 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Teach: Learning Data-Free Knowledge Distillation from Curriculum
Paper and Code
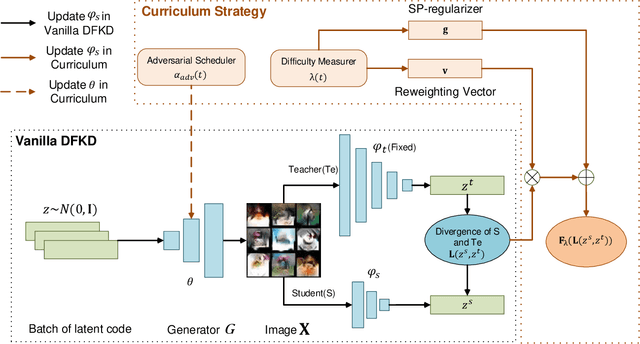



Data-free knowledge distillation (DFKD) aims at training lightweight student networks from teacher networks without training data. Existing approaches mainly follow the paradigm of generating informative samples and progressively updating student models by targeting data priors, boundary samples or memory samples. However, it is difficult for the previous DFKD methods to dynamically adjust the generation strategy at different training stages, which in turn makes it difficult to achieve efficient and stable training. In this paper, we explore how to teach students the model from a curriculum learning (CL) perspective and propose a new approach, namely "CuDFKD", i.e., "Data-Free Knowledge Distillation with Curriculum". It gradually learns from easy samples to difficult samples, which is similar to the way humans learn. In addition, we provide a theoretical analysis of the majorization minimization (MM) algorithm and explain the convergence of CuDFKD. Experiments conducted on benchmark datasets show that with a simple course design strategy, CuDFKD achieves the best performance over state-of-the-art DFKD methods and different benchmarks, such as 95.28\% top1 accuracy of the ResNet18 model on CIFAR10, which is better than training from scratch with data. The training is fast, reaching the highest accuracy of 90\% within 30 epochs, and the variance during training is stable. Also in this paper, the applicability of CuDFKD is also analyzed and discussed.