 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary Octree-Graph for 3D Scene Understanding
Paper and Code
Nov 25, 2024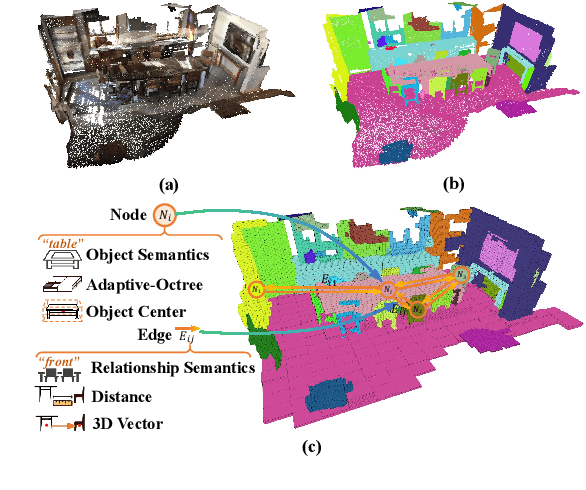
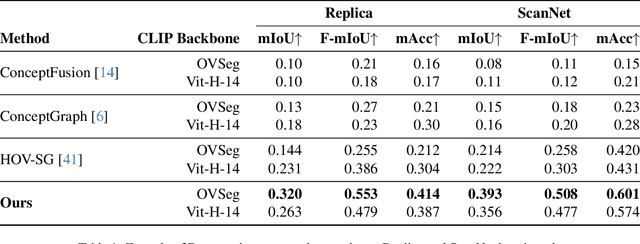
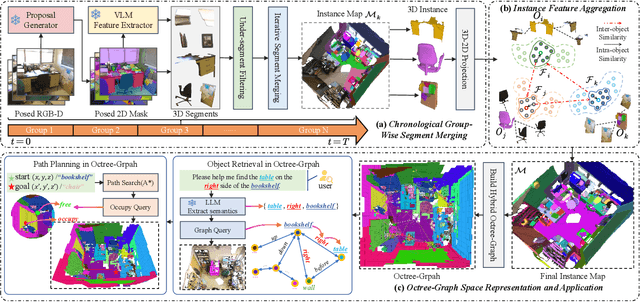
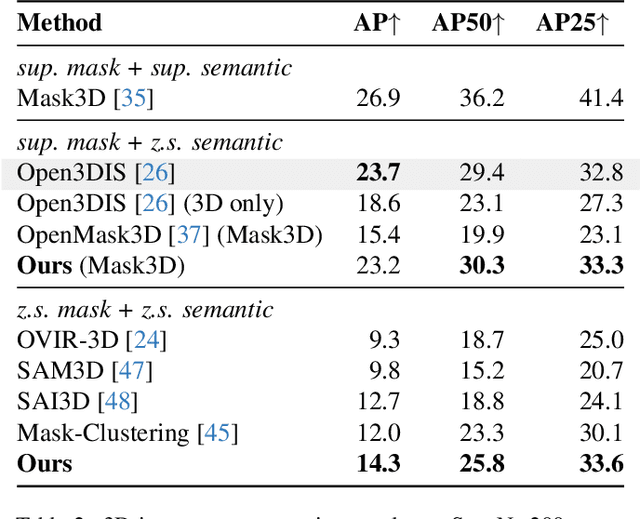
Open-vocabulary 3D scene understanding is indispensable for embodied agents. Recent works leverage pretrained vision-language models (VLMs) for object segmentation and project them to point clouds to build 3D maps. Despite progress, a point cloud is a set of unordered coordinates that requires substantial storage space and does not directly convey occupancy information or spatial relation, making existing methods inefficient for downstream tasks, e.g., path planning and complex text-based object retrieval. To address these issues, we propose Octree-Graph, a novel scene representation for open-vocabulary 3D scene understanding. Specifically, a Chronological Group-wise Segment Merging (CGSM) strategy and an Instance Feature Aggregation (IFA) algorithm are first designed to get 3D instances and corresponding semantic features. Subsequently, an adaptive-octree structure is developed that stores semantics and depicts the occupancy of an object adjustably according to its shape. Finally, the Octree-Graph is constructed where each adaptive-octree acts as a graph node, and edges describe the spatial relations among nodes. Extensive experiments on various tasks are conducted on several widely-used datasets, demonstrating the versatility and effectiveness of our method.