 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Redundancy Regulation for Balanced Multimodal Information Refinement
Nov 14, 2025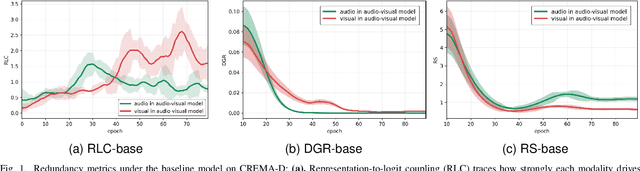
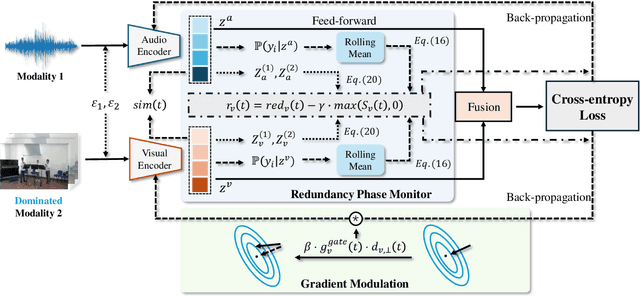
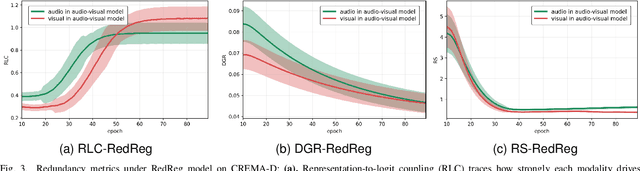
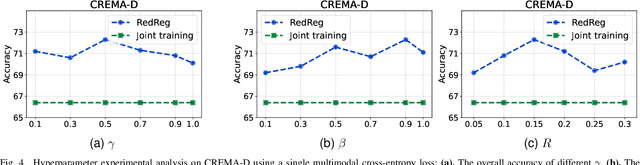
Multimodal learning aims to improve performance by leveraging data from multiple sources. During joint multimodal training, due to modality bias, the advantaged modality often dominates backpropagation, leading to imbalanced optimization. Existing methods still face two problems: First, the long-term dominance of the dominant modality weakens representation-output coupling in the late stages of training, resulting in the accumulation of redundant information. Second, previous methods often directly and uniformly adjust the gradients of the advantaged modality, ignoring the semantics and directionality between modalities. To address these limitations, we propose Adaptive Redundancy Regulation for Balanced Multimodal Information Refinement (RedReg), which is inspired by information bottleneck principle. Specifically, we construct a redundancy phase monitor that uses a joint criterion of effective gain growth rate and redundancy to trigger intervention only when redundancy is high. Furthermore, we design a co-information gating mechanism to estimate the contribution of the current dominant modality based on cross-modal semantics. When the task primarily relies on a single modality, the suppression term is automatically disabled to preserve modality-specific information. Finally, we project the gradient of the dominant modality onto the orthogonal complement of the joint multimodal gradient subspace and suppress the gradient according to redundancy. Experiments show that our method demonstrates superiority among current major methods in most scenarios. Ablation experiments verify the effectiveness of our method. The code is available at https://github.com/xia-zhe/RedReg.git
An End-to-End Room Geometry Constrained Depth Estimation Framework for Indoor Panorama Images
Oct 09, 2025Predicting spherical pixel depth from monocular $360^{\circ}$ indoor panoramas is critical for many vision applications. However, existing methods focus on pixel-level accuracy, causing oversmoothed room corners and noise sensitivity. In this paper, we propose a depth estimation framework based on room geometry constraints, which extracts room geometry information through layout prediction and integrates those information into the depth estimation process through background segmentation mechanism. At the model level, our framework comprises a shared feature encoder followed by task-specific decoders for layout estimation, depth estimation, and background segmentation. The shared encoder extracts multi-scale features, which are subsequently processed by individual decoders to generate initial predictions: a depth map, a room layout map, and a background segmentation map. Furthermore, our framework incorporates two strategies: a room geometry-based background depth resolving strategy and a background-segmentation-guided fusion mechanism. The proposed room-geometry-based background depth resolving strategy leverages the room layout and the depth decoder's output to generate the corresponding background depth map. Then, a background-segmentation-guided fusion strategy derives fusion weights for the background and coarse depth maps from the segmentation decoder's predictions. Extensive experimental results on the Stanford2D3D, Matterport3D and Structured3D datasets show that our proposed methods can achieve significantly superior performance than current open-source methods. Our code is available at https://github.com/emiyaning/RGCNet.
