 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Enhanced Test-time Adaptation with Text and Image Augmentation
Dec 12, 2024Existing test-time prompt tuning (TPT) methods focus on single-modality data, primarily enhancing images and using confidence ratings to filter out inaccurate images. However, while image generation models can produce visually diverse images, single-modality data enhancement techniques still fail to capture the comprehensive knowledge provided by different modalities. Additionally, we note that the performance of TPT-based methods drops significantly when the number of augmented images is limited, which is not unusual given the computational expense of generative augmentation. To address these issues, we introduce IT3A, a novel test-time adaptation method that utilizes a pre-trained generative model for multi-modal augmentation of each test sample from unknown new domains. By combining augmented data from pre-trained vision and language models, we enhance the ability of the model to adapt to unknown new test data. Additionally, to ensure that key semantics are accurately retained when generating various visual and text enhancements, we employ cosine similarity filtering between the logits of the enhanced images and text with the original test data. This process allows us to filter out some spurious augmentation and inadequate combinations. To leverage the diverse enhancements provided by the generation model across different modals, we have replaced prompt tuning with an adapter for greater flexibility in utilizing text templates. Our experiments on the test datasets with distribution shifts and domain gaps show that in a zero-shot setting, IT3A outperforms state-of-the-art test-time prompt tuning methods with a 5.50% increase in accuracy.
* Accepted by International Journal of Computer Vision
CPT: Consistent Proxy Tuning for Black-box Optimization
Jul 01, 2024
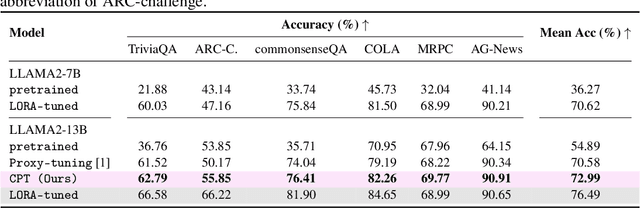
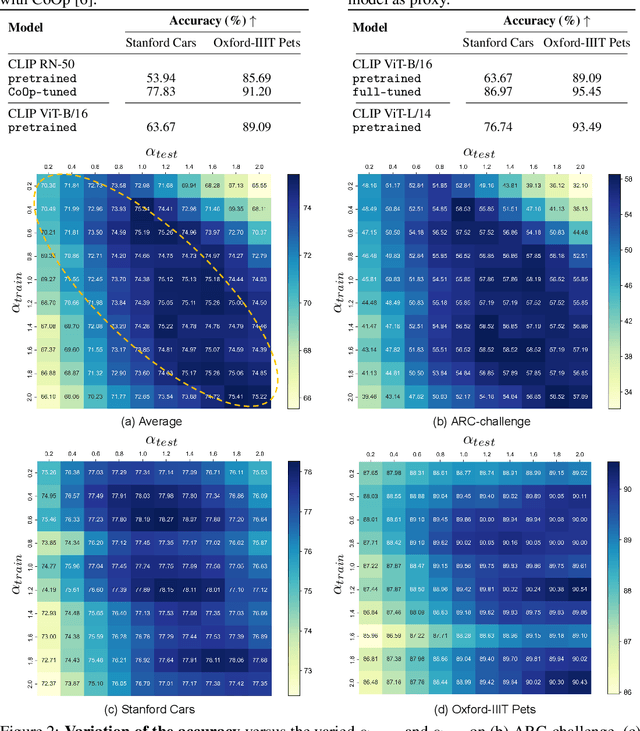
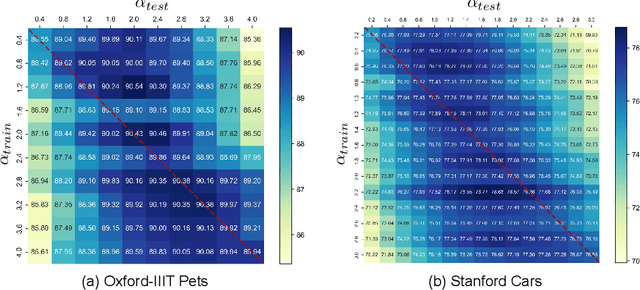
Black-box tuning has attracted recent attention due to that the structure or inner parameters of advanced proprietary models are not accessible. Proxy-tuning provides a test-time output adjustment for tuning black-box language models. It applies the difference of the output logits before and after tuning a smaller white-box "proxy" model to improve the black-box model. However, this technique serves only as a decoding-time algorithm, leading to an inconsistency between training and testing which potentially limits overall performance. To address this problem, we introduce Consistent Proxy Tuning (CPT), a simple yet effective black-box tuning method. Different from Proxy-tuning, CPT additionally exploits the frozen large black-box model and another frozen small white-box model, ensuring consistency between training-stage optimization objective and test-time proxies. This consistency benefits Proxy-tuning and enhances model performance. Note that our method focuses solely on logit-level computation, which makes it model-agnostic and applicable to any task involving logit classification. Extensive experimental results demonstrate the superiority of our CPT in both black-box tuning of Large Language Models (LLMs) and Vision-Language Models (VLMs) across various datasets. The code is available at https://github.com/chunmeifeng/CPT.