 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Prompt Guided Image Restoration
Dec 11, 2023

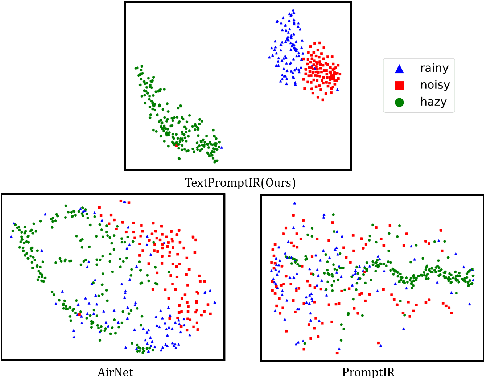

Image restoration has always been a cutting-edge topic in the academic and industrial fields of computer vision. Since degradation signals are often random and diverse, "all-in-one" models that can do blind image restoration have been concerned in recent years. Early works require training specialized headers and tails to handle each degradation of concern, which are manually cumbersome. Recent works focus on learning visual prompts from data distribution to identify degradation type. However, the prompts employed in most of models are non-text, lacking sufficient emphasis on the importance of human-in-the-loop. In this paper, an effective textual prompt guided image restoration model has been proposed. In this model, task-specific BERT is fine-tuned to accurately understand user's instructions and generating textual prompt guidance. Depth-wise multi-head transposed attentions and gated convolution modules are designed to bridge the gap between textual prompts and visual features. The proposed model has innovatively introduced semantic prompts into low-level visual domain. It highlights the potential to provide a natural, precise, and controllable way to perform image restoration tasks. Extensive experiments have been done on public denoising, dehazing and deraining datasets. The experiment results demonstrate that, compared with popular state-of-the-art methods, the proposed model can obtain much more superior performance, achieving accurate recognition and removal of degradation without increasing model's complexity. Related source codes and data will be publicly available on github site https://github.com/MoTong-AI-studio/TextPromptIR.