 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance-Adaptive Muon: Accelerating LLM Pretraining with NSR-Modulated and Variance-Scaled Momentum
Jan 21, 2026Large Language Models (LLMs) achieve competitive performance across diverse natural language processing (NLP) tasks, yet pretraining is computationally demanding, making optimizer efficiency an important practical consideration. Muon accelerates LLM pretraining via orthogonal momentum updates that serve as a matrix analogue of the element-wise sign operator. Motivated by the recent perspective that Adam is a variance-adaptive sign update algorithm, we propose two variants of Muon, Muon-NSR and Muon-VS, which apply variance-adaptive normalization to momentum before orthogonalization. Muon-NSR applies noise-to-signal ratio (NSR) modulation, while Muon-VS performs variance-based scaling without introducing additional hyperparameters. Experiments on GPT-2 and LLaMA pretraining demonstrate that our proposed methods accelerate convergence and consistently achieve lower validation loss than both competitive, well-tuned AdamW and Muon baselines. For example, on the LLaMA-1.2B model, Muon-NSR and Muon-VS reduce the iterations required to reach the target validation loss by $1.36\times$ relative to the well-tuned Muon following the recent benchmark.
RainFusion: Adaptive Video Generation Acceleration via Multi-Dimensional Visual Redundancy
May 27, 2025Video generation using diffusion models is highly computationally intensive, with 3D attention in Diffusion Transformer (DiT) models accounting for over 80\% of the total computational resources. In this work, we introduce {\bf RainFusion}, a novel training-free sparse attention method that exploits inherent sparsity nature in visual data to accelerate attention computation while preserving video quality. Specifically, we identify three unique sparse patterns in video generation attention calculations--Spatial Pattern, Temporal Pattern and Textural Pattern. The sparse pattern for each attention head is determined online with negligible overhead (\textasciitilde\,0.2\%) with our proposed {\bf ARM} (Adaptive Recognition Module) during inference. Our proposed {\bf RainFusion} is a plug-and-play method, that can be seamlessly integrated into state-of-the-art 3D-attention video generation models without additional training or calibration. We evaluate our method on leading open-sourced models including HunyuanVideo, OpenSoraPlan-1.2 and CogVideoX-5B, demonstrating its broad applicability and effectiveness. Experimental results show that RainFusion achieves over {\bf 2\(\times\)} speedup in attention computation while maintaining video quality, with only a minimal impact on VBench scores (-0.2\%).
AFD-STA: Adaptive Filtering Denoising with Spatiotemporal Attention for Chaotic System Prediction
May 23, 2025This paper presents AFD-STA Net, a neural framework integrating adaptive filtering and spatiotemporal dynamics learning for predicting high-dimensional chaotic systems governed by partial differential equations. The architecture combines: 1) An adaptive exponential smoothing module with position-aware decay coefficients for robust attractor reconstruction, 2) Parallel attention mechanisms capturing cross-temporal and spatial dependencies, 3) Dynamic gated fusion of multiscale features, and 4) Deep projection networks with dimension-scaling capabilities. Numerical experiments on nonlinear PDE systems demonstrate the model's effectiveness in maintaining prediction accuracy under both smooth and strongly chaotic regimes while exhibiting noise tolerance through adaptive filtering. Component ablation studies confirm critical contributions from each module, particularly highlighting the essential role of spatiotemporal attention in learning complex dynamical interactions. The framework shows promising potential for real-world applications requiring simultaneous handling of measurement uncertainties and high-dimensional nonlinear dynamics.
How to Teach: Learning Data-Free Knowledge Distillation from Curriculum
Aug 29, 2022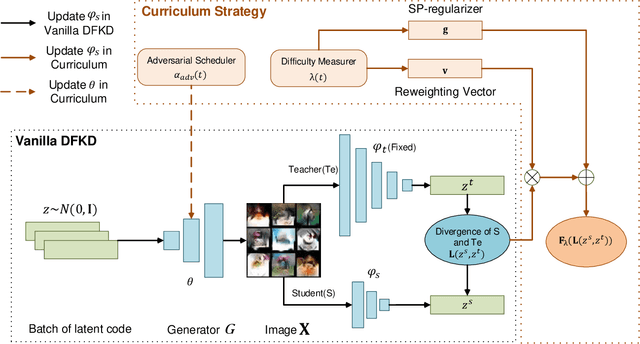



Data-free knowledge distillation (DFKD) aims at training lightweight student networks from teacher networks without training data. Existing approaches mainly follow the paradigm of generating informative samples and progressively updating student models by targeting data priors, boundary samples or memory samples. However, it is difficult for the previous DFKD methods to dynamically adjust the generation strategy at different training stages, which in turn makes it difficult to achieve efficient and stable training. In this paper, we explore how to teach students the model from a curriculum learning (CL) perspective and propose a new approach, namely "CuDFKD", i.e., "Data-Free Knowledge Distillation with Curriculum". It gradually learns from easy samples to difficult samples, which is similar to the way humans learn. In addition, