 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for Local and Global Learning MRI Reconstruction
Nov 30, 2021
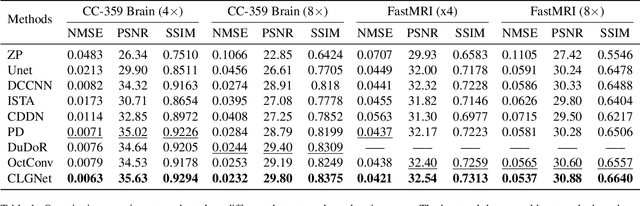
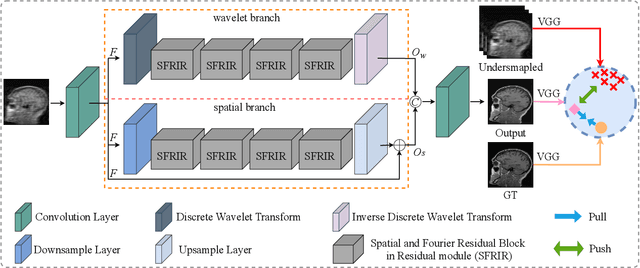
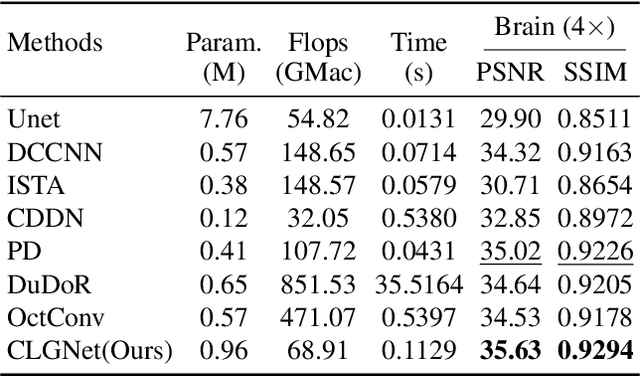
Magnetic Resonance Imaging (MRI) is an important medical imaging modality, while it requires a long acquisition time. To reduce the acquisition time, various methods have been proposed. However, these methods failed to reconstruct images with a clear structure for two main reasons. Firstly, similar patches widely exist in MR images, while most previous deep learning-based methods ignore this property and only adopt CNN to learn local information. Secondly, the existing methods only use clear images to constrain the upper bound of the solution space, while the lower bound is not constrained, so that a better parameter of the network cannot be obtained. To address these problems, we propose a Contrastive Learning for Local and Global Learning MRI Reconstruction Network (CLGNet). Specifically, according to the Fourier theory, each value in the Fourier domain is calculated from all the values in Spatial domain. Therefore, we propose a Spatial and Fourier Layer (SFL) to simultaneously learn the local and global information in Spatial and Fourier domains. Moreover, compared with self-attention and transformer, the SFL has a stronger learning ability and can achieve better performance in less time. Based on the SFL, we design a Spatial and Fourier Residual block as the main component of our model. Meanwhile, to constrain the lower bound and upper bound of the solution space, we introduce contrastive learning, which can pull the result closer to the clear image and push the result further away from the undersampled image. Extensive experimental results on different datasets and acceleration rates demonstrate that the proposed CLGNet achieves new state-of-the-art results.
ListReader: Extracting List-form Answers for Opinion Questions
Oct 22, 2021
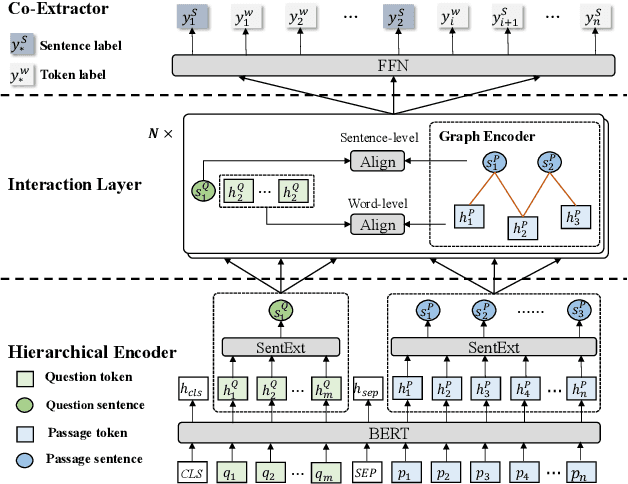

Question answering (QA) is a high-level ability of natural language processing. Most extractive ma-chine reading comprehension models focus on factoid questions (e.g., who, when, where) and restrict the output answer as a short and continuous span in the original passage. However, in real-world scenarios, many questions are non-factoid (e.g., how, why) and their answers are organized in the list format that contains multiple non-contiguous spans. Naturally, existing extractive models are by design unable to answer such questions. To address this issue, this paper proposes ListReader, a neural ex-tractive QA model for list-form answer. In addition to learning the alignment between the question and content, we introduce a heterogeneous graph neural network to explicitly capture the associations among candidate segments. Moreover, our model adopts a co-extraction setting that can extract either span- or sentence-level answers, allowing better applicability. Two large-scale datasets of different languages are constructed to support this study. Experimental results show that our model considerably outperforms various strong baselines. Further discussions provide an intuitive understanding of how our model works and where the performance gain comes from.
Topic-Guided Abstractive Multi-Document Summarization
Oct 21, 2021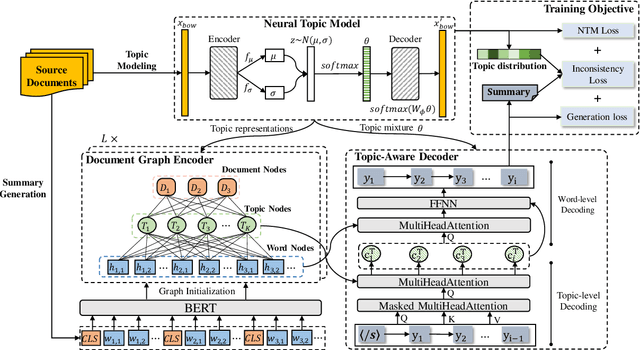
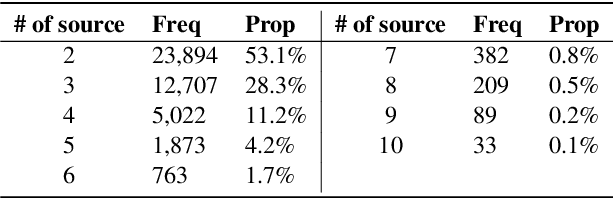
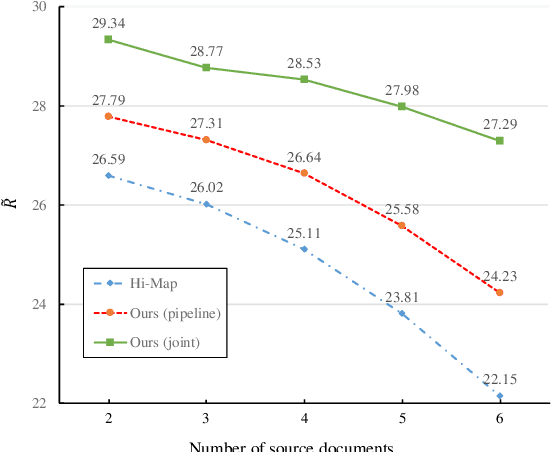
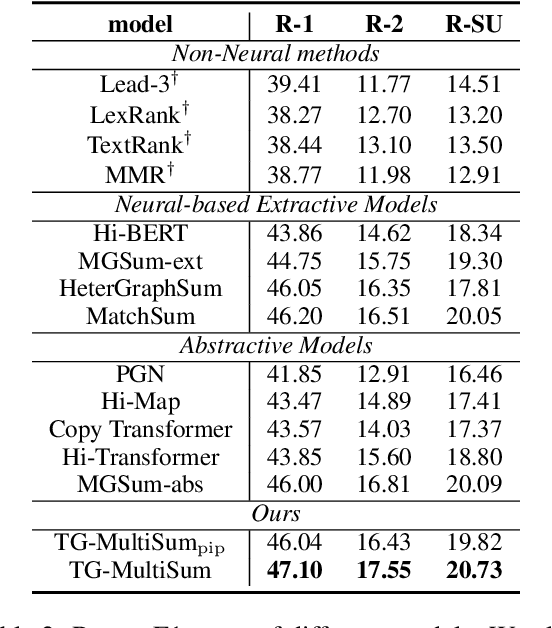
A critical point of multi-document summarization (MDS) is to learn the relations among various documents. In this paper, we propose a novel abstractive MDS model, in which we represent multiple documents as a heterogeneous graph, taking semantic nodes of different granularities into account, and then apply a graph-to-sequence framework to generate summaries. Moreover, we employ a neural topic model to jointly discover latent topics that can act as cross-document semantic units to bridge different documents and provide global information to guide the summary generation. Since topic extraction can be viewed as a special type of summarization that "summarizes" texts into a more abstract format, i.e., a topic distribution, we adopt a multi-task learning strategy to jointly train the topic and summarization module, allowing the promotion of each other. Experimental results on the Multi-News dataset demonstrate that our model outperforms previous state-of-the-art MDS models on both Rouge metrics and human evaluation, meanwhile learns high-quality topics.
