespeare and Goethe's works. The experiment results show that our approach can reduce energy consumption by 33\% compared with SDAGFL, and realize the same balance between training accuracy and specialization as SDAGFL.
Knowledge Distillation via Instance-level Sequence Learning
Jun 21, 2021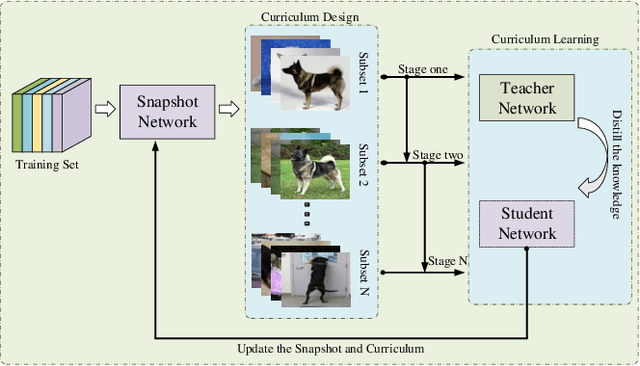
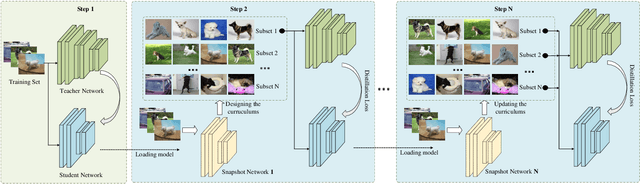
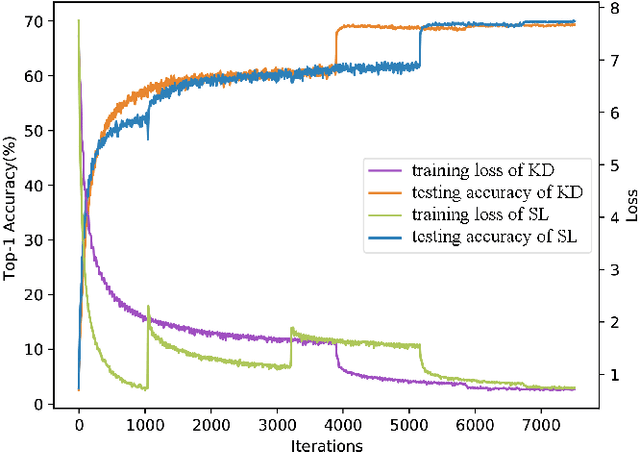
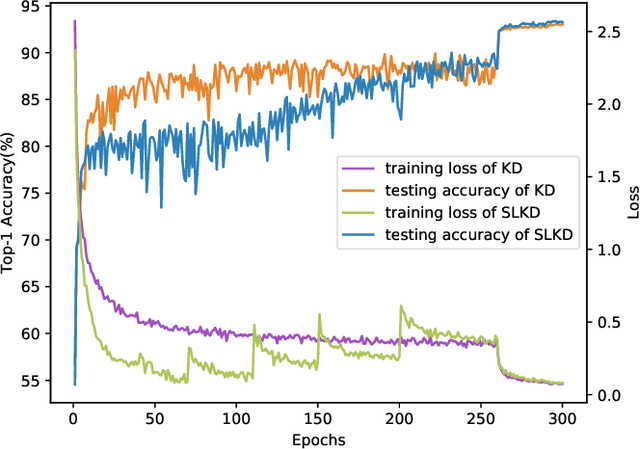
Recently, distillation approaches are suggested to extract general knowledge from a teacher network to guide a student network. Most of the existing methods transfer knowledge from the teacher network to the student via feeding the sequence of random mini-batches sampled uniformly from the data. Instead, we argue that the compact student network should be guided gradually using samples ordered in a meaningful sequence. Thus, it can bridge the gap of feature representation between the teacher and student network step by step. In this work, we provide a curriculum learning knowledge distillation framework via instance-level sequence learning. It employs the student network of the early epoch as a snapshot to create a curriculum for the student network's next training phase. We carry out extensive experiments on CIFAR-10, CIFAR-100, SVHN and CINIC-10 datasets. Compared with several state-of-the-art methods, our framework achieves the best performance with fewer iterations.
