 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP$^2$O-SR: Direct Perceptual Preference Optimization for Real-World Image Super-Resolution
Oct 21, 2025Benefiting from pre-trained text-to-image (T2I) diffusion models, real-world image super-resolution (Real-ISR) methods can synthesize rich and realistic details. However, due to the inherent stochasticity of T2I models, different noise inputs often lead to outputs with varying perceptual quality. Although this randomness is sometimes seen as a limitation, it also introduces a wider perceptual quality range, which can be exploited to improve Real-ISR performance. To this end, we introduce Direct Perceptual Preference Optimization for Real-ISR (DP$^2$O-SR), a framework that aligns generative models with perceptual preferences without requiring costly human annotations. We construct a hybrid reward signal by combining full-reference and no-reference image quality assessment (IQA) models trained on large-scale human preference datasets. This reward encourages both structural fidelity and natural appearance. To better utilize perceptual diversity, we move beyond the standard best-vs-worst selection and construct multiple preference pairs from outputs of the same model. Our analysis reveals that the optimal selection ratio depends on model capacity: smaller models benefit from broader coverage, while larger models respond better to stronger contrast in supervision. Furthermore, we propose hierarchical preference optimization, which adaptively weights training pairs based on intra-group reward gaps and inter-group diversity, enabling more efficient and stable learning. Extensive experiments across both diffusion- and flow-based T2I backbones demonstrate that DP$^2$O-SR significantly improves perceptual quality and generalizes well to real-world benchmarks.
Fine-structure Preserved Real-world Image Super-resolution via Transfer VAE Training
Jul 27, 2025Impressive results on real-world image super-resolution (Real-ISR) have been achieved by employing pre-trained stable diffusion (SD) models. However, one critical issue of such methods lies in their poor reconstruction of image fine structures, such as small characters and textures, due to the aggressive resolution reduction of the VAE (eg., 8$\times$ downsampling) in the SD model. One solution is to employ a VAE with a lower downsampling rate for diffusion; however, adapting its latent features with the pre-trained UNet while mitigating the increased computational cost poses new challenges. To address these issues, we propose a Transfer VAE Training (TVT) strategy to transfer the 8$\times$ downsampled VAE into a 4$\times$ one while adapting to the pre-trained UNet. Specifically, we first train a 4$\times$ decoder based on the output features of the original VAE encoder, then train a 4$\times$ encoder while keeping the newly trained decoder fixed. Such a TVT strategy aligns the new encoder-decoder pair with the original VAE latent space while enhancing image fine details. Additionally, we introduce a compact VAE and compute-efficient UNet by optimizing their network architectures, reducing the computational cost while capturing high-resolution fine-scale features. Experimental results demonstrate that our TVT method significantly improves fine-structure preservation, which is often compromised by other SD-based methods, while requiring fewer FLOPs than state-of-the-art one-step diffusion models. The official code can be found at https://github.com/Joyies/TVT.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Pixel-level and Semantic-level Adjustable Super-resolution: A Dual-LoRA Approach
Dec 04, 2024



Diffusion prior-based methods have shown impressive results in real-world image super-resolution (SR). However, most existing methods entangle pixel-level and semantic-level SR objectives in the training process, struggling to balance pixel-wise fidelity and perceptual quality. Meanwhile, users have varying preferences on SR results, thus it is demanded to develop an adjustable SR model that can be tailored to different fidelity-perception preferences during inference without re-training. We present Pixel-level and Semantic-level Adjustable SR (PiSA-SR), which learns two LoRA modules upon the pre-trained stable-diffusion (SD) model to achieve improved and adjustable SR results. We first formulate the SD-based SR problem as learning the residual between the low-quality input and the high-quality output, then show that the learning objective can be decoupled into two distinct LoRA weight spaces: one is characterized by the $\ell_2$-loss for pixel-level regression, and another is characterized by the LPIPS and classifier score distillation losses to extract semantic information from pre-trained classification and SD models. In its default setting, PiSA-SR can be performed in a single diffusion step, achieving leading real-world SR results in both quality and efficiency. By introducing two adjustable guidance scales on the two LoRA modules to control the strengths of pixel-wise fidelity and semantic-level details during inference, PiSASR can offer flexible SR results according to user preference without re-training. Codes and models can be found at https://github.com/csslc/PiSA-SR.
