 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity-Preserved Distribution Matching Distillation for Fast Visual Synthesis
Feb 03, 2026Distribution matching distillation (DMD) aligns a multi-step generator with its few-step counterpart to enable high-quality generation under low inference cost. However, DMD tends to suffer from mode collapse, as its reverse-KL formulation inherently encourages mode-seeking behavior, for which existing remedies typically rely on perceptual or adversarial regularization, thereby incurring substantial computational overhead and training instability. In this work, we propose a role-separated distillation framework that explicitly disentangles the roles of distilled steps: the first step is dedicated to preserving sample diversity via a target-prediction (e.g., v-prediction) objective, while subsequent steps focus on quality refinement under the standard DMD loss, with gradients from the DMD objective blocked at the first step. We term this approach Diversity-Preserved DMD (DP-DMD), which, despite its simplicity -- no perceptual backbone, no discriminator, no auxiliary networks, and no additional ground-truth images -- preserves sample diversity while maintaining visual quality on par with state-of-the-art methods in extensive text-to-image experiments.
DP$^2$O-SR: Direct Perceptual Preference Optimization for Real-World Image Super-Resolution
Oct 21, 2025Benefiting from pre-trained text-to-image (T2I) diffusion models, real-world image super-resolution (Real-ISR) methods can synthesize rich and realistic details. However, due to the inherent stochasticity of T2I models, different noise inputs often lead to outputs with varying perceptual quality. Although this randomness is sometimes seen as a limitation, it also introduces a wider perceptual quality range, which can be exploited to improve Real-ISR performance. To this end, we introduce Direct Perceptual Preference Optimization for Real-ISR (DP$^2$O-SR), a framework that aligns generative models with perceptual preferences without requiring costly human annotations. We construct a hybrid reward signal by combining full-reference and no-reference image quality assessment (IQA) models trained on large-scale human preference datasets. This reward encourages both structural fidelity and natural appearance. To better utilize perceptual diversity, we move beyond the standard best-vs-worst selection and construct multiple preference pairs from outputs of the same model. Our analysis reveals that the optimal selection ratio depends on model capacity: smaller models benefit from broader coverage, while larger models respond better to stronger contrast in supervision. Furthermore, we propose hierarchical preference optimization, which adaptively weights training pairs based on intra-group reward gaps and inter-group diversity, enabling more efficient and stable learning. Extensive experiments across both diffusion- and flow-based T2I backbones demonstrate that DP$^2$O-SR significantly improves perceptual quality and generalizes well to real-world benchmarks.
VisualQuality-R1: Reasoning-Induced Image Quality Assessment via Reinforcement Learning to Rank
May 20, 2025



DeepSeek-R1 has demonstrated remarkable effectiveness in incentivizing reasoning and generalization capabilities of large language models (LLMs) through reinforcement learning. Nevertheless, the potential of reasoning-induced computational modeling has not been thoroughly explored in the context of image quality assessment (IQA), a task critically dependent on visual reasoning. In this paper, we introduce VisualQuality-R1, a reasoning-induced no-reference IQA (NR-IQA) model, and we train it with reinforcement learning to rank, a learning algorithm tailored to the intrinsically relative nature of visual quality. Specifically, for a pair of images, we employ group relative policy optimization to generate multiple quality scores for each image. These estimates are then used to compute comparative probabilities of one image having higher quality than the other under the Thurstone model. Rewards for each quality estimate are defined using continuous fidelity measures rather than discretized binary labels. Extensive experiments show that the proposed VisualQuality-R1 consistently outperforms discriminative deep learning-based NR-IQA models as well as a recent reasoning-induced quality regression method. Moreover, VisualQuality-R1 is capable of generating contextually rich, human-aligned quality descriptions, and supports multi-dataset training without requiring perceptual scale realignment. These features make VisualQuality-R1 especially well-suited for reliably measuring progress in a wide range of image processing tasks like super-resolution and image generation.
Toward Generalized Image Quality Assessment: Relaxing the Perfect Reference Quality Assumption
Mar 14, 2025



Full-reference image quality assessment (FR-IQA) generally assumes that reference images are of perfect quality. However, this assumption is flawed due to the sensor and optical limitations of modern imaging systems. Moreover, recent generative enhancement methods are capable of producing images of higher quality than their original. All of these challenge the effectiveness and applicability of current FR-IQA models. To relax the assumption of perfect reference image quality, we build a large-scale IQA database, namely DiffIQA, containing approximately 180,000 images generated by a diffusion-based image enhancer with adjustable hyper-parameters. Each image is annotated by human subjects as either worse, similar, or better quality compared to its reference. Building on this, we present a generalized FR-IQA model, namely Adaptive Fidelity-Naturalness Evaluator (A-FINE), to accurately assess and adaptively combine the fidelity and naturalness of a test image. A-FINE aligns well with standard FR-IQA when the reference image is much more natural than the test image. We demonstrate by extensive experiments that A-FINE surpasses standard FR-IQA models on well-established IQA datasets and our newly created DiffIQA. To further validate A-FINE, we additionally construct a super-resolution IQA benchmark (SRIQA-Bench), encompassing test images derived from ten state-of-the-art SR methods with reliable human quality annotations. Tests on SRIQA-Bench re-affirm the advantages of A-FINE. The code and dataset are available at https://tianhewu.github.io/A-FINE-page.github.io/.
A Comprehensive Study of Multimodal Large Language Models for Image Quality Assessment
Mar 16, 2024



While Multimodal Large Language Models (MLLMs) have experienced significant advancement on visual understanding and reasoning, their potentials to serve as powerful, flexible, interpretable, and text-driven models for Image Quality Assessment (IQA) remains largely unexplored. In this paper, we conduct a comprehensive and systematic study of prompting MLLMs for IQA. Specifically, we first investigate nine prompting systems for MLLMs as the combinations of three standardized testing procedures in psychophysics (i.e., the single-stimulus, double-stimulus, and multiple-stimulus methods) and three popular prompting strategies in natural language processing (i.e., the standard, in-context, and chain-of-thought prompting). We then present a difficult sample selection procedure, taking into account sample diversity and uncertainty, to further challenge MLLMs equipped with the respective optimal prompting systems. We assess three open-source and one close-source MLLMs on several visual attributes of image quality (e.g., structural and textural distortions, color differences, and geometric transformations) in both full-reference and no-reference scenarios. Experimental results show that only the close-source GPT-4V provides a reasonable account for human perception of image quality, but is weak at discriminating fine-grained quality variations (e.g., color differences) and at comparing visual quality of multiple images, tasks humans can perform effortlessly.
Assessor360: Multi-sequence Network for Blind Omnidirectional Image Quality Assessment
May 24, 2023Blind Omnidirectional Image Quality Assessment (BOIQA) aims to objectively assess the human perceptual quality of omnidirectional images (ODIs) without relying on pristine-quality image information. It is becoming more significant with the increasing advancement of virtual reality (VR) technology. However, the quality assessment of ODIs is severely hampered by the fact that the existing BOIQA pipeline lacks the modeling of the observer's browsing process. To tackle this issue, we propose a novel multi-sequence network for BOIQA called Assessor360, which is derived from the realistic multi-assessor ODI quality assessment procedure. Specifically, we propose a generalized Recursive Probability Sampling (RPS) method for the BOIQA task, combining content and detailed information to generate multiple pseudo viewport sequences from a given starting point. Additionally, we design a Multi-scale Feature Aggregation (MFA) module with Distortion-aware Block (DAB) to fuse distorted and semantic features of each viewport. We also devise TMM to learn the viewport transition in the temporal domain. Extensive experimental results demonstrate that Assessor360 outperforms state-of-the-art methods on multiple OIQA datasets.
Attentions Help CNNs See Better: Attention-based Hybrid Image Quality Assessment Network
Apr 22, 2022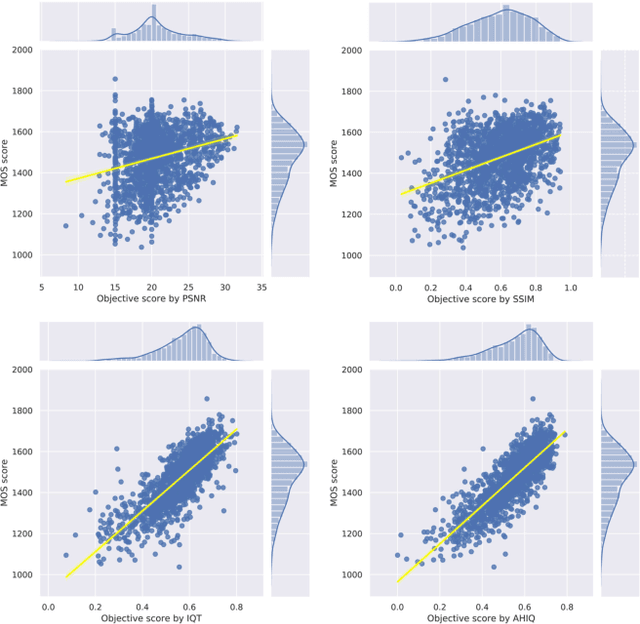

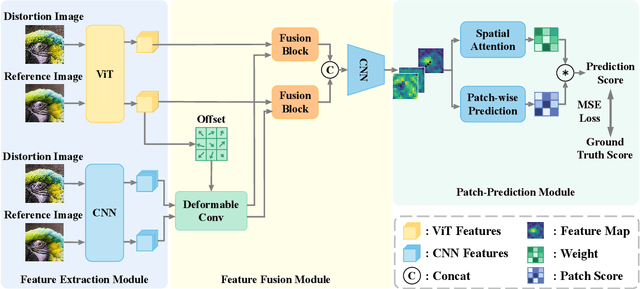
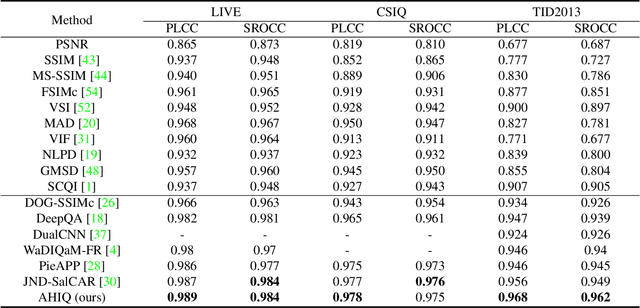
