 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Extractive Text Summarization with Topic-Aware Graph Neural Networks
Paper and Code
Oct 13, 2020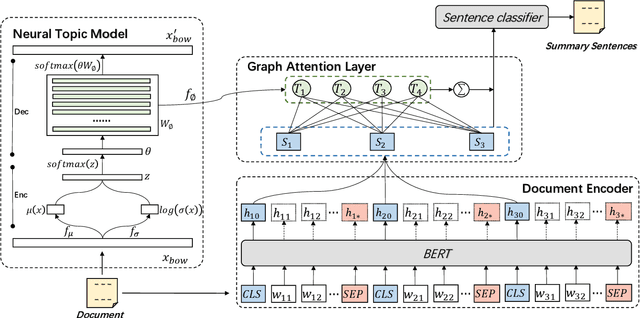
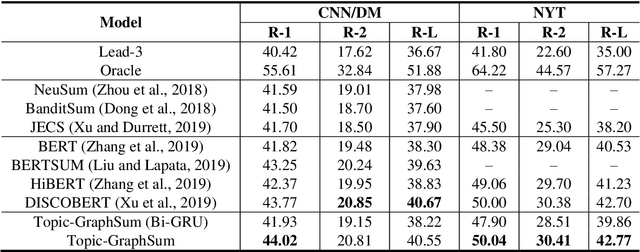
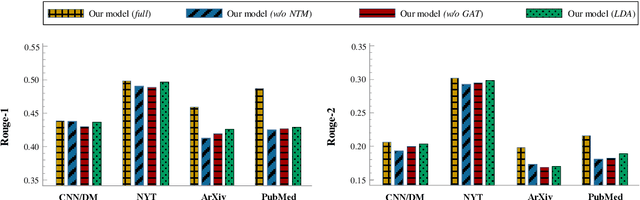
Text summarization aims to compress a textual document to a short summary while keeping salient information. Extractive approaches are widely used in text summarization because of their fluency and efficiency. However, most of existing extractive models hardly capture inter-sentence relationships, particularly in long documents. They also often ignore the effect of topical information on capturing important contents. To address these issues, this paper proposes a graph neural network (GNN)-based extractive summarization model, enabling to capture inter-sentence relationships efficiently via graph-structured document representation. Moreover, our model integrates a joint neural topic model (NTM) to discover latent topics, which can provide document-level features for sentence selection. The experimental results demonstrate that our model not only substantially achieves state-of-the-art results on CNN/DM and NYT datasets but also considerably outperforms existing approaches on scientific paper datasets consisting of much longer documents, indicating its better robustness in document genres and lengths. Further discussions show that topical information can help the model preselect salient contents from an entire document, which interprets its effectiveness in long document summarization.