 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambaTrack: A Simple Baseline for Multiple Object Tracking with State Space Model
Aug 17, 2024Tracking by detection has been the prevailing paradigm in the field of Multi-object Tracking (MOT). These methods typically rely on the Kalman Filter to estimate the future locations of objects, assuming linear object motion. However, they fall short when tracking objects exhibiting nonlinear and diverse motion in scenarios like dancing and sports. In addition, there has been limited focus on utilizing learning-based motion predictors in MOT. To address these challenges, we resort to exploring data-driven motion prediction methods. Inspired by the great expectation of state space models (SSMs), such as Mamba, in long-term sequence modeling with near-linear complexity, we introduce a Mamba-based motion model named Mamba moTion Predictor (MTP). MTP is designed to model the complex motion patterns of objects like dancers and athletes. Specifically, MTP takes the spatial-temporal location dynamics of objects as input, captures the motion pattern using a bi-Mamba encoding layer, and predicts the next motion. In real-world scenarios, objects may be missed due to occlusion or motion blur, leading to premature termination of their trajectories. To tackle this challenge, we further expand the application of MTP. We employ it in an autoregressive way to compensate for missing observations by utilizing its own predictions as inputs, thereby contributing to more consistent trajectories. Our proposed tracker, MambaTrack, demonstrates advanced performance on benchmarks such as Dancetrack and SportsMOT, which are characterized by complex motion and severe occlusion.
Phrase Grounding-based Style Transfer for Single-Domain Generalized Object Detection
Feb 05, 2024



Single-domain generalized object detection aims to enhance a model's generalizability to multiple unseen target domains using only data from a single source domain during training. This is a practical yet challenging task as it requires the model to address domain shift without incorporating target domain data into training. In this paper, we propose a novel phrase grounding-based style transfer (PGST) approach for the task. Specifically, we first define textual prompts to describe potential objects for each unseen target domain. Then, we leverage the grounded language-image pre-training (GLIP) model to learn the style of these target domains and achieve style transfer from the source to the target domain. The style-transferred source visual features are semantically rich and could be close to imaginary counterparts in the target domain. Finally, we employ these style-transferred visual features to fine-tune GLIP. By introducing imaginary counterparts, the detector could be effectively generalized to unseen target domains using only a single source domain for training. Extensive experimental results on five diverse weather driving benchmarks demonstrate our proposed approach achieves state-of-the-art performance, even surpassing some domain adaptive methods that incorporate target domain images into the training process.The source codes and pre-trained models will be made available.
MotionTrack: Learning Motion Predictor for Multiple Object Tracking
Jun 05, 2023



Significant advancements have been made in multi-object tracking (MOT) with the development of detection and re-identification (ReID) techniques. Despite these developments, the task of accurately tracking objects in scenarios with homogeneous appearance and heterogeneous motion remains challenging due to the insufficient discriminability of ReID features and the predominant use of linear motion models in MOT. In this context, we present a novel learnable motion predictor, named MotionTrack, which comprehensively incorporates two levels of granularity of motion features to enhance the modeling of temporal dynamics and facilitate accurate future motion prediction of individual objects. Specifically, the proposed approach adopts a self-attention mechanism to capture token-level information and a Dynamic MLP layer to model channel-level features. MotionTrack is a simple, online tracking approach. Our experimental results demonstrate that MotionTrack yields state-of-the-art performance on demanding datasets such as SportsMOT and Dancetrack, which feature highly nonlinear object motion. Notably, without fine-tuning on target datasets, MotionTrack also exhibits competitive performance on conventional benchmarks including MOT17 and MOT20.
Improving Unsupervised Domain Adaptation by Reducing Bi-level Feature Redundancy
Dec 28, 2020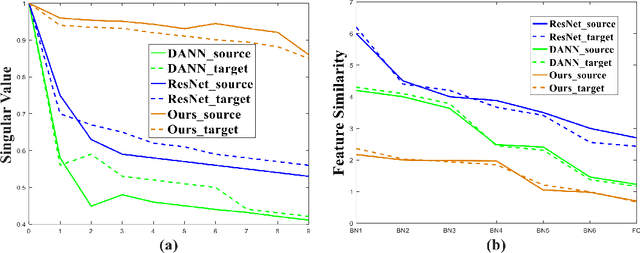
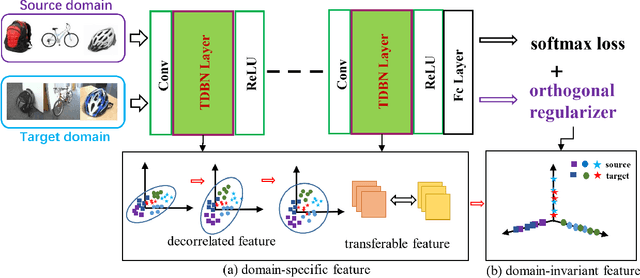

