 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloorPlan-VLN: A New Paradigm for Floor Plan Guided Vision-Language Navigation
Mar 18, 2026Existing Vision-Language Navigation (VLN) task requires agents to follow verbose instructions, ignoring some potentially useful global spatial priors, limiting their capability to reason about spatial structures. Although human-readable spatial schematics (e.g., floor plans) are ubiquitous in real-world buildings, current agents lack the cognitive ability to comprehend and utilize them. To bridge this gap, we introduce \textbf{FloorPlan-VLN}, a new paradigm that leverages structured semantic floor plans as global spatial priors to enable navigation with only concise instructions. We first construct the FloorPlan-VLN dataset, which comprises over 10k episodes across 72 scenes. It pairs more than 100 semantically annotated floor plans with Matterport3D-based navigation trajectories and concise instructions that omit step-by-step guidance. Then, we propose a simple yet effective method \textbf{FP-Nav} that uses a dual-view, spatio-temporally aligned video sequence, and auxiliary reasoning tasks to align observations, floor plans, and instructions. When evaluated under this new benchmark, our method significantly outperforms adapted state-of-the-art VLN baselines, achieving more than a 60\% relative improvement in navigation success rate. Furthermore, comprehensive noise modeling and real-world deployments demonstrate the feasibility and robustness of FP-Nav to actuation drift and floor plan distortions. These results validate the effectiveness of floor plan guided navigation and highlight FloorPlan-VLN as a promising step toward more spatially intelligent navigation.
Xiaomi-Robotics-0: An Open-Sourced Vision-Language-Action Model with Real-Time Execution
Feb 13, 2026In this report, we introduce Xiaomi-Robotics-0, an advanced vision-language-action (VLA) model optimized for high performance and fast and smooth real-time execution. The key to our method lies in a carefully designed training recipe and deployment strategy. Xiaomi-Robotics-0 is first pre-trained on large-scale cross-embodiment robot trajectories and vision-language data, endowing it with broad and generalizable action-generation capabilities while avoiding catastrophic forgetting of the visual-semantic knowledge of the underlying pre-trained VLM. During post-training, we propose several techniques for training the VLA model for asynchronous execution to address the inference latency during real-robot rollouts. During deployment, we carefully align the timesteps of consecutive predicted action chunks to ensure continuous and seamless real-time rollouts. We evaluate Xiaomi-Robotics-0 extensively in simulation benchmarks and on two challenging real-robot tasks that require precise and dexterous bimanual manipulation. Results show that our method achieves state-of-the-art performance across all simulation benchmarks. Moreover, Xiaomi-Robotics-0 can roll out fast and smoothly on real robots using a consumer-grade GPU, achieving high success rates and throughput on both real-robot tasks. To facilitate future research, code and model checkpoints are open-sourced at https://xiaomi-robotics-0.github.io
FreqPolicy: Efficient Flow-based Visuomotor Policy via Frequency Consistency
Jun 10, 2025Generative modeling-based visuomotor policies have been widely adopted in robotic manipulation attributed to their ability to model multimodal action distributions. However, the high inference cost of multi-step sampling limits their applicability in real-time robotic systems. To address this issue, existing approaches accelerate the sampling process in generative modeling-based visuomotor policies by adapting acceleration techniques originally developed for image generation. Despite this progress, a major distinction remains: image generation typically involves producing independent samples without temporal dependencies, whereas robotic manipulation involves generating time-series action trajectories that require continuity and temporal coherence. To effectively exploit temporal information in robotic manipulation, we propose FreqPolicy, a novel approach that first imposes frequency consistency constraints on flow-based visuomotor policies. Our work enables the action model to capture temporal structure effectively while supporting efficient, high-quality one-step action generation. We introduce a frequency consistency constraint that enforces alignment of frequency-domain action features across different timesteps along the flow, thereby promoting convergence of one-step action generation toward the target distribution. In addition, we design an adaptive consistency loss to capture structural temporal variations inherent in robotic manipulation tasks. We assess FreqPolicy on 53 tasks across 3 simulation benchmarks, proving its superiority over existing one-step action generators. We further integrate FreqPolicy into the vision-language-action (VLA) model and achieve acceleration without performance degradation on the 40 tasks of Libero. Besides, we show efficiency and effectiveness in real-world robotic scenarios with an inference frequency 93.5Hz. The code will be publicly available.
