 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoc-CoB: Enhancing Multi-Modal Document Understanding with Visual Chain-of-Boxes Reasoning
May 24, 2025



Multimodal large language models (MLLMs) have made significant progress in document understanding. However, the information-dense nature of document images still poses challenges, as most queries depend on only a few relevant regions, with the rest being redundant. Existing one-pass MLLMs process entire document images without considering query relevance, often failing to focus on critical regions and producing unfaithful responses. Inspired by the human coarse-to-fine reading pattern, we introduce Doc-CoB (Chain-of-Box), a simple-yet-effective mechanism that integrates human-style visual reasoning into MLLM without modifying its architecture. Our method allows the model to autonomously select the set of regions (boxes) most relevant to the query, and then focus attention on them for further understanding. We first design a fully automatic pipeline, integrating a commercial MLLM with a layout analyzer, to generate 249k training samples with intermediate visual reasoning supervision. Then we incorporate two enabling tasks that improve box identification and box-query reasoning, which together enhance document understanding. Extensive experiments on seven benchmarks with four popular models show that Doc-CoB significantly improves performance, demonstrating its effectiveness and wide applicability. All code, data, and models will be released publicly.
Is Cognition consistent with Perception? Assessing and Mitigating Multimodal Knowledge Conflicts in Document Understanding
Nov 12, 2024



Multimodal large language models (MLLMs) have shown impressive capabilities in document understanding, a rapidly growing research area with significant industrial demand in recent years. As a multimodal task, document understanding requires models to possess both perceptual and cognitive abilities. However, current MLLMs often face conflicts between perception and cognition. Taking a document VQA task (cognition) as an example, an MLLM might generate answers that do not match the corresponding visual content identified by its OCR (perception). This conflict suggests that the MLLM might struggle to establish an intrinsic connection between the information it "sees" and what it "understands." Such conflicts challenge the intuitive notion that cognition is consistent with perception, hindering the performance and explainability of MLLMs. In this paper, we define the conflicts between cognition and perception as Cognition and Perception (C&P) knowledge conflicts, a form of multimodal knowledge conflicts, and systematically assess them with a focus on document understanding. Our analysis reveals that even GPT-4o, a leading MLLM, achieves only 68.6% C&P consistency. To mitigate the C&P knowledge conflicts, we propose a novel method called Multimodal Knowledge Consistency Fine-tuning. This method first ensures task-specific consistency and then connects the cognitive and perceptual knowledge. Our method significantly reduces C&P knowledge conflicts across all tested MLLMs and enhances their performance in both cognitive and perceptual tasks in most scenarios.
WebRPG: Automatic Web Rendering Parameters Generation for Visual Presentation
Jul 22, 2024
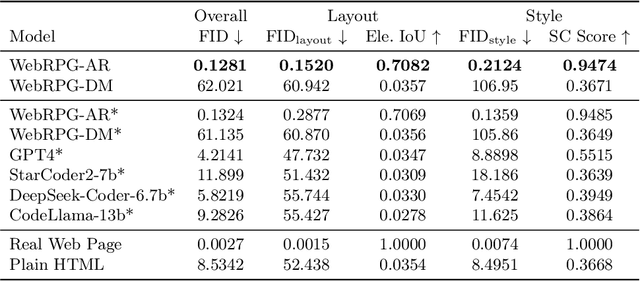