Multi-Scale Representation Learning for Image Restoration with State-Space Model
Aug 19, 2024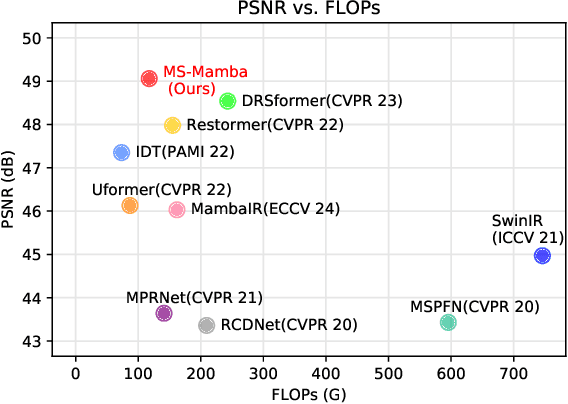
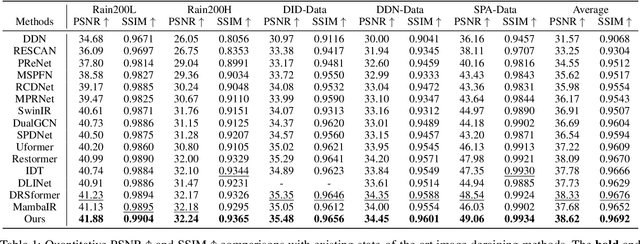
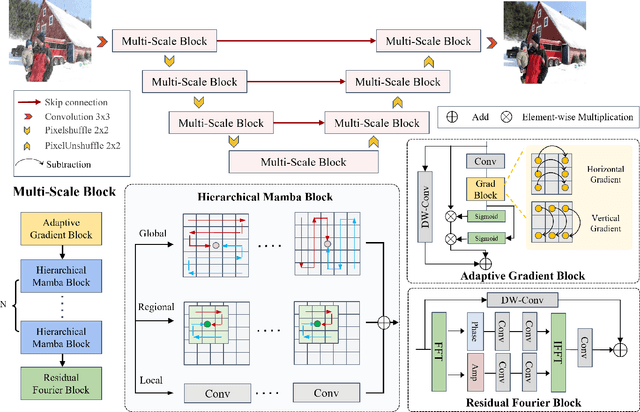

Image restoration endeavors to reconstruct a high-quality, detail-rich image from a degraded counterpart, which is a pivotal process in photography and various computer vision systems. In real-world scenarios, different types of degradation can cause the loss of image details at various scales and degrade image contrast. Existing methods predominantly rely on CNN and Transformer to capture multi-scale representations. However, these methods are often limited by the high computational complexity of Transformers and the constrained receptive field of CNN, which hinder them from achieving superior performance and efficiency in image restoration. To address these challenges, we propose a novel Multi-Scale State-Space Model-based (MS-Mamba) for efficient image restoration that enhances the capacity for multi-scale representation learning through our proposed global and regional SSM modules. Additionally, an Adaptive Gradient Block (AGB) and a Residual Fourier Block (RFB) are proposed to improve the network's detail extraction capabilities by capturing gradients in various directions and facilitating learning details in the frequency domain. Extensive experiments on nine public benchmarks across four classic image restoration tasks, image deraining, dehazing, denoising, and low-light enhancement, demonstrate that our proposed method achieves new state-of-the-art performance while maintaining low computational complexity. The source code will be publicly available.