Cross from Left to Right Brain: Adaptive Text Dreamer for Vision-and-Language Navigation
May 27, 2025Vision-and-Language Navigation (VLN) requires the agent to navigate by following natural instructions under partial observability, making it difficult to align perception with language. Recent methods mitigate this by imagining future scenes, yet they rely on vision-based synthesis, leading to high computational cost and redundant details. To this end, we propose to adaptively imagine key environmental semantics via \textit{language} form, enabling a more reliable and efficient strategy. Specifically, we introduce a novel Adaptive Text Dreamer (ATD), a dual-branch self-guided imagination policy built upon a large language model (LLM). ATD is designed with a human-like left-right brain architecture, where the left brain focuses on logical integration, and the right brain is responsible for imaginative prediction of future scenes. To achieve this, we fine-tune only the Q-former within both brains to efficiently activate domain-specific knowledge in the LLM, enabling dynamic updates of logical reasoning and imagination during navigation. Furthermore, we introduce a cross-interaction mechanism to regularize the imagined outputs and inject them into a navigation expert module, allowing ATD to jointly exploit both the reasoning capacity of the LLM and the expertise of the navigation model. We conduct extensive experiments on the R2R benchmark, where ATD achieves state-of-the-art performance with fewer parameters. The code is \href{https://github.com/zhangpingrui/Adaptive-Text-Dreamer}{here}.
OpenFly: A Versatile Toolchain and Large-scale Benchmark for Aerial Vision-Language Navigation
Feb 25, 2025Vision-Language Navigation (VLN) aims to guide agents through an environment by leveraging both language instructions and visual cues, playing a pivotal role in embodied AI. Indoor VLN has been extensively studied, whereas outdoor aerial VLN remains underexplored. The potential reason is that outdoor aerial view encompasses vast areas, making data collection more challenging, which results in a lack of benchmarks. To address this problem, we propose OpenFly, a platform comprising a versatile toolchain and large-scale benchmark for aerial VLN. Firstly, we develop a highly automated toolchain for data collection, enabling automatic point cloud acquisition, scene semantic segmentation, flight trajectory creation, and instruction generation. Secondly, based on the toolchain, we construct a large-scale aerial VLN dataset with 100k trajectories, covering diverse heights and lengths across 18 scenes. The corresponding visual data are generated using various rendering engines and advanced techniques, including Unreal Engine, GTA V, Google Earth, and 3D Gaussian Splatting (3D GS). All data exhibit high visual quality. Particularly, 3D GS supports real-to-sim rendering, further enhancing the realism of the dataset. Thirdly, we propose OpenFly-Agent, a keyframe-aware VLN model, which takes language instructions, current observations, and historical keyframes as input, and outputs flight actions directly. Extensive analyses and experiments are conducted, showcasing the superiority of our OpenFly platform and OpenFly-Agent. The toolchain, dataset, and codes will be open-sourced.
Constraint-Aware Zero-Shot Vision-Language Navigation in Continuous Environments
Dec 13, 2024We address the task of Vision-Language Navigation in Continuous Environments (VLN-CE) under the zero-shot setting. Zero-shot VLN-CE is particularly challenging due to the absence of expert demonstrations for training and minimal environment structural prior to guide navigation. To confront these challenges, we propose a Constraint-Aware Navigator (CA-Nav), which reframes zero-shot VLN-CE as a sequential, constraint-aware sub-instruction completion process. CA-Nav continuously translates sub-instructions into navigation plans using two core modules: the Constraint-Aware Sub-instruction Manager (CSM) and the Constraint-Aware Value Mapper (CVM). CSM defines the completion criteria for decomposed sub-instructions as constraints and tracks navigation progress by switching sub-instructions in a constraint-aware manner. CVM, guided by CSM's constraints, generates a value map on the fly and refines it using superpixel clustering to improve navigation stability. CA-Nav achieves the state-of-the-art performance on two VLN-CE benchmarks, surpassing the previous best method by 12 percent and 13 percent in Success Rate on the validation unseen splits of R2R-CE and RxR-CE, respectively. Moreover, CA-Nav demonstrates its effectiveness in real-world robot deployments across various indoor scenes and instructions.