In the era of content creation revolution propelled by advancements in generative models, the field of web design remains unexplored despite its critical role in modern digital communication. The web design process is complex and often time-consuming, especially for those with limited expertise. In this paper, we introduce Web Rendering Parameters Generation (WebRPG), a new task that aims at automating the generation for visual presentation of web pages based on their HTML code. WebRPG would contribute to a faster web development workflow. Since there is no existing benchmark available, we develop a new dataset for WebRPG through an automated pipeline. Moreover, we present baseline models, utilizing VAE to manage numerous elements and rendering parameters, along with custom HTML embedding for capturing essential semantic and hierarchical information from HTML. Extensive experiments, including customized quantitative evaluations for this specific task, are conducted to evaluate the quality of the generated results.
LORE++: Logical Location Regression Network for Table Structure Recognition with Pre-training
Jan 03, 2024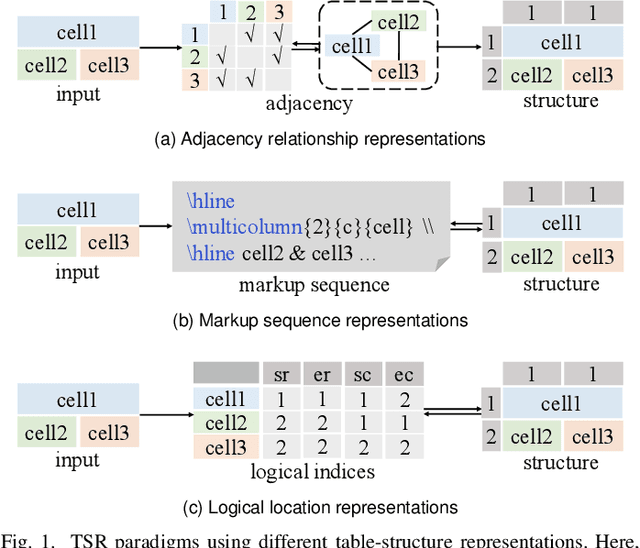

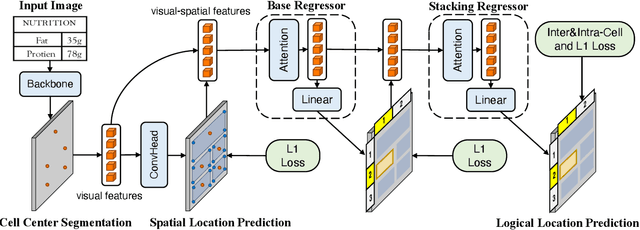
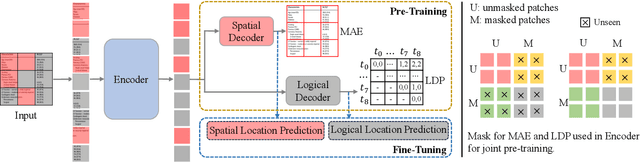
Table structure recognition (TSR) aims at extracting tables in images into machine-understandable formats. Recent methods solve this problem by predicting the adjacency relations of detected cell boxes or learning to directly generate the corresponding markup sequences from the table images. However, existing approaches either count on additional heuristic rules to recover the table structures, or face challenges in capturing long-range dependencies within tables, resulting in increased complexity. In this paper, we propose an alternative paradigm. We model TSR as a logical location regression problem and propose a new TSR framework called LORE, standing for LOgical location REgression network, which for the first time regresses logical location as well as spatial location of table cells in a unified network. Our proposed LORE is conceptually simpler, easier to train, and more accurate than other paradigms of TSR. Moreover, inspired by the persuasive success of pre-trained models on a number of computer vision and natural language processing tasks, we propose two pre-training tasks to enrich the spatial and logical representations at the feature level of LORE, resulting in an upgraded version called LORE++. The incorporation of pre-training in LORE++ has proven to enjoy significant advantages, leading to a substantial enhancement in terms of accuracy, generalization, and few-shot capability compared to its predecessor. Experiments on standard benchmarks against methods of previous paradigms demonstrate the superiority of LORE++, which highlights the potential and promising prospect of the logical location regression paradigm for TSR.
LORE: Logical Location Regression Network for Table Structure Recognition
Mar 07, 2023



Table structure recognition (TSR) aims at extracting tables in images into machine-understandable formats. Recent methods solve this problem by predicting the adjacency relations of detected cell boxes, or learning to generate the corresponding markup sequences from the table images. However, they either count on additional heuristic rules to recover the table structures, or require a huge amount of training data and time-consuming sequential decoders. In this paper, we propose an alternative paradigm. We model TSR as a logical location regression problem and propose a new TSR framework called LORE, standing for LOgical location REgression network, which for the first time combines logical location regression together with spatial location regression of table cells. Our proposed LORE is conceptually simpler, easier to train and more accurate than previous TSR models of other paradigms. Experiments on standard benchmarks demonstrate that LORE consistently outperforms prior arts. Code is available at https:// github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/LORE-TSR.