 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal-LLaVA: Causal Disentanglement for Mitigating Hallucination in Multimodal Large Language Models
May 26, 2025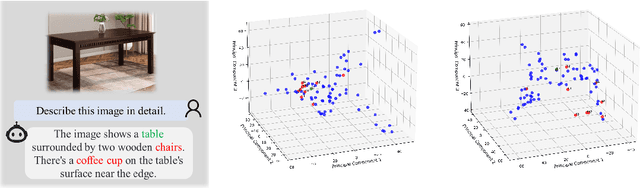
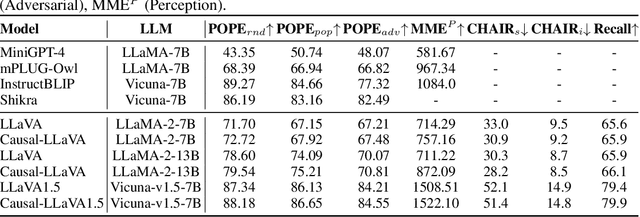
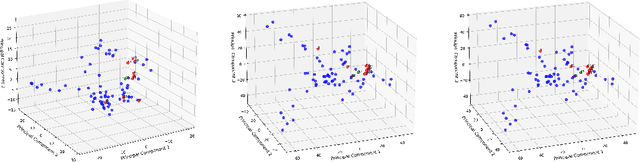
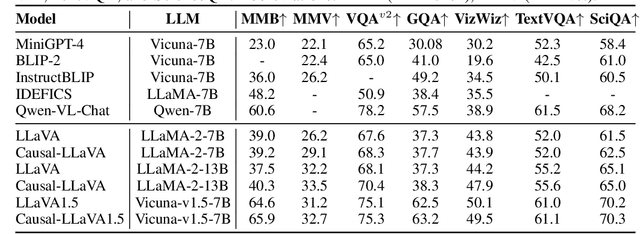
Multimodal Large Language Models (MLLMs) have demonstrated strong performance in visual understanding tasks, yet they often suffer from object hallucinations--generating descriptions of objects that are inconsistent with or entirely absent from the input. This issue is closely related to dataset biases, where frequent co-occurrences of objects lead to entangled semantic representations across modalities. As a result, models may erroneously activate object representations that are commonly associated with the input but not actually present. To address this, we propose a causality-driven disentanglement framework that mitigates hallucinations through causal intervention. Our approach includes a Causal-Driven Projector in the visual pathway and a Causal Intervention Module integrated into the final transformer layer of the language model. These components work together to reduce spurious correlations caused by biased training data. Experimental results show that our method significantly reduces hallucinations while maintaining strong performance on multiple multimodal benchmarks. Visualization analyses further confirm improved separability of object representations. The code is available at: https://github.com/IgniSavium/Causal-LLaVA
FocusedAD: Character-centric Movie Audio Description
Apr 16, 2025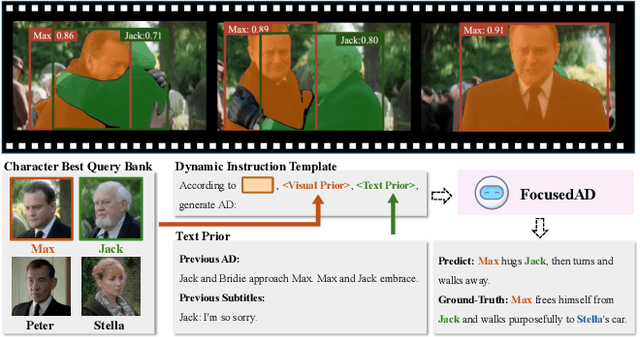
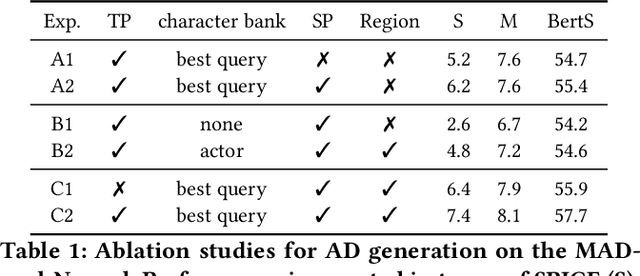
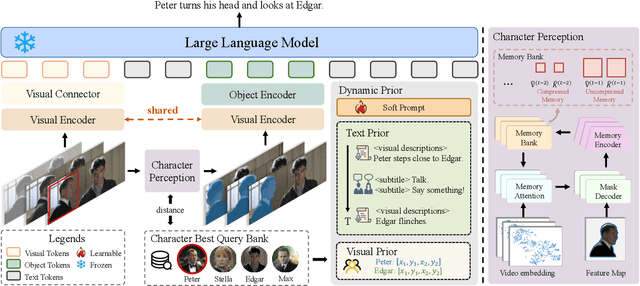
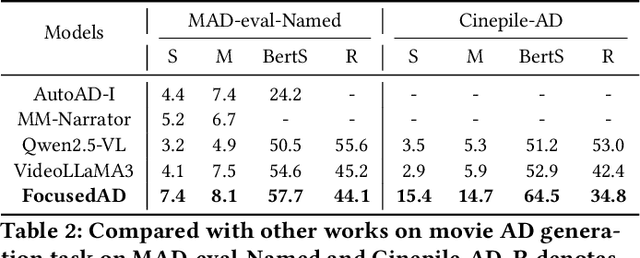
Movie Audio Description (AD) aims to narrate visual content during dialogue-free segments, particularly benefiting blind and visually impaired (BVI) audiences. Compared with general video captioning, AD demands plot-relevant narration with explicit character name references, posing unique challenges in movie understanding.To identify active main characters and focus on storyline-relevant regions, we propose FocusedAD, a novel framework that delivers character-centric movie audio descriptions. It includes: (i) a Character Perception Module(CPM) for tracking character regions and linking them to names; (ii) a Dynamic Prior Module(DPM) that injects contextual cues from prior ADs and subtitles via learnable soft prompts; and (iii) a Focused Caption Module(FCM) that generates narrations enriched with plot-relevant details and named characters. To overcome limitations in character identification, we also introduce an automated pipeline for building character query banks. FocusedAD achieves state-of-the-art performance on multiple benchmarks, including strong zero-shot results on MAD-eval-Named and our newly proposed Cinepile-AD dataset. Code and data will be released at https://github.com/Thorin215/FocusedAD .
MP-GUI: Modality Perception with MLLMs for GUI Understanding
Mar 18, 2025Graphical user interface (GUI) has become integral to modern society, making it crucial to be understood for human-centric systems. However, unlike natural images or documents, GUIs comprise artificially designed graphical elements arranged to convey specific semantic meanings. Current multi-modal large language models (MLLMs) already proficient in processing graphical and textual components suffer from hurdles in GUI understanding due to the lack of explicit spatial structure modeling. Moreover, obtaining high-quality spatial structure data is challenging due to privacy issues and noisy environments. To address these challenges, we present MP-GUI, a specially designed MLLM for GUI understanding. MP-GUI features three precisely specialized perceivers to extract graphical, textual, and spatial modalities from the screen as GUI-tailored visual clues, with spatial structure refinement strategy and adaptively combined via a fusion gate to meet the specific preferences of different GUI understanding tasks. To cope with the scarcity of training data, we also introduce a pipeline for automatically data collecting. Extensive experiments demonstrate that MP-GUI achieves impressive results on various GUI understanding tasks with limited data.
Universal Inceptive GNNs by Eliminating the Smoothness-generalization Dilemma
Dec 13, 2024Graph Neural Networks (GNNs) have demonstrated remarkable success in various domains, such as transaction and social net-works. However, their application is often hindered by the varyinghomophily levels across different orders of neighboring nodes, ne-cessitating separate model designs for homophilic and heterophilicgraphs. In this paper, we aim to develop a unified framework ca-pable of handling neighborhoods of various orders and homophilylevels. Through theoretical exploration, we identify a previouslyoverlooked architectural aspect in multi-hop learning: the cascadedependency, which leads to asmoothness-generalization dilemma.This dilemma significantly affects the learning process, especiallyin the context of high-order neighborhoods and heterophilic graphs.To resolve this issue, we propose an Inceptive Graph Neural Net-work (IGNN), a universal message-passing framework that replacesthe cascade dependency with an inceptive architecture. IGNN pro-vides independent representations for each hop, allowing personal-ized generalization capabilities, and captures neighborhood-wiserelationships to select appropriate receptive fields. Extensive ex-periments show that our IGNN outperforms 23 baseline methods,demonstrating superior performance on both homophilic and het-erophilic graphs, while also scaling efficiently to large graphs.
FGP: Feature-Gradient-Prune for Efficient Convolutional Layer Pruning
Nov 19, 2024



To reduce computational overhead while maintaining model performance, model pruning techniques have been proposed. Among these, structured pruning, which removes entire convolutional channels or layers, significantly enhances computational efficiency and is compatible with hardware acceleration. However, existing pruning methods that rely solely on image features or gradients often result in the retention of redundant channels, negatively impacting inference efficiency. To address this issue, this paper introduces a novel pruning method called Feature-Gradient Pruning (FGP). This approach integrates both feature-based and gradient-based information to more effectively evaluate the importance of channels across various target classes, enabling a more accurate identification of channels that are critical to model performance. Experimental results demonstrate that the proposed method improves both model compactness and practicality while maintaining stable performance. Experiments conducted across multiple tasks and datasets show that FGP significantly reduces computational costs and minimizes accuracy loss compared to existing methods, highlighting its effectiveness in optimizing pruning outcomes. The source code is available at: https://github.com/FGP-code/FGP.
LORE: Logical Location Regression Network for Table Structure Recognition
Mar 07, 2023



Table structure recognition (TSR) aims at extracting tables in images into machine-understandable formats. Recent methods solve this problem by predicting the adjacency relations of detected cell boxes, or learning to generate the corresponding markup sequences from the table images. However, they either count on additional heuristic rules to recover the table structures, or require a huge amount of training data and time-consuming sequential decoders. In this paper, we propose an alternative paradigm. We model TSR as a logical location regression problem and propose a new TSR framework called LORE, standing for LOgical location REgression network, which for the first time combines logical location regression together with spatial location regression of table cells. Our proposed LORE is conceptually simpler, easier to train and more accurate than previous TSR models of other paradigms. Experiments on standard benchmarks demonstrate that LORE consistently outperforms prior arts. Code is available at https:// github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/LORE-TSR.
How to Teach: Learning Data-Free Knowledge Distillation from Curriculum
Aug 29, 2022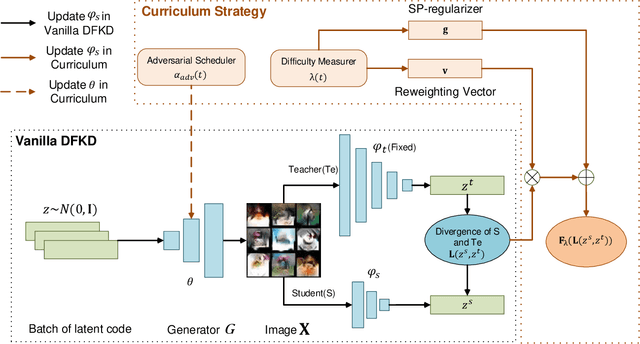



Data-free knowledge distillation (DFKD) aims at training lightweight student networks from teacher networks without training data. Existing approaches mainly follow the paradigm of generating informative samples and progressively updating student models by targeting data priors, boundary samples or memory samples. However, it is difficult for the previous DFKD methods to dynamically adjust the generation strategy at different training stages, which in turn makes it difficult to achieve efficient and stable training. In this paper, we explore how to teach students the model from a curriculum learning (CL) perspective and propose a new approach, namely "CuDFKD", i.e., "Data-Free Knowledge Distillation with Curriculum". It gradually learns from easy samples to difficult samples, which is similar to the way humans learn. In addition, we provide a theoretical analysis of the majorization minimization (MM) algorithm and explain the convergence of CuDFKD. Experiments conducted on benchmark datasets show that with a simple course design strategy, CuDFKD achieves the best performance over state-of-the-art DFKD methods and different benchmarks, such as 95.28\% top1 accuracy of the ResNet18 model on CIFAR10, which is better than training from scratch with data. The training is fast, reaching the highest accuracy of 90\% within 30 epochs, and the variance during training is stable. Also in this paper, the applicability of CuDFKD is also analyzed and discussed.