Open-Vocabulary Octree-Graph for 3D Scene Understanding
Nov 25, 2024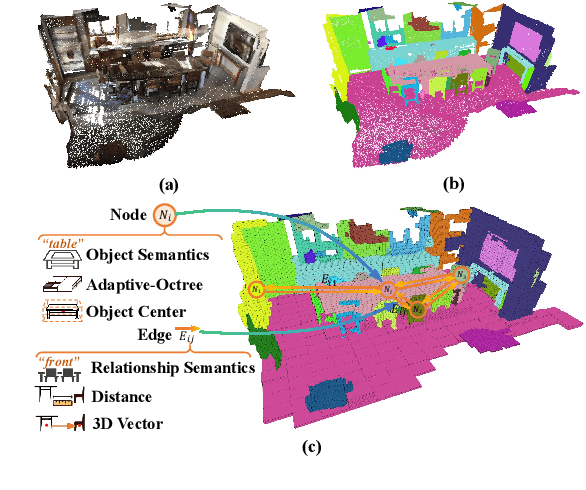
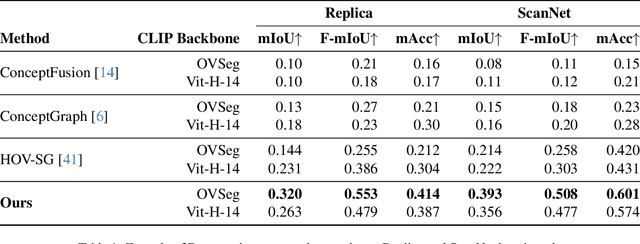
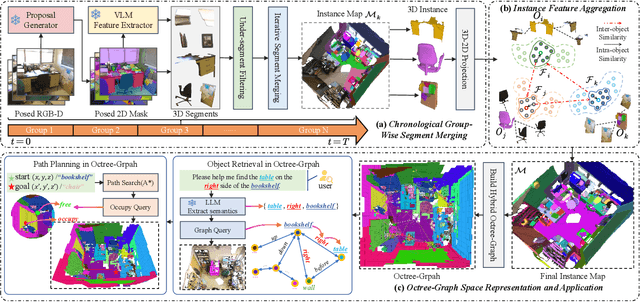
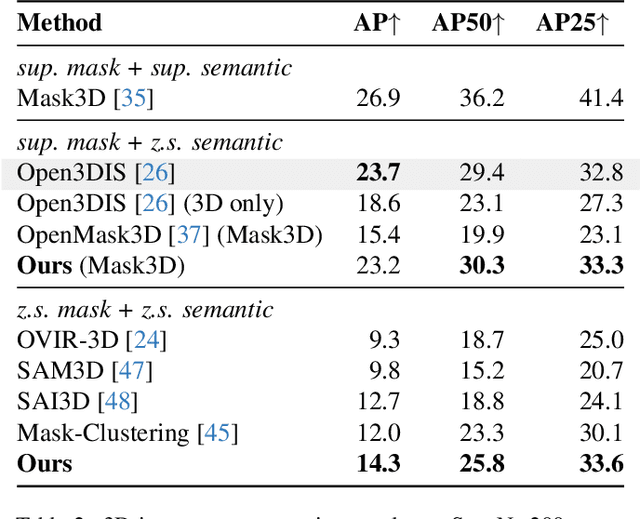
Open-vocabulary 3D scene understanding is indispensable for embodied agents. Recent works leverage pretrained vision-language models (VLMs) for object segmentation and project them to point clouds to build 3D maps. Despite progress, a point cloud is a set of unordered coordinates that requires substantial storage space and does not directly convey occupancy information or spatial relation, making existing methods inefficient for downstream tasks, e.g., path planning and complex text-based object retrieval. To address these issues, we propose Octree-Graph, a novel scene representation for open-vocabulary 3D scene understanding. Specifically, a Chronological Group-wise Segment Merging (CGSM) strategy and an Instance Feature Aggregation (IFA) algorithm are first designed to get 3D instances and corresponding semantic features. Subsequently, an adaptive-octree structure is developed that stores semantics and depicts the occupancy of an object adjustably according to its shape. Finally, the Octree-Graph is constructed where each adaptive-octree acts as a graph node, and edges describe the spatial relations among nodes. Extensive experiments on various tasks are conducted on several widely-used datasets, demonstrating the versatility and effectiveness of our method.
Target-Grounded Graph-Aware Transformer for Aerial Vision-and-Dialog Navigation
Sep 04, 2023



This report details the methods of the winning entry of the AVDN Challenge in ICCV CLVL 2023. The competition addresses the Aerial Navigation from Dialog History (ANDH) task, which requires a drone agent to associate dialog history with aerial observations to reach the destination. For better cross-modal grounding abilities of the drone agent, we propose a Target-Grounded Graph-Aware Transformer (TG-GAT) framework. Concretely, TG-GAT first leverages a graph-aware transformer to capture spatiotemporal dependency, which benefits navigation state tracking and robust action planning. In addition,an auxiliary visual grounding task is devised to boost the agent's awareness of referred landmarks. Moreover, a hybrid augmentation strategy based on large language models is utilized to mitigate data scarcity limitations. Our TG-GAT framework won the AVDN Challenge, with 2.2% and 3.0% absolute improvements over the baseline on SPL and SR metrics, respectively. The code is available at https://github.com/yifeisu/TG-GAT.