 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerMatch: Do Pseudo-labels Benefit All Layers?
Paper and Code
Jun 20, 2024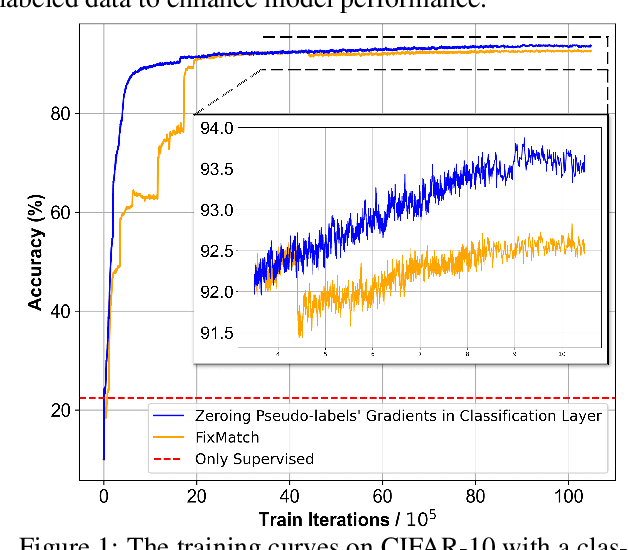
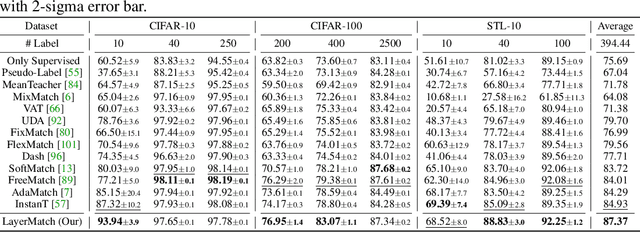
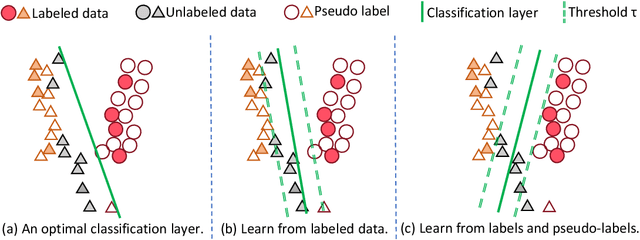
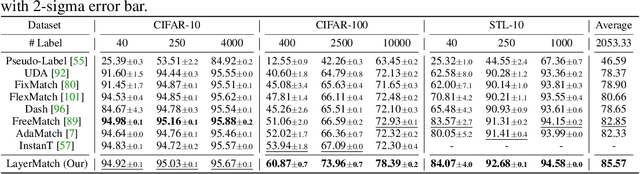
Deep neural networks have achieved remarkable performance across various tasks when supplied with large-scale labeled data. However, the collection of labeled data can be time-consuming and labor-intensive. Semi-supervised learning (SSL), particularly through pseudo-labeling algorithms that iteratively assign pseudo-labels for self-training, offers a promising solution to mitigate the dependency of labeled data. Previous research generally applies a uniform pseudo-labeling strategy across all model layers, assuming that pseudo-labels exert uniform influence throughout. Contrasting this, our theoretical analysis and empirical experiment demonstrate feature extraction layer and linear classification layer have distinct learning behaviors in response to pseudo-labels. Based on these insights, we develop two layer-specific pseudo-label strategies, termed Grad-ReLU and Avg-Clustering. Grad-ReLU mitigates the impact of noisy pseudo-labels by removing the gradient detrimental effects of pseudo-labels in the linear classification layer. Avg-Clustering accelerates the convergence of feature extraction layer towards stable clustering centers by integrating consistent outputs. Our approach, LayerMatch, which integrates these two strategies, can avoid the severe interference of noisy pseudo-labels in the linear classification layer while accelerating the clustering capability of the feature extraction layer. Through extensive experimentation, our approach consistently demonstrates exceptional performance on standard semi-supervised learning benchmarks, achieving a significant improvement of 10.38% over baseline method and a 2.44% increase compared to state-of-the-art methods.