 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCDiar: a streaming diarization system based on speaker change detection and speech recognition
Paper and Code



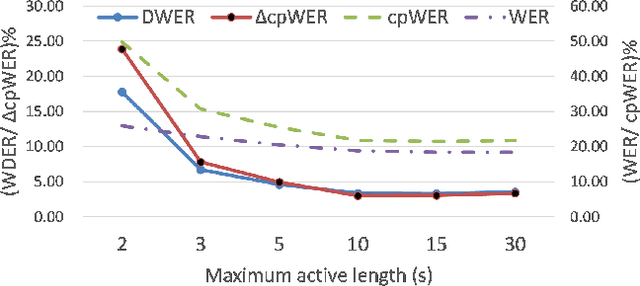
In hours-long meeting scenarios, real-time speech stream often struggles with achieving accurate speaker diarization, commonly leading to speaker identification and speaker count errors. To address this challenge, we propose SCDiar, a system that operates on speech segments, split at the token level by a speaker change detection (SCD) module. Building on these segments, we introduce several enhancements to efficiently select the best available segment for each speaker. These improvements lead to significant gains across various benchmarks. Notably, on real-world meeting data involving more than ten participants, SCDiar outperforms previous systems by up to 53.6\% in accuracy, substantially narrowing the performance gap between online and offline systems.