Auction Based Clustered Federated Learning in Mobile Edge Computing System
Mar 12, 2021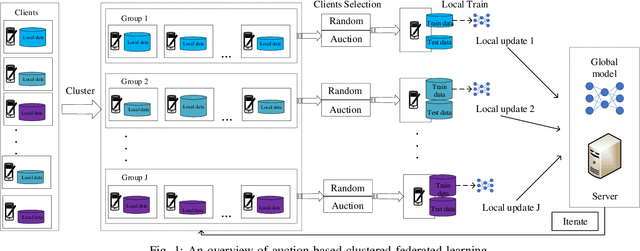
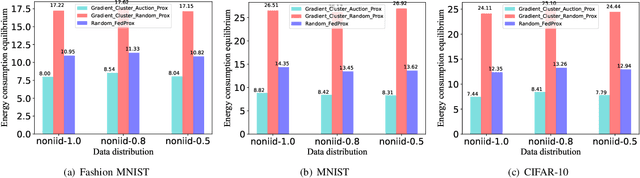
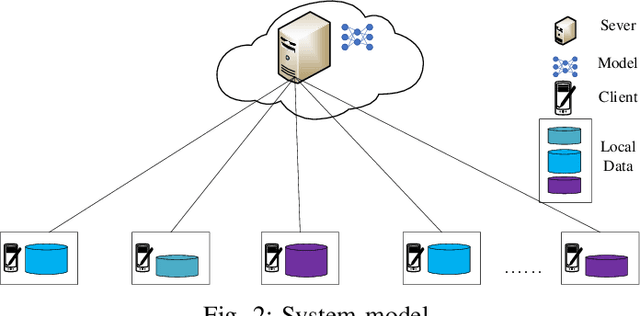
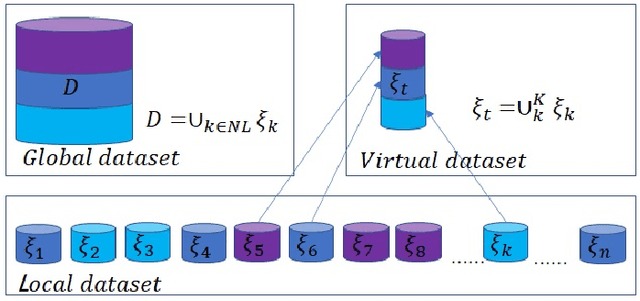
In recent years, mobile clients' computing ability and storage capacity have greatly improved, efficiently dealing with some applications locally. Federated learning is a promising distributed machine learning solution that uses local computing and local data to train the Artificial Intelligence (AI) model. Combining local computing and federated learning can train a powerful AI model under the premise of ensuring local data privacy while making full use of mobile clients' resources. However, the heterogeneity of local data, that is, Non-independent and identical distribution (Non-IID) and imbalance of local data size, may bring a bottleneck hindering the application of federated learning in mobile edge computing (MEC) system. Inspired by this, we propose a cluster-based clients selection method that can generate a federated virtual dataset that satisfies the global distribution to offset the impact of data heterogeneity and proved that the proposed scheme could converge to an approximate optimal solution. Based on the clustering method, we propose an auction-based clients selection scheme within each cluster that fully considers the system's energy heterogeneity and gives the Nash equilibrium solution of the proposed scheme for balance the energy consumption and improving the convergence rate. The simulation results show that our proposed selection methods and auction-based federated learning can achieve better performance with the Convolutional Neural Network model (CNN) under different data distributions.
Multi-level Similarity Learning for Low-Shot Recognition
Dec 13, 2019
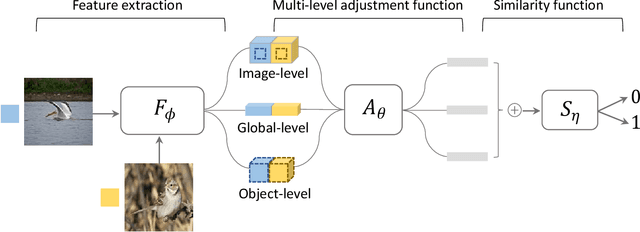
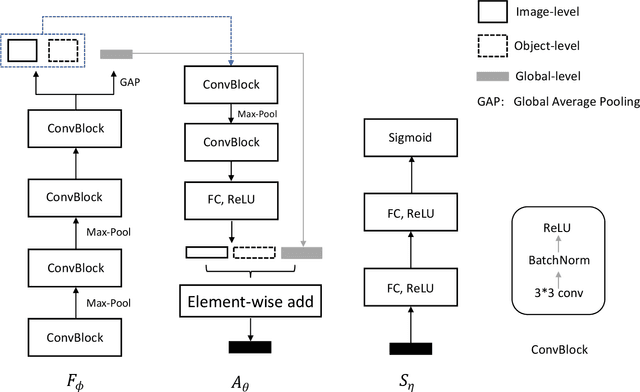
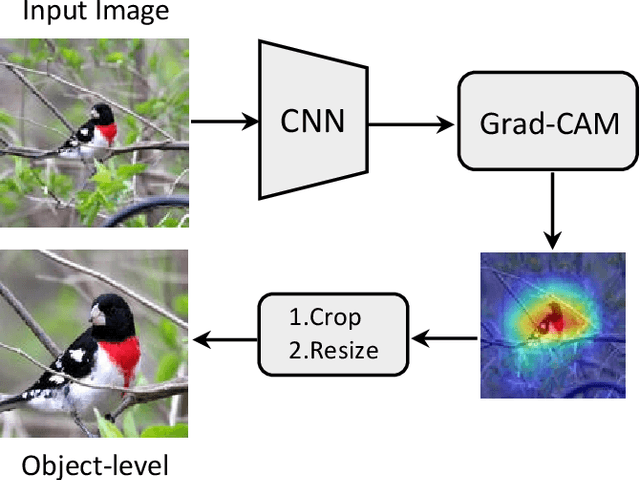
Low-shot learning indicates the ability to recognize unseen objects based on very limited labeled training samples, which simulates human visual intelligence. According to this concept, we propose a multi-level similarity model (MLSM) to capture the deep encoded distance metric between the support and query samples. Our approach is achieved based on the fact that the image similarity learning can be decomposed into image-level, global-level, and object-level. Once the similarity function is established, MLSM will be able to classify images for unseen classes by computing the similarity scores between a limited number of labeled samples and the target images. Furthermore, we conduct 5-way experiments with both 1-shot and 5-shot setting on Caltech-UCSD datasets. It is demonstrated that the proposed model can achieve promising results compared with the existing methods in practical applications.