 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Alignment Structure with Gated Graph Attention Networks for Sentence Matching
Oct 15, 2020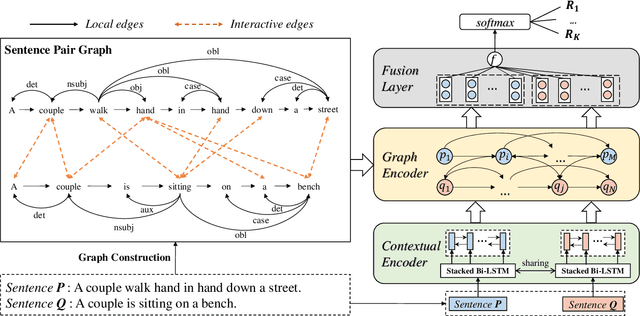
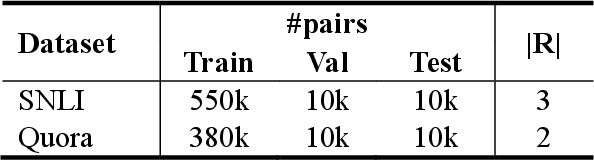
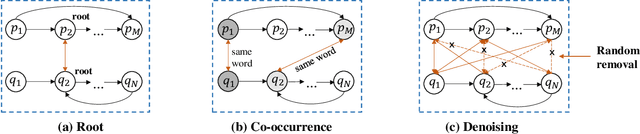
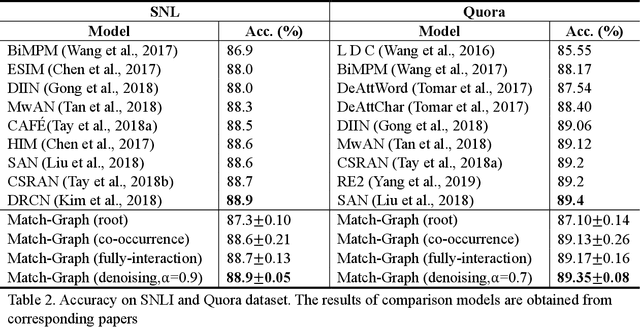
Sentence matching is a fundamental task of natural language processing with various applications. Most recent approaches adopt attention-based neural models to build word- or phrase-level alignment between two sentences. However, these models usually ignore the inherent structure within the sentences and fail to consider various dependency relationships among text units. To address these issues, this paper proposes a graph-based approach for sentence matching. First, we represent a sentence pair as a graph with several carefully design strategies. We then employ a novel gated graph attention network to encode the constructed graph for sentence matching. Experimental results demonstrate that our method substantially achieves state-of-the-art performance on two datasets across tasks of natural language and paraphrase identification. Further discussions show that our model can learn meaningful graph structure, indicating its superiority on improved interpretability.
Enhancing Extractive Text Summarization with Topic-Aware Graph Neural Networks
Oct 13, 2020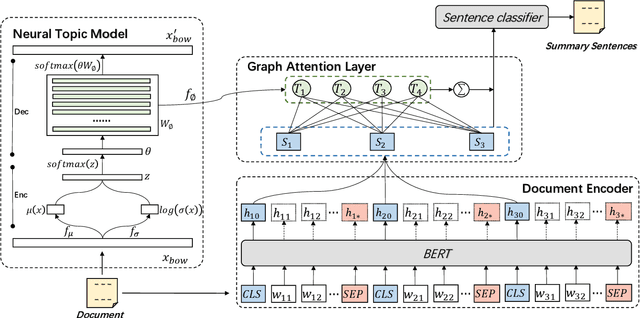
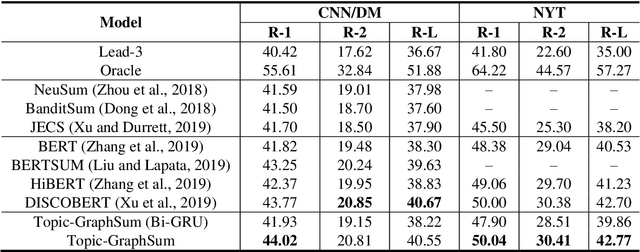
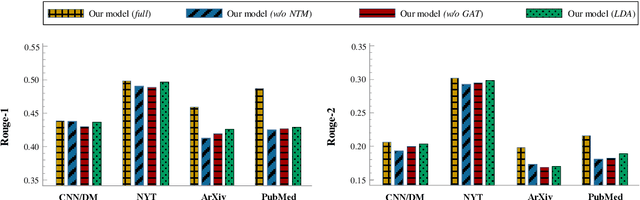
Text summarization aims to compress a textual document to a short summary while keeping salient information. Extractive approaches are widely used in text summarization because of their fluency and efficiency. However, most of existing extractive models hardly capture inter-sentence relationships, particularly in long documents. They also often ignore the effect of topical information on capturing important contents. To address these issues, this paper proposes a graph neural network (GNN)-based extractive summarization model, enabling to capture inter-sentence relationships efficiently via graph-structured document representation. Moreover, our model integrates a joint neural topic model (NTM) to discover latent topics, which can provide document-level features for sentence selection. The experimental results demonstrate that our model not only substantially achieves state-of-the-art results on CNN/DM and NYT datasets but also considerably outperforms existing approaches on scientific paper datasets consisting of much longer documents, indicating its better robustness in document genres and lengths. Further discussions show that topical information can help the model preselect salient contents from an entire document, which interprets its effectiveness in long document summarization.