 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation via Instance-level Sequence Learning
Paper and Code
Jun 21, 2021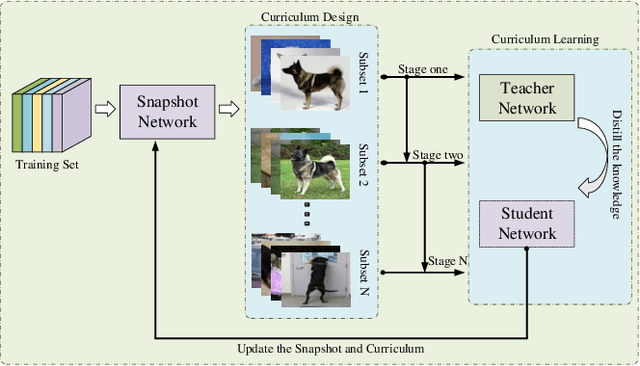
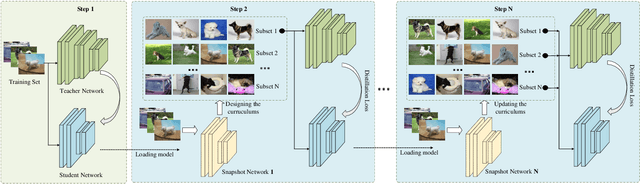
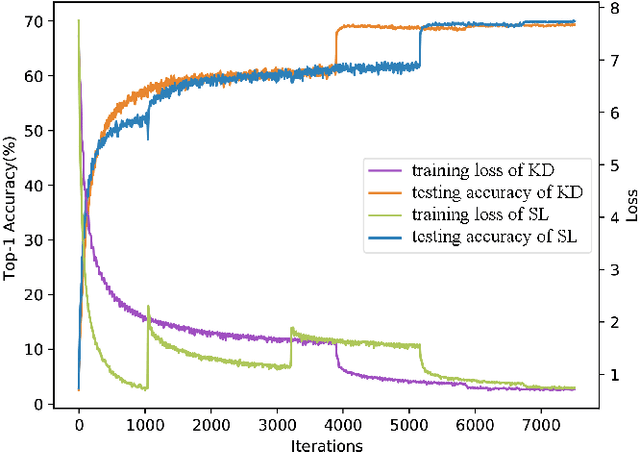
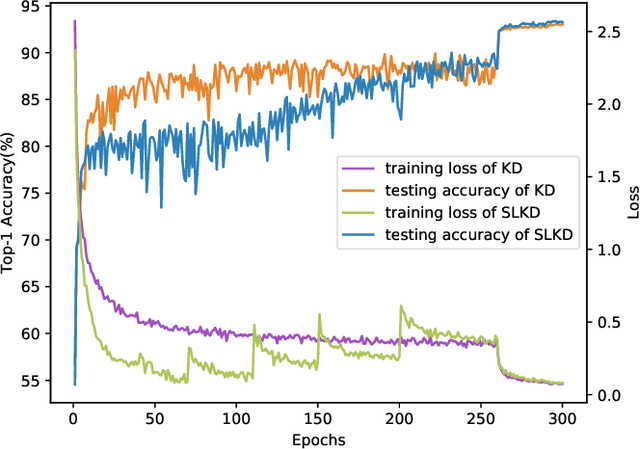
Recently, distillation approaches are suggested to extract general knowledge from a teacher network to guide a student network. Most of the existing methods transfer knowledge from the teacher network to the student via feeding the sequence of random mini-batches sampled uniformly from the data. Instead, we argue that the compact student network should be guided gradually using samples ordered in a meaningful sequence. Thus, it can bridge the gap of feature representation between the teacher and student network step by step. In this work, we provide a curriculum learning knowledge distillation framework via instance-level sequence learning. It employs the student network of the early epoch as a snapshot to create a curriculum for the student network's next training phase. We carry out extensive experiments on CIFAR-10, CIFAR-100, SVHN and CINIC-10 datasets. Compared with several state-of-the-art methods, our framework achieves the best performance with fewer iterations.