Multi-Timescale Motion-Decoupled Spiking Transformer for Audio-Visual Zero-Shot Learning
May 26, 2025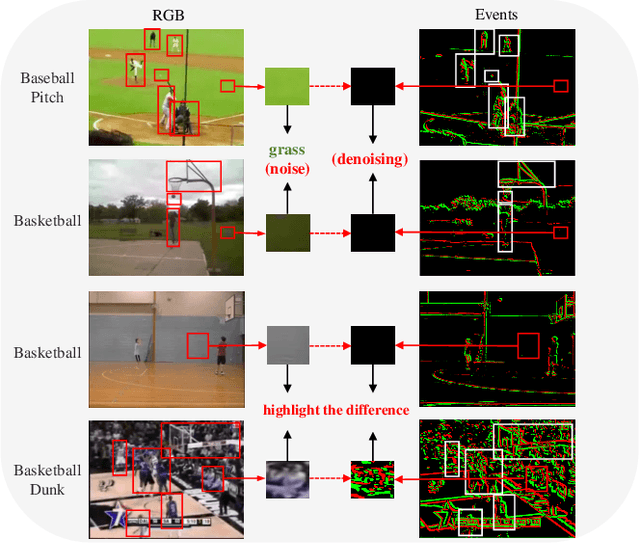



Audio-visual zero-shot learning (ZSL) has been extensively researched for its capability to classify video data from unseen classes during training. Nevertheless, current methodologies often struggle with background scene biases and inadequate motion detail. This paper proposes a novel dual-stream Multi-Timescale Motion-Decoupled Spiking Transformer (MDST++), which decouples contextual semantic information and sparse dynamic motion information. The recurrent joint learning unit is proposed to extract contextual semantic information and capture joint knowledge across various modalities to understand the environment of actions. By converting RGB images to events, our method captures motion information more accurately and mitigates background scene biases. Moreover, we introduce a discrepancy analysis block to model audio motion information. To enhance the robustness of SNNs in extracting temporal and motion cues, we dynamically adjust the threshold of Leaky Integrate-and-Fire neurons based on global motion and contextual semantic information. Our experiments validate the effectiveness of MDST++, demonstrating their consistent superiority over state-of-the-art methods on mainstream benchmarks. Additionally, incorporating motion and multi-timescale information significantly improves HM and ZSL accuracy by 26.2\% and 39.9\%.
Spiking Tucker Fusion Transformer for Audio-Visual Zero-Shot Learning
Jul 11, 2024

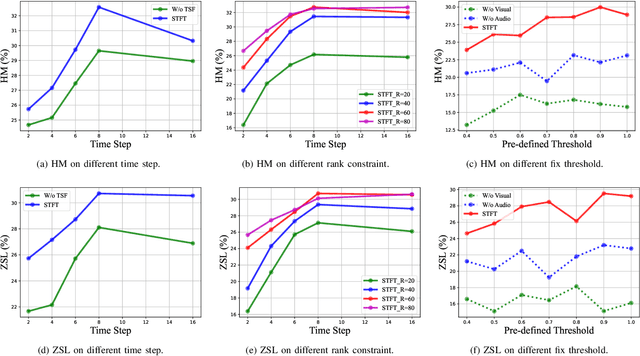
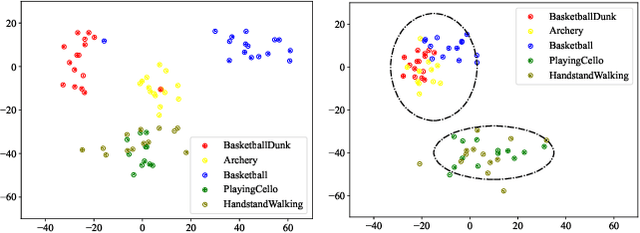
The spiking neural networks (SNNs) that efficiently encode temporal sequences have shown great potential in extracting audio-visual joint feature representations. However, coupling SNNs (binary spike sequences) with transformers (float-point sequences) to jointly explore the temporal-semantic information still facing challenges. In this paper, we introduce a novel Spiking Tucker Fusion Transformer (STFT) for audio-visual zero-shot learning (ZSL). The STFT leverage the temporal and semantic information from different time steps to generate robust representations. The time-step factor (TSF) is introduced to dynamically synthesis the subsequent inference information. To guide the formation of input membrane potentials and reduce the spike noise, we propose a global-local pooling (GLP) which combines the max and average pooling operations. Furthermore, the thresholds of the spiking neurons are dynamically adjusted based on semantic and temporal cues. Integrating the temporal and semantic information extracted by SNNs and Transformers are difficult due to the increased number of parameters in a straightforward bilinear model. To address this, we introduce a temporal-semantic Tucker fusion module, which achieves multi-scale fusion of SNN and Transformer outputs while maintaining full second-order interactions. Our experimental results demonstrate the effectiveness of the proposed approach in achieving state-of-the-art performance in three benchmark datasets. The harmonic mean (HM) improvement of VGGSound, UCF101 and ActivityNet are around 15.4\%, 3.9\%, and 14.9\%, respectively.
Probability-based Distance Estimation Model for 3D DV-Hop Localization in WSNs
Jan 11, 2024Localization is one of the pivotal issues in wireless sensor network applications. In 3D localization studies, most algorithms focus on enhancing the location prediction process, lacking theoretical derivation of the detection distance of an anchor node at the varying hops, engenders a localization performance bottleneck. To address this issue, we propose a probability-based average distance estimation (PADE) model that utilizes the probability distribution of node distances detected by an anchor node. The aim is to mathematically derive the average distances of nodes detected by an anchor node at different hops. First, we develop a probability-based maximum distance estimation (PMDE) model to calculate the upper bound of the distance detected by an anchor node. Then, we present the PADE model, which relies on the upper bound obtained of the distance by the PMDE model. Finally, the obtained average distance is used to construct a distance loss function, and it is embedded with the traditional distance loss function into a multi-objective genetic algorithm to predict the locations of unknown nodes. The experimental results demonstrate that the proposed method achieves state-of-the-art performance in random and multimodal distributed sensor networks. The average localization accuracy is improved by 3.49\%-12.66\% and 3.99%-22.34%, respectively.