NTIRE 2024 Restore Any Image Model in the Wild Challenge
May 16, 2024
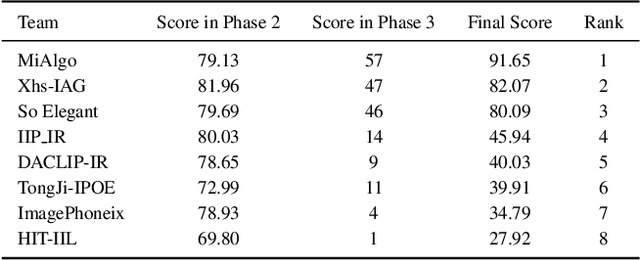

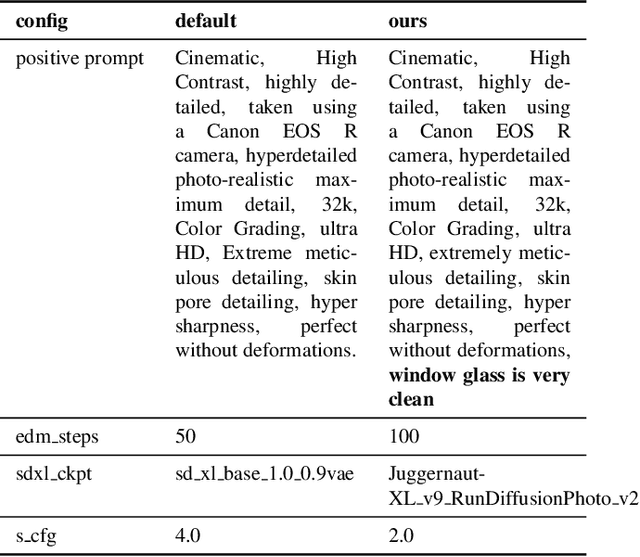
In this paper, we review the NTIRE 2024 challenge on Restore Any Image Model (RAIM) in the Wild. The RAIM challenge constructed a benchmark for image restoration in the wild, including real-world images with/without reference ground truth in various scenarios from real applications. The participants were required to restore the real-captured images from complex and unknown degradation, where generative perceptual quality and fidelity are desired in the restoration result. The challenge consisted of two tasks. Task one employed real referenced data pairs, where quantitative evaluation is available. Task two used unpaired images, and a comprehensive user study was conducted. The challenge attracted more than 200 registrations, where 39 of them submitted results with more than 400 submissions. Top-ranked methods improved the state-of-the-art restoration performance and obtained unanimous recognition from all 18 judges. The proposed datasets are available at https://drive.google.com/file/d/1DqbxUoiUqkAIkExu3jZAqoElr_nu1IXb/view?usp=sharing and the homepage of this challenge is at https://codalab.lisn.upsaclay.fr/competitions/17632.
Textual Prompt Guided Image Restoration
Dec 11, 2023

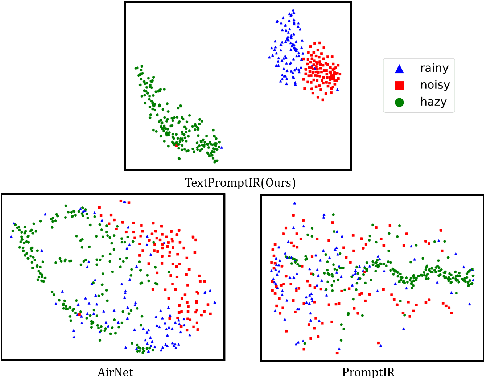

Image restoration has always been a cutting-edge topic in the academic and industrial fields of computer vision. Since degradation signals are often random and diverse, "all-in-one" models that can do blind image restoration have been concerned in recent years. Early works require training specialized headers and tails to handle each degradation of concern, which are manually cumbersome. Recent works focus on learning visual prompts from data distribution to identify degradation type. However, the prompts employed in most of models are non-text, lacking sufficient emphasis on the importance of human-in-the-loop. In this paper, an effective textual prompt guided image restoration model has been proposed. In this model, task-specific BERT is fine-tuned to accurately understand user's instructions and generating textual prompt guidance. Depth-wise multi-head transposed attentions and gated convolution modules are designed to bridge the gap between textual prompts and visual features. The proposed model has innovatively introduced semantic prompts into low-level visual domain. It highlights the potential to provide a natural, precise, and controllable way to perform image restoration tasks. Extensive experiments have been done on public denoising, dehazing and deraining datasets. The experiment results demonstrate that, compared with popular state-of-the-art methods, the proposed model can obtain much more superior performance, achieving accurate recognition and removal of degradation without increasing model's complexity. Related source codes and data will be publicly available on github site https://github.com/MoTong-AI-studio/TextPromptIR.
