 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Deep Features in the Analysis of Tissue Microarray Images
Paper and Code
Nov 26, 2018
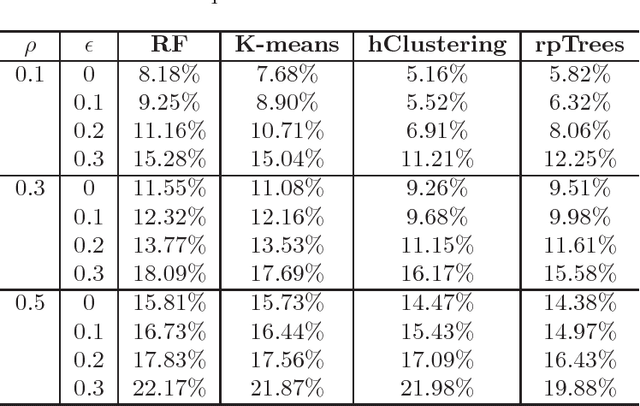

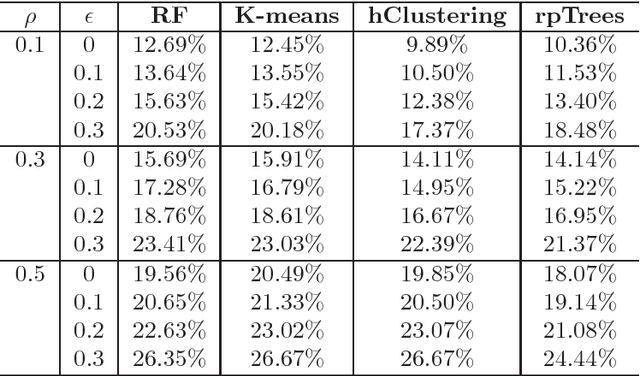
Tissue microarray (TMA) images have been used increasingly often in cancer studies and the validation of biomarkers. TACOMA---a cutting-edge automatic scoring algorithm for TMA images---is comparable to pathologists in terms of accuracy and repeatability. Here we consider how this algorithm may be further improved. Inspired by the recent success of deep learning, we propose to incorporate representations learnable through computation. We explore representations of a group nature through unsupervised learning, e.g., hierarchical clustering and recursive space partition. Information carried by clustering or spatial partitioning may be more concrete than the labels when the data are heterogeneous, or could help when the labels are noisy. The use of such information could be viewed as regularization in model fitting. It is motivated by major challenges in TMA image scoring---heterogeneity and label noise, and the cluster assumption in semi-supervised learning. Using this information on TMA images of breast cancer, we have reduced the error rate of TACOMA by about 6%. Further simulations on synthetic data provide insights on when such representations would likely help. Although we focus on TMAs, learnable representations of this type are expected to be applicable in other settings.