Reducing feature redundancy has shown beneficial effects for improving the accuracy of deep learning models, thus it is also indispensable for the models of unsupervised domain adaptation (UDA). Nevertheless, most recent efforts in the field of UDA ignores this point. Moreover, main schemes realizing this in general independent of UDA purely involve a single domain, thus might not be effective for cross-domain tasks. In this paper, we emphasize the significance of reducing feature redundancy for improving UDA in a bi-level way. For the first level, we try to ensure compact domain-specific features with a transferable decorrelated normalization module, which preserves specific domain information whilst easing the side effect of feature redundancy on the sequel domain-invariance. In the second level, domain-invariant feature redundancy caused by domain-shared representation is further mitigated via an alternative brand orthogonality for better generalization. These two novel aspects can be easily plugged into any BN-based backbone neural networks. Specifically, simply applying them to ResNet50 has achieved competitive performance to the state-of-the-arts on five popular benchmarks. Our code will be available at https://github.com/dreamkily/gUDA.
Enhancing the Association in Multi-Object Tracking via Neighbor Graph
Jul 01, 2020
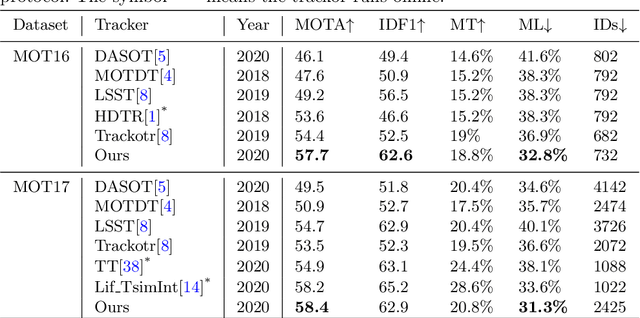
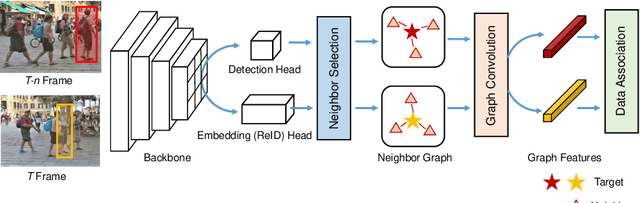

Most modern multi-object tracking (MOT) systems follow the tracking-by-detection paradigm. It first localizes the objects of interest, then extracting their individual appearance features to make data association. The individual features, however, are susceptible to the negative effects as occlusions, illumination variations and inaccurate detections, thus resulting in the mismatch in the association inference. In this work, we propose to handle this problem via making full use of the neighboring information. Our motivations derive from the observations that people tend to move in a group. As such, when an individual target's appearance is seriously changed, we can still identify it with the help of its neighbors. To this end, we first utilize the spatio-temporal relations produced by the tracking self to efficiently select suitable neighbors for the targets. Subsequently, we construct neighbor graph of the target and neighbors then employ the graph convolution networks (GCN) to learn the graph features. To the best of our knowledge, it is the first time to exploit neighbor cues via GCN in MOT. Finally, we test our approach on the MOT benchmarks and achieve state-of-the-art performance in online tracking.
MahNMF: Manhattan Non-negative Matrix Factorization
Jul 14, 2012
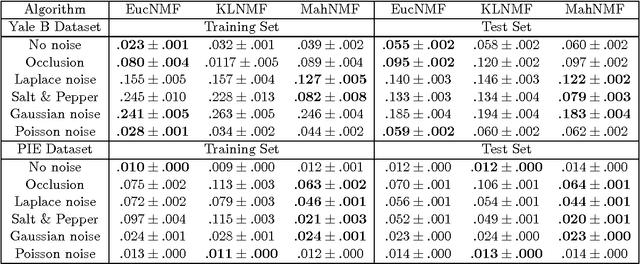
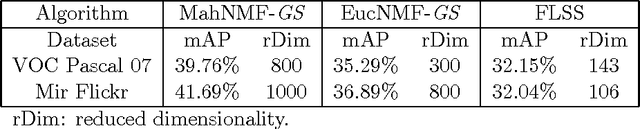
Non-negative matrix factorization (NMF) approximates a non-negative matrix $X$ by a product of two non-negative low-rank factor matrices $W$ and $H$. NMF and its extensions minimize either the Kullback-Leibler divergence or the Euclidean distance between $X$ and $W^T H$ to model the Poisson noise or the Gaussian noise. In practice, when the noise distribution is heavy tailed, they cannot perform well. This paper presents Manhattan NMF (MahNMF) which minimizes the Manhattan distance between $X$ and $W^T H$ for modeling the heavy tailed Laplacian noise. Similar to sparse and low-rank matrix decompositions, MahNMF robustly estimates the low-rank part and the sparse part of a non-negative matrix and thus performs effectively when data are contaminated by outliers. We extend MahNMF for various practical applications by developing box-constrained MahNMF, manifold regularized MahNMF, group sparse MahNMF, elastic net inducing MahNMF, and symmetric MahNMF. The major contribution of this paper lies in two fast optimization algorithms for MahNMF and its extensions: the rank-one residual iteration (RRI) method and Nesterov's smoothing method. In particular, by approximating the residual matrix by the outer product of one row of W and one row of $H$ in MahNMF, we develop an RRI method to iteratively update each variable of $W$ and $H$ in a closed form solution. Although RRI is efficient for small scale MahNMF and some of its extensions, it is neither scalable to large scale matrices nor flexible enough to optimize all MahNMF extensions. Since the objective functions of MahNMF and its extensions are neither convex nor smooth, we apply Nesterov's smoothing method to recursively optimize one factor matrix with another matrix fixed. By setting the smoothing parameter inversely proportional to the iteration number, we improve the approximation accuracy iteratively for both MahNMF and its extensions.