 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable-Length Finite-Rate CSI Feedback With Generative Priors
Jun 05, 2026This letter studies variable-length finite-rate CSI feedback from a structural perspective and proposes CsiCoGen, a novel generative feedback structure with a transferable codebook mechanism without joint training. The UE maps $H_0$ into an ordered sequence of codebook indices, while the BS recursively recovers CSI from any received partial sequence of feedback indices using a shared denoising prior. This enables flexible control of feedback sequence length and per-step quantization precision through codebook size. CsiCoGen does not require jointly training a task-specific feedback encoder or codebook with the reconstructor, and the same online structure can be paired with different pretrained denoisers. In this work, we instantiate the decoder with a generative diffusion model. Simulation results on COST2100 show favorable rate-NMSE and rate-$ρ$ tradeoffs against representative baselines, with CsiCoGen reaching about -31 dB indoor NMSE and -20 dB outdoor NMSE in the high-rate regime while demonstrating scalable decoding complexity and adjustable per-step quantization precision.
MDS-VQA: Model-Informed Data Selection for Video Quality Assessment
Mar 12, 2026Learning-based video quality assessment (VQA) has advanced rapidly, yet progress is increasingly constrained by a disconnect between model design and dataset curation. Model-centric approaches often iterate on fixed benchmarks, while data-centric efforts collect new human labels without systematically targeting the weaknesses of existing VQA models. Here, we describe MDS-VQA, a model-informed data selection mechanism for curating unlabeled videos that are both difficult for the base VQA model and diverse in content. Difficulty is estimated by a failure predictor trained with a ranking objective, and diversity is measured using deep semantic video features, with a greedy procedure balancing the two under a constrained labeling budget. Experiments across multiple VQA datasets and models demonstrate that MDS-VQA identifies diverse, challenging samples that are particularly informative for active fine-tuning. With only a 5% selected subset per target domain, the fine-tuned model improves mean SRCC from 0.651 to 0.722 and achieves the top gMAD rank, indicating strong adaptation and generalization.
VisualQuality-R1: Reasoning-Induced Image Quality Assessment via Reinforcement Learning to Rank
May 20, 2025



DeepSeek-R1 has demonstrated remarkable effectiveness in incentivizing reasoning and generalization capabilities of large language models (LLMs) through reinforcement learning. Nevertheless, the potential of reasoning-induced computational modeling has not been thoroughly explored in the context of image quality assessment (IQA), a task critically dependent on visual reasoning. In this paper, we introduce VisualQuality-R1, a reasoning-induced no-reference IQA (NR-IQA) model, and we train it with reinforcement learning to rank, a learning algorithm tailored to the intrinsically relative nature of visual quality. Specifically, for a pair of images, we employ group relative policy optimization to generate multiple quality scores for each image. These estimates are then used to compute comparative probabilities of one image having higher quality than the other under the Thurstone model. Rewards for each quality estimate are defined using continuous fidelity measures rather than discretized binary labels. Extensive experiments show that the proposed VisualQuality-R1 consistently outperforms discriminative deep learning-based NR-IQA models as well as a recent reasoning-induced quality regression method. Moreover, VisualQuality-R1 is capable of generating contextually rich, human-aligned quality descriptions, and supports multi-dataset training without requiring perceptual scale realignment. These features make VisualQuality-R1 especially well-suited for reliably measuring progress in a wide range of image processing tasks like super-resolution and image generation.
Diffusion-Enhanced Test-time Adaptation with Text and Image Augmentation
Dec 12, 2024Existing test-time prompt tuning (TPT) methods focus on single-modality data, primarily enhancing images and using confidence ratings to filter out inaccurate images. However, while image generation models can produce visually diverse images, single-modality data enhancement techniques still fail to capture the comprehensive knowledge provided by different modalities. Additionally, we note that the performance of TPT-based methods drops significantly when the number of augmented images is limited, which is not unusual given the computational expense of generative augmentation. To address these issues, we introduce IT3A, a novel test-time adaptation method that utilizes a pre-trained generative model for multi-modal augmentation of each test sample from unknown new domains. By combining augmented data from pre-trained vision and language models, we enhance the ability of the model to adapt to unknown new test data. Additionally, to ensure that key semantics are accurately retained when generating various visual and text enhancements, we employ cosine similarity filtering between the logits of the enhanced images and text with the original test data. This process allows us to filter out some spurious augmentation and inadequate combinations. To leverage the diverse enhancements provided by the generation model across different modals, we have replaced prompt tuning with an adapter for greater flexibility in utilizing text templates. Our experiments on the test datasets with distribution shifts and domain gaps show that in a zero-shot setting, IT3A outperforms state-of-the-art test-time prompt tuning methods with a 5.50% increase in accuracy.