Inducing Alignment Structure with Gated Graph Attention Networks for Sentence Matching
Oct 15, 2020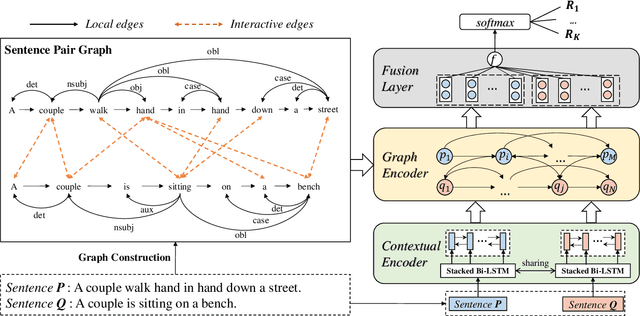
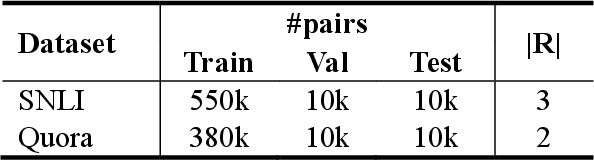
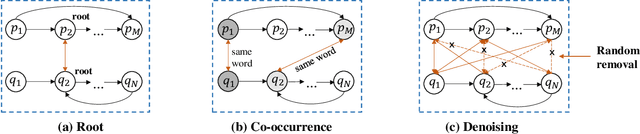
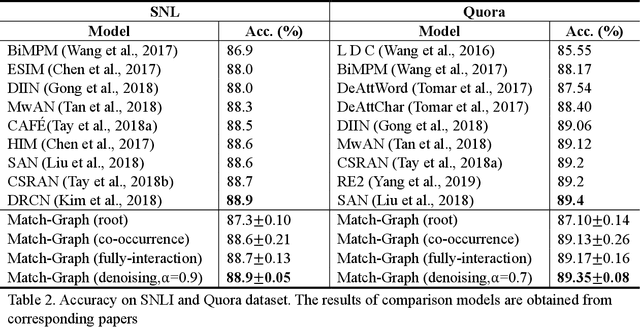
Sentence matching is a fundamental task of natural language processing with various applications. Most recent approaches adopt attention-based neural models to build word- or phrase-level alignment between two sentences. However, these models usually ignore the inherent structure within the sentences and fail to consider various dependency relationships among text units. To address these issues, this paper proposes a graph-based approach for sentence matching. First, we represent a sentence pair as a graph with several carefully design strategies. We then employ a novel gated graph attention network to encode the constructed graph for sentence matching. Experimental results demonstrate that our method substantially achieves state-of-the-art performance on two datasets across tasks of natural language and paraphrase identification. Further discussions show that our model can learn meaningful graph structure, indicating its superiority on improved interpretability.
Enhancing Extractive Text Summarization with Topic-Aware Graph Neural Networks
Oct 13, 2020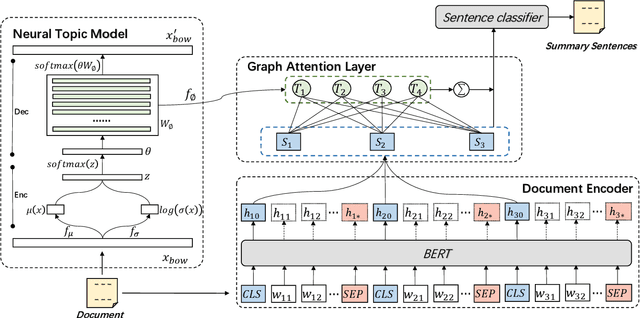
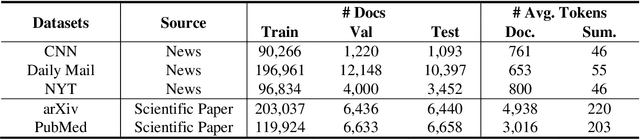
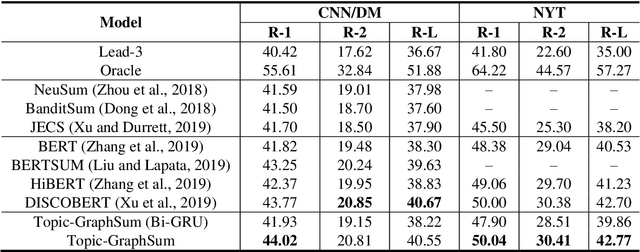
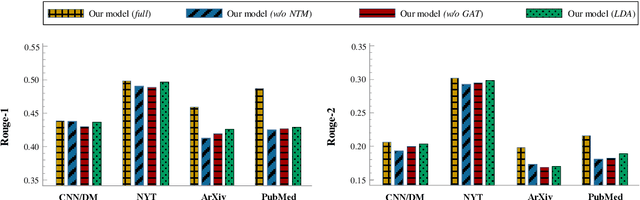
Text summarization aims to compress a textual document to a short summary while keeping salient information. Extractive approaches are widely used in text summarization because of their fluency and efficiency. However, most of existing extractive models hardly capture inter-sentence relationships, particularly in long documents. They also often ignore the effect of topical information on capturing important contents. To address these issues, this paper proposes a graph neural network (GNN)-based extractive summarization model, enabling to capture inter-sentence relationships efficiently via graph-structured document representation. Moreover, our model integrates a joint neural topic model (NTM) to discover latent topics, which can provide document-level features for sentence selection. The experimental results demonstrate that our model not only substantially achieves state-of-the-art results on CNN/DM and NYT datasets but also considerably outperforms existing approaches on scientific paper datasets consisting of much longer documents, indicating its better robustness in document genres and lengths. Further discussions show that topical information can help the model preselect salient contents from an entire document, which interprets its effectiveness in long document summarization.