Image quality assessment (IQA) algorithm aims to quantify the human perception of image quality. Unfortunately, there is a performance drop when assessing the distortion images generated by generative adversarial network (GAN) with seemingly realistic texture. In this work, we conjecture that this maladaptation lies in the backbone of IQA models, where patch-level prediction methods use independent image patches as input to calculate their scores separately, but lack spatial relationship modeling among image patches. Therefore, we propose an Attention-based Hybrid Image Quality Assessment Network (AHIQ) to deal with the challenge and get better performance on the GAN-based IQA task. Firstly, we adopt a two-branch architecture, including a vision transformer (ViT) branch and a convolutional neural network (CNN) branch for feature extraction. The hybrid architecture combines interaction information among image patches captured by ViT and local texture details from CNN. To make the features from shallow CNN more focused on the visually salient region, a deformable convolution is applied with the help of semantic information from the ViT branch. Finally, we use a patch-wise score prediction module to obtain the final score. The experiments show that our model outperforms the state-of-the-art methods on four standard IQA datasets and AHIQ ranked first on the Full Reference (FR) track of the NTIRE 2022 Perceptual Image Quality Assessment Challenge.
MANIQA: Multi-dimension Attention Network for No-Reference Image Quality Assessment
Apr 21, 2022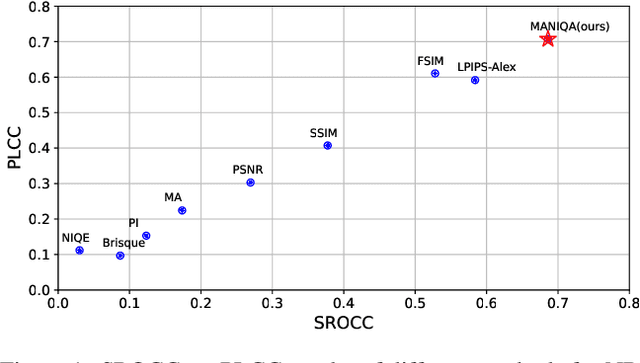
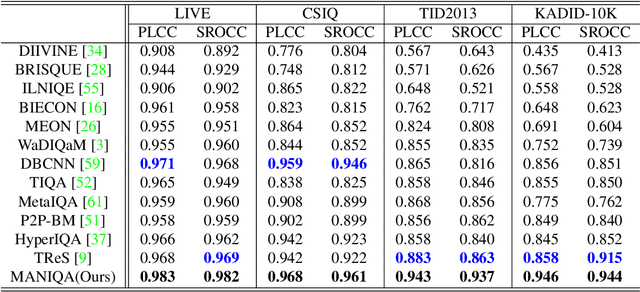
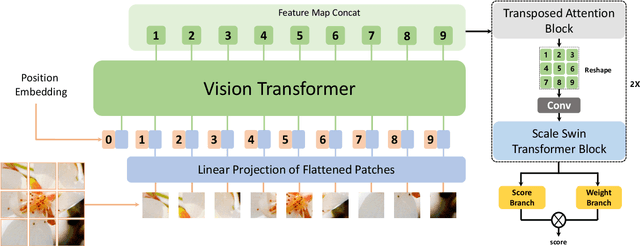
No-Reference Image Quality Assessment (NR-IQA) aims to assess the perceptual quality of images in accordance with human subjective perception. Unfortunately, existing NR-IQA methods are far from meeting the needs of predicting accurate quality scores on GAN-based distortion images. To this end, we propose Multi-dimension Attention Network for no-reference Image Quality Assessment (MANIQA) to improve the performance on GAN-based distortion. We firstly extract features via ViT, then to strengthen global and local interactions, we propose the Transposed Attention Block (TAB) and the Scale Swin Transformer Block (SSTB). These two modules apply attention mechanisms across the channel and spatial dimension, respectively. In this multi-dimensional manner, the modules cooperatively increase the interaction among different regions of images globally and locally. Finally, a dual branch structure for patch-weighted quality prediction is applied to predict the final score depending on the weight of each patch's score. Experimental results demonstrate that MANIQA outperforms state-of-the-art methods on four standard datasets (LIVE, TID2013, CSIQ, and KADID-10K) by a large margin. Besides, our method ranked first place in the final testing phase of the NTIRE 2022 Perceptual Image Quality Assessment Challenge Track 2: No-Reference. Codes and models are available at https://github.com/IIGROUP/MANIQA.