* Accepted by International Journal of Computer Vision
UniM$^2$AE: Multi-modal Masked Autoencoders with Unified 3D Representation for 3D Perception in Autonomous Driving
Aug 30, 2023



Masked Autoencoders (MAE) play a pivotal role in learning potent representations, delivering outstanding results across various 3D perception tasks essential for autonomous driving. In real-world driving scenarios, it's commonplace to deploy multiple sensors for comprehensive environment perception. While integrating multi-modal features from these sensors can produce rich and powerful features, there is a noticeable gap in MAE methods addressing this integration. This research delves into multi-modal Masked Autoencoders tailored for a unified representation space in autonomous driving, aiming to pioneer a more efficient fusion of two distinct modalities. To intricately marry the semantics inherent in images with the geometric intricacies of LiDAR point clouds, the UniM$^2$AE is proposed. This model stands as a potent yet straightforward, multi-modal self-supervised pre-training framework, mainly consisting of two designs. First, it projects the features from both modalities into a cohesive 3D volume space, ingeniously expanded from the bird's eye view (BEV) to include the height dimension. The extension makes it possible to back-project the informative features, obtained by fusing features from both modalities, into their native modalities to reconstruct the multiple masked inputs. Second, the Multi-modal 3D Interactive Module (MMIM) is invoked to facilitate the efficient inter-modal interaction during the interaction process. Extensive experiments conducted on the nuScenes Dataset attest to the efficacy of UniM$^2$AE, indicating enhancements in 3D object detection and BEV map segmentation by 1.2\%(NDS) and 6.5\% (mIoU), respectively. Code is available at https://github.com/hollow-503/UniM2AE.
Learning Low-dimensional Manifolds for Scoring of Tissue Microarray Images
Feb 22, 2021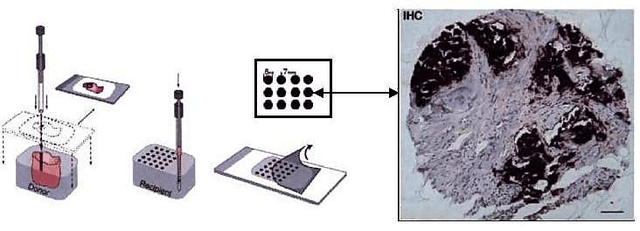
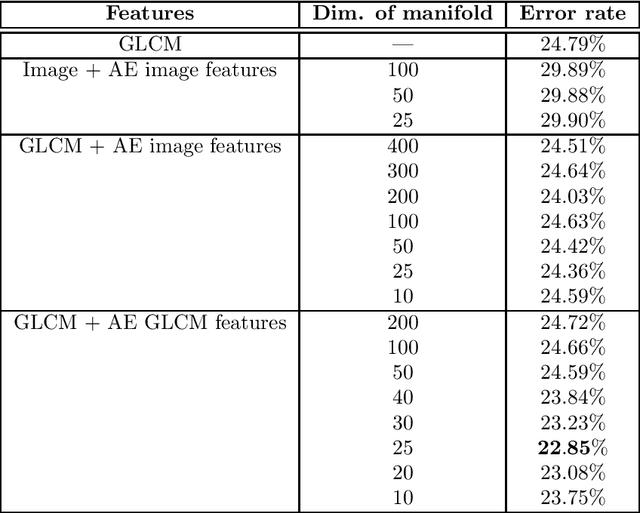
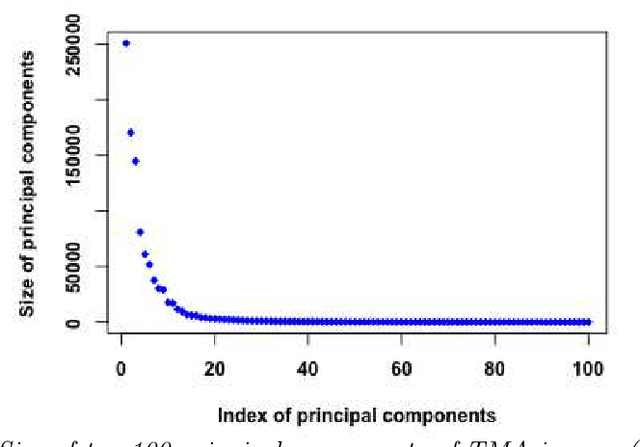
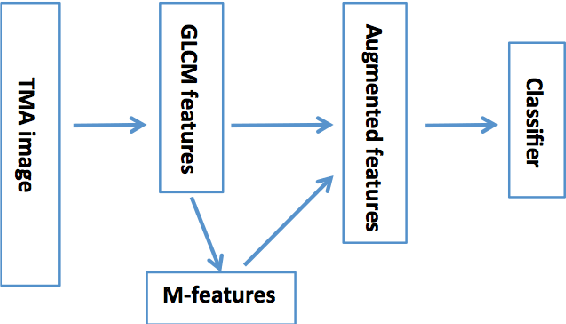