Reducing Capacity Gap in Knowledge Distillation with Review Mechanism for Crowd Counting
Jun 11, 2022

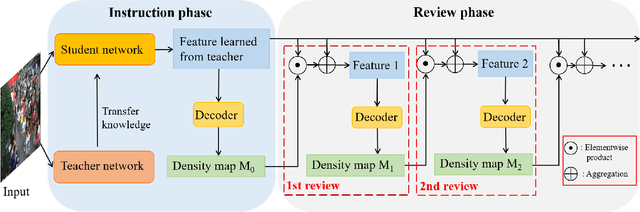
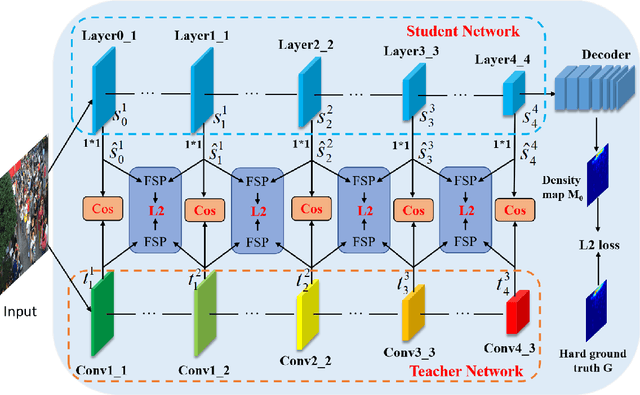
The lightweight crowd counting models, in particular knowledge distillation (KD) based models, have attracted rising attention in recent years due to their superiority on computational efficiency and hardware requirement. However, existing KD based models usually suffer from the capacity gap issue, resulting in the performance of the student network being limited by the teacher network. In this paper, we address this issue by introducing a novel review mechanism following KD models, motivated by the review mechanism of human-beings during the study. Thus, the proposed model is dubbed ReviewKD. The proposed model consists of an instruction phase and a review phase, where we firstly exploit a well-trained heavy teacher network to transfer its latent feature to a lightweight student network in the instruction phase, then in the review phase yield a refined estimate of the density map based on the learned feature through a review mechanism. The effectiveness of ReviewKD is demonstrated by a set of experiments over six benchmark datasets via comparing to the state-of-the-art models. Numerical results show that ReviewKD outperforms existing lightweight models for crowd counting, and can effectively alleviate the capacity gap issue, and particularly has the performance beyond the teacher network. Besides the lightweight models, we also show that the suggested review mechanism can be used as a plug-and-play module to further boost the performance of a kind of heavy crowd counting models without modifying the neural network architecture and introducing any additional model parameter.
Multiple Degradation and Reconstruction Network for Single Image Denoising via Knowledge Distillation
Apr 29, 2022
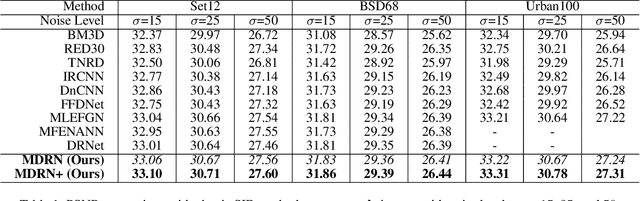

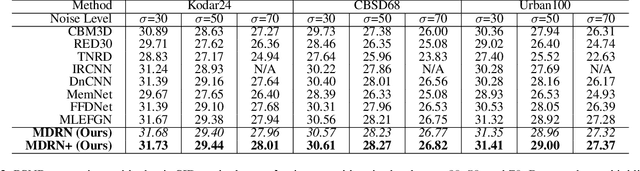
Single image denoising (SID) has achieved significant breakthroughs with the development of deep learning. However, the proposed methods are often accompanied by plenty of parameters, which greatly limits their application scenarios. Different from previous works that blindly increase the depth of the network, we explore the degradation mechanism of the noisy image and propose a lightweight Multiple Degradation and Reconstruction Network (MDRN) to progressively remove noise. Meanwhile, we propose two novel Heterogeneous Knowledge Distillation Strategies (HMDS) to enable MDRN to learn richer and more accurate features from heterogeneous models, which make it possible to reconstruct higher-quality denoised images under extreme conditions. Extensive experiments show that our MDRN achieves favorable performance against other SID models with fewer parameters. Meanwhile, plenty of ablation studies demonstrate that the introduced HMDS can improve the performance of tiny models or the model under high noise levels, which is extremely useful for related applications.
