 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Audio-Visual Navigation in Continuous Environments
Mar 20, 2026Audio-visual navigation enables embodied agents to navigate toward sound-emitting targets by leveraging both auditory and visual cues. However, most existing approaches rely on precomputed room impulse responses (RIRs) for binaural audio rendering, restricting agents to discrete grid positions and leading to spatially discontinuous observations. To establish a more realistic setting, we introduce Semantic Audio-Visual Navigation in Continuous Environments (SAVN-CE), where agents can move freely in 3D spaces and perceive temporally and spatially coherent audio-visual streams. In this setting, targets may intermittently become silent or stop emitting sound entirely, causing agents to lose goal information. To tackle this challenge, we propose MAGNet, a multimodal transformer-based model that jointly encodes spatial and semantic goal representations and integrates historical context with self-motion cues to enable memory-augmented goal reasoning. Comprehensive experiments demonstrate that MAGNet significantly outperforms state-of-the-art methods, achieving up to a 12.1\% absolute improvement in success rate. These results also highlight its robustness to short-duration sounds and long-distance navigation scenarios. The code is available at https://github.com/yichenzeng24/SAVN-CE.
FloorPlan-VLN: A New Paradigm for Floor Plan Guided Vision-Language Navigation
Mar 18, 2026Existing Vision-Language Navigation (VLN) task requires agents to follow verbose instructions, ignoring some potentially useful global spatial priors, limiting their capability to reason about spatial structures. Although human-readable spatial schematics (e.g., floor plans) are ubiquitous in real-world buildings, current agents lack the cognitive ability to comprehend and utilize them. To bridge this gap, we introduce \textbf{FloorPlan-VLN}, a new paradigm that leverages structured semantic floor plans as global spatial priors to enable navigation with only concise instructions. We first construct the FloorPlan-VLN dataset, which comprises over 10k episodes across 72 scenes. It pairs more than 100 semantically annotated floor plans with Matterport3D-based navigation trajectories and concise instructions that omit step-by-step guidance. Then, we propose a simple yet effective method \textbf{FP-Nav} that uses a dual-view, spatio-temporally aligned video sequence, and auxiliary reasoning tasks to align observations, floor plans, and instructions. When evaluated under this new benchmark, our method significantly outperforms adapted state-of-the-art VLN baselines, achieving more than a 60\% relative improvement in navigation success rate. Furthermore, comprehensive noise modeling and real-world deployments demonstrate the feasibility and robustness of FP-Nav to actuation drift and floor plan distortions. These results validate the effectiveness of floor plan guided navigation and highlight FloorPlan-VLN as a promising step toward more spatially intelligent navigation.
Mem-PAL: Towards Memory-based Personalized Dialogue Assistants for Long-term User-Agent Interaction
Nov 17, 2025With the rise of smart personal devices, service-oriented human-agent interactions have become increasingly prevalent. This trend highlights the need for personalized dialogue assistants that can understand user-specific traits to accurately interpret requirements and tailor responses to individual preferences. However, existing approaches often overlook the complexities of long-term interactions and fail to capture users' subjective characteristics. To address these gaps, we present PAL-Bench, a new benchmark designed to evaluate the personalization capabilities of service-oriented assistants in long-term user-agent interactions. In the absence of available real-world data, we develop a multi-step LLM-based synthesis pipeline, which is further verified and refined by human annotators. This process yields PAL-Set, the first Chinese dataset comprising multi-session user logs and dialogue histories, which serves as the foundation for PAL-Bench. Furthermore, to improve personalized service-oriented interactions, we propose H$^2$Memory, a hierarchical and heterogeneous memory framework that incorporates retrieval-augmented generation to improve personalized response generation. Comprehensive experiments on both our PAL-Bench and an external dataset demonstrate the effectiveness of the proposed memory framework.
EC-Flow: Enabling Versatile Robotic Manipulation from Action-Unlabeled Videos via Embodiment-Centric Flow
Jul 08, 2025
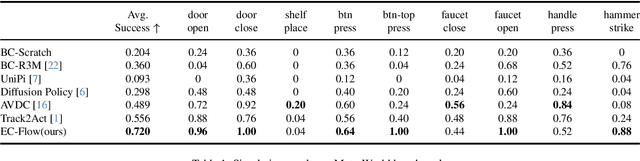
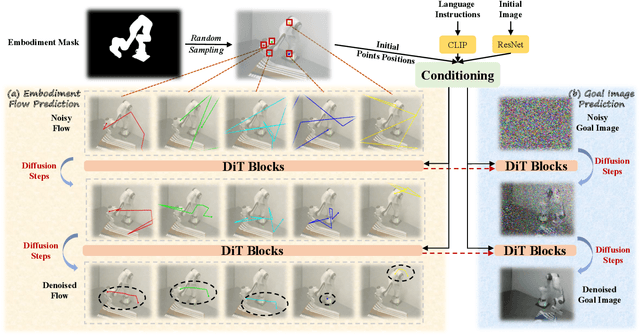
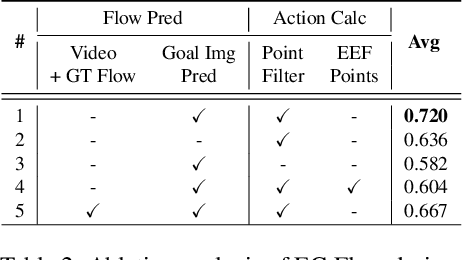
Current language-guided robotic manipulation systems often require low-level action-labeled datasets for imitation learning. While object-centric flow prediction methods mitigate this issue, they remain limited to scenarios involving rigid objects with clear displacement and minimal occlusion. In this work, we present Embodiment-Centric Flow (EC-Flow), a framework that directly learns manipulation from action-unlabeled videos by predicting embodiment-centric flow. Our key insight is that incorporating the embodiment's inherent kinematics significantly enhances generalization to versatile manipulation scenarios, including deformable object handling, occlusions, and non-object-displacement tasks. To connect the EC-Flow with language instructions and object interactions, we further introduce a goal-alignment module by jointly optimizing movement consistency and goal-image prediction. Moreover, translating EC-Flow to executable robot actions only requires a standard robot URDF (Unified Robot Description Format) file to specify kinematic constraints across joints, which makes it easy to use in practice. We validate EC-Flow on both simulation (Meta-World) and real-world tasks, demonstrating its state-of-the-art performance in occluded object handling (62% improvement), deformable object manipulation (45% improvement), and non-object-displacement tasks (80% improvement) than prior state-of-the-art object-centric flow methods. For more information, see our project website at https://ec-flow1.github.io .
Doc-CoB: Enhancing Multi-Modal Document Understanding with Visual Chain-of-Boxes Reasoning
May 24, 2025



Multimodal large language models (MLLMs) have made significant progress in document understanding. However, the information-dense nature of document images still poses challenges, as most queries depend on only a few relevant regions, with the rest being redundant. Existing one-pass MLLMs process entire document images without considering query relevance, often failing to focus on critical regions and producing unfaithful responses. Inspired by the human coarse-to-fine reading pattern, we introduce Doc-CoB (Chain-of-Box), a simple-yet-effective mechanism that integrates human-style visual reasoning into MLLM without modifying its architecture. Our method allows the model to autonomously select the set of regions (boxes) most relevant to the query, and then focus attention on them for further understanding. We first design a fully automatic pipeline, integrating a commercial MLLM with a layout analyzer, to generate 249k training samples with intermediate visual reasoning supervision. Then we incorporate two enabling tasks that improve box identification and box-query reasoning, which together enhance document understanding. Extensive experiments on seven benchmarks with four popular models show that Doc-CoB significantly improves performance, demonstrating its effectiveness and wide applicability. All code, data, and models will be released publicly.
Meta-Reflection: A Feedback-Free Reflection Learning Framework
Dec 18, 2024



Despite the remarkable capabilities of large language models (LLMs) in natural language understanding and reasoning, they often display undesirable behaviors, such as generating hallucinations and unfaithful reasoning. A prevalent strategy to mitigate these issues is the use of reflection, which refines responses through an iterative process. However, while promising, reflection heavily relies on high-quality external feedback and requires iterative multi-agent inference processes, thus hindering its practical application. In this paper, we propose Meta-Reflection, a novel feedback-free reflection mechanism that necessitates only a single inference pass without external feedback. Motivated by the human ability to remember and retrieve reflections from past experiences when encountering similar problems, Meta-Reflection integrates reflective insights into a codebook, allowing the historical insights to be stored, retrieved, and used to guide LLMs in problem-solving. To thoroughly investigate and evaluate the practicality of Meta-Reflection in real-world scenarios, we introduce an industrial e-commerce benchmark named E-commerce Customer Intent Detection (ECID). Extensive experiments conducted on both public datasets and the ECID benchmark highlight the effectiveness and efficiency of our proposed approach.
Constraint-Aware Zero-Shot Vision-Language Navigation in Continuous Environments
Dec 13, 2024We address the task of Vision-Language Navigation in Continuous Environments (VLN-CE) under the zero-shot setting. Zero-shot VLN-CE is particularly challenging due to the absence of expert demonstrations for training and minimal environment structural prior to guide navigation. To confront these challenges, we propose a Constraint-Aware Navigator (CA-Nav), which reframes zero-shot VLN-CE as a sequential, constraint-aware sub-instruction completion process. CA-Nav continuously translates sub-instructions into navigation plans using two core modules: the Constraint-Aware Sub-instruction Manager (CSM) and the Constraint-Aware Value Mapper (CVM). CSM defines the completion criteria for decomposed sub-instructions as constraints and tracks navigation progress by switching sub-instructions in a constraint-aware manner. CVM, guided by CSM's constraints, generates a value map on the fly and refines it using superpixel clustering to improve navigation stability. CA-Nav achieves the state-of-the-art performance on two VLN-CE benchmarks, surpassing the previous best method by 12 percent and 13 percent in Success Rate on the validation unseen splits of R2R-CE and RxR-CE, respectively. Moreover, CA-Nav demonstrates its effectiveness in real-world robot deployments across various indoor scenes and instructions.
Target-Grounded Graph-Aware Transformer for Aerial Vision-and-Dialog Navigation
Sep 04, 2023



This report details the methods of the winning entry of the AVDN Challenge in ICCV CLVL 2023. The competition addresses the Aerial Navigation from Dialog History (ANDH) task, which requires a drone agent to associate dialog history with aerial observations to reach the destination. For better cross-modal grounding abilities of the drone agent, we propose a Target-Grounded Graph-Aware Transformer (TG-GAT) framework. Concretely, TG-GAT first leverages a graph-aware transformer to capture spatiotemporal dependency, which benefits navigation state tracking and robust action planning. In addition,an auxiliary visual grounding task is devised to boost the agent's awareness of referred landmarks. Moreover, a hybrid augmentation strategy based on large language models is utilized to mitigate data scarcity limitations. Our TG-GAT framework won the AVDN Challenge, with 2.2% and 3.0% absolute improvements over the baseline on SPL and SR metrics, respectively. The code is available at https://github.com/yifeisu/TG-GAT.