Tissue microarray (TMA) images have emerged as an important high-throughput tool for cancer study and the validation of biomarkers. Efforts have been dedicated to further improve the accuracy of TACOMA, a cutting-edge automatic scoring algorithm for TMA images. One major advance is due to deepTacoma, an algorithm that incorporates suitable deep representations of a group nature. Inspired by the recent advance in semi-supervised learning and deep learning, we propose mfTacoma to learn alternative deep representations in the context of TMA image scoring. In particular, mfTacoma learns the low-dimensional manifolds, a common latent structure in high dimensional data. Deep representation learning and manifold learning typically requires large data. By encoding deep representation of the manifolds as regularizing features, mfTacoma effectively leverages the manifold information that is potentially crude due to small data. Our experiments show that deep features by manifolds outperforms two alternatives -- deep features by linear manifolds with principal component analysis or by leveraging the group property.
Incorporating Deep Features in the Analysis of Tissue Microarray Images
Nov 26, 2018
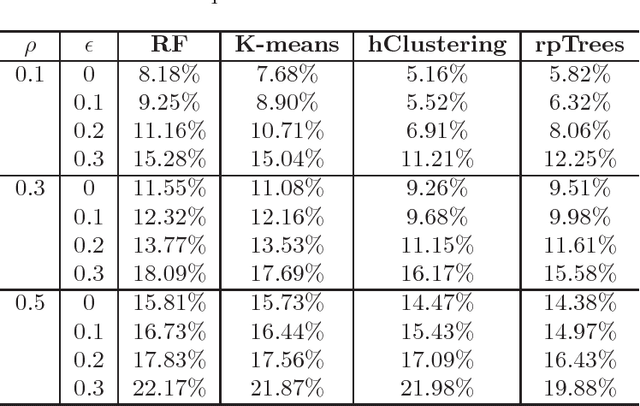

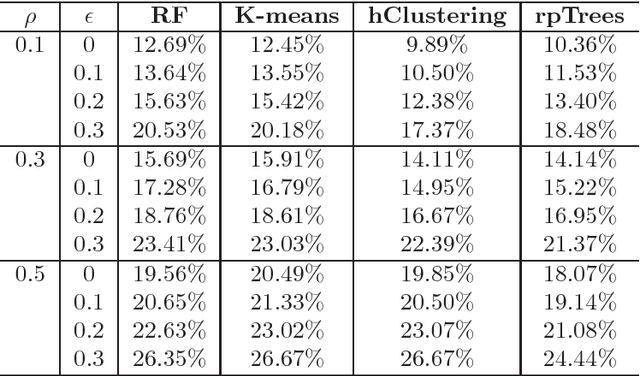
Tissue microarray (TMA) images have been used increasingly often in cancer studies and the validation of biomarkers. TACOMA---a cutting-edge automatic scoring algorithm for TMA images---is comparable to pathologists in terms of accuracy and repeatability. Here we consider how this algorithm may be further improved. Inspired by the recent success of deep learning, we propose to incorporate representations learnable through computation. We explore representations of a group nature through unsupervised learning, e.g., hierarchical clustering and recursive space partition. Information carried by clustering or spatial partitioning may be more concrete than the labels when the data are heterogeneous, or could help when the labels are noisy. The use of such information could be viewed as regularization in model fitting. It is motivated by major challenges in TMA image scoring---heterogeneity and label noise, and the cluster assumption in semi-supervised learning. Using this information on TMA images of breast cancer, we have reduced the error rate of TACOMA by about 6%. Further simulations on synthetic data provide insights on when such representations would likely help. Although we focus on TMAs, learnable representations of this type are expected to be applicable in other settings.
Anomaly Detection via Graphical Lasso
Nov 10, 2018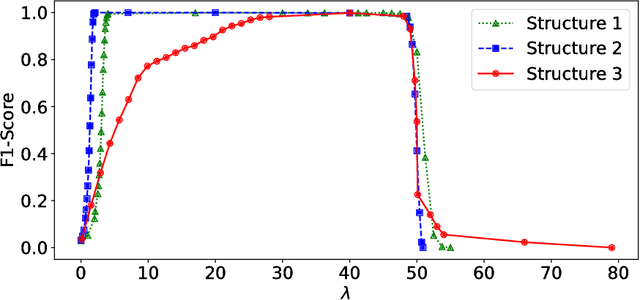
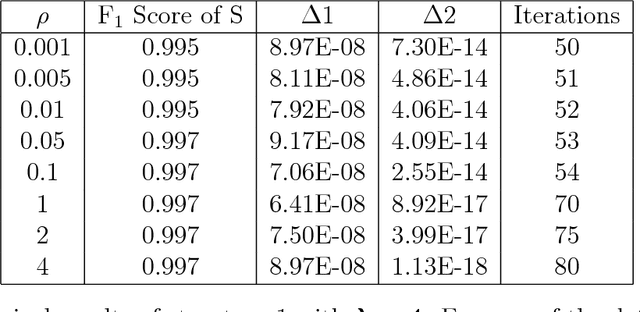
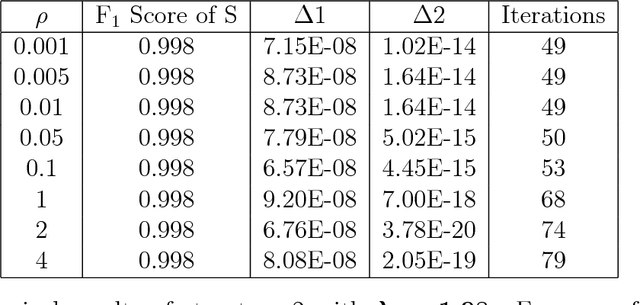
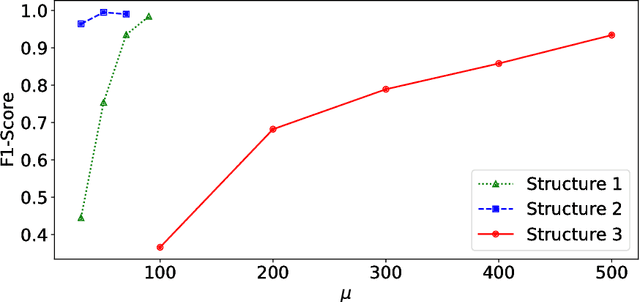
Anomalies and outliers are common in real-world data, and they can arise from many sources, such as sensor faults. Accordingly, anomaly detection is important both for analyzing the anomalies themselves and for cleaning the data for further analysis of its ambient structure. Nonetheless, a precise definition of anomalies is important for automated detection and herein we approach such problems from the perspective of detecting sparse latent effects embedded in large collections of noisy data. Standard Graphical Lasso-based techniques can identify the conditional dependency structure of a collection of random variables based on their sample covariance matrix. However, classic Graphical Lasso is sensitive to outliers in the sample covariance matrix. In particular, several outliers in a sample covariance matrix can destroy the sparsity of its inverse. Accordingly, we propose a novel optimization problem that is similar in spirit to Robust Principal Component Analysis (RPCA) and splits the sample covariance matrix $M$ into two parts, $M=F+S$, where $F$ is the cleaned sample covariance whose inverse is sparse and computable by Graphical Lasso, and $S$ contains the outliers in $M$. We accomplish this decomposition by adding an additional $ \ell_1$ penalty to classic Graphical Lasso, and name it "Robust Graphical Lasso (Rglasso)". Moreover, we propose an Alternating Direction Method of Multipliers (ADMM) solution to the optimization problem which scales to large numbers of unknowns. We evaluate our algorithm on both real and synthetic datasets, obtaining interpretable results and outperforming the standard robust Minimum Covariance Determinant (MCD) method and Robust Principal Component Analysis (RPCA) regarding both accuracy and speed.