Contrastive Learning for Local and Global Learning MRI Reconstruction
Nov 30, 2021
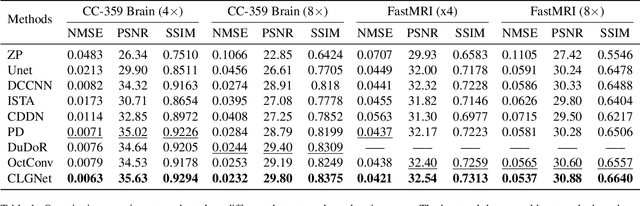
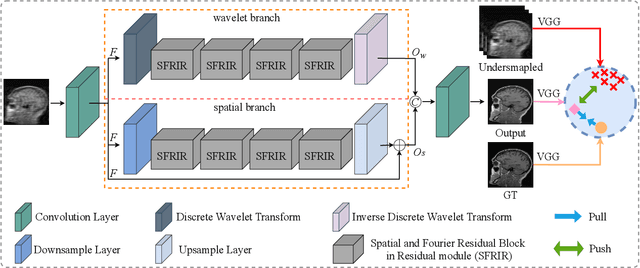
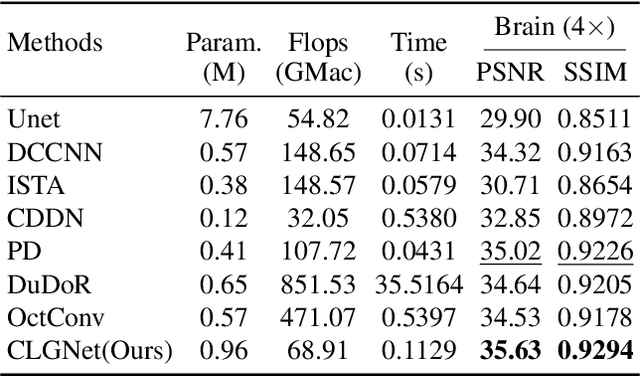
Magnetic Resonance Imaging (MRI) is an important medical imaging modality, while it requires a long acquisition time. To reduce the acquisition time, various methods have been proposed. However, these methods failed to reconstruct images with a clear structure for two main reasons. Firstly, similar patches widely exist in MR images, while most previous deep learning-based methods ignore this property and only adopt CNN to learn local information. Secondly, the existing methods only use clear images to constrain the upper bound of the solution space, while the lower bound is not constrained, so that a better parameter of the network cannot be obtained. To address these problems, we propose a Contrastive Learning for Local and Global Learning MRI Reconstruction Network (CLGNet). Specifically, according to the Fourier theory, each value in the Fourier domain is calculated from all the values in Spatial domain. Therefore, we propose a Spatial and Fourier Layer (SFL) to simultaneously learn the local and global information in Spatial and Fourier domains. Moreover, compared with self-attention and transformer, the SFL has a stronger learning ability and can achieve better performance in less time. Based on the SFL, we design a Spatial and Fourier Residual block as the main component of our model. Meanwhile, to constrain the lower bound and upper bound of the solution space, we introduce contrastive learning, which can pull the result closer to the clear image and push the result further away from the undersampled image. Extensive experimental results on different datasets and acceleration rates demonstrate that the proposed CLGNet achieves new state-of-the-art results.