 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPFQA: A Long-Tail Professional Forum-based Benchmark for LLM Evaluation
Nov 09, 2025Large Language Models (LLMs) have made rapid progress in reasoning, question answering, and professional applications; however, their true capabilities remain difficult to evaluate using existing benchmarks. Current datasets often focus on simplified tasks or artificial scenarios, overlooking long-tail knowledge and the complexities of real-world applications. To bridge this gap, we propose LPFQA, a long-tail knowledge-based benchmark derived from authentic professional forums across 20 academic and industrial fields, covering 502 tasks grounded in practical expertise. LPFQA introduces four key innovations: fine-grained evaluation dimensions that target knowledge depth, reasoning, terminology comprehension, and contextual analysis; a hierarchical difficulty structure that ensures semantic clarity and unique answers; authentic professional scenario modeling with realistic user personas; and interdisciplinary knowledge integration across diverse domains. We evaluated 12 mainstream LLMs on LPFQA and observed significant performance disparities, especially in specialized reasoning tasks. LPFQA provides a robust, authentic, and discriminative benchmark for advancing LLM evaluation and guiding future model development.
Doc-CoB: Enhancing Multi-Modal Document Understanding with Visual Chain-of-Boxes Reasoning
May 24, 2025



Multimodal large language models (MLLMs) have made significant progress in document understanding. However, the information-dense nature of document images still poses challenges, as most queries depend on only a few relevant regions, with the rest being redundant. Existing one-pass MLLMs process entire document images without considering query relevance, often failing to focus on critical regions and producing unfaithful responses. Inspired by the human coarse-to-fine reading pattern, we introduce Doc-CoB (Chain-of-Box), a simple-yet-effective mechanism that integrates human-style visual reasoning into MLLM without modifying its architecture. Our method allows the model to autonomously select the set of regions (boxes) most relevant to the query, and then focus attention on them for further understanding. We first design a fully automatic pipeline, integrating a commercial MLLM with a layout analyzer, to generate 249k training samples with intermediate visual reasoning supervision. Then we incorporate two enabling tasks that improve box identification and box-query reasoning, which together enhance document understanding. Extensive experiments on seven benchmarks with four popular models show that Doc-CoB significantly improves performance, demonstrating its effectiveness and wide applicability. All code, data, and models will be released publicly.
SCDiar: a streaming diarization system based on speaker change detection and speech recognition
Jan 28, 2025


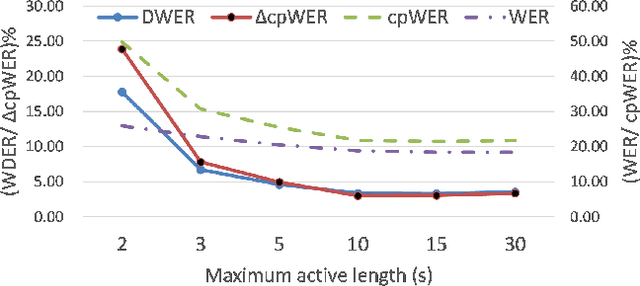
In hours-long meeting scenarios, real-time speech stream often struggles with achieving accurate speaker diarization, commonly leading to speaker identification and speaker count errors. To address this challenge, we propose SCDiar, a system that operates on speech segments, split at the token level by a speaker change detection (SCD) module. Building on these segments, we introduce several enhancements to efficiently select the best available segment for each speaker. These improvements lead to significant gains across various benchmarks. Notably, on real-world meeting data involving more than ten participants, SCDiar outperforms previous systems by up to 53.6\% in accuracy, substantially narrowing the performance gap between online and offline systems.
An efficient text augmentation approach for contextualized Mandarin speech recognition
Jun 14, 2024



Although contextualized automatic speech recognition (ASR) systems are commonly used to improve the recognition of uncommon words, their effectiveness is hindered by the inherent limitations of speech-text data availability. To address this challenge, our study proposes to leverage extensive text-only datasets and contextualize pre-trained ASR models using a straightforward text-augmentation (TA) technique, all while keeping computational costs minimal. In particular, to contextualize a pre-trained CIF-based ASR, we construct a codebook using limited speech-text data. By utilizing a simple codebook lookup process, we convert available text-only data into latent text embeddings. These embeddings then enhance the inputs for the contextualized ASR. Our experiments on diverse Mandarin test sets demonstrate that our TA approach significantly boosts recognition performance. The top-performing system shows relative CER improvements of up to 30% on rare words and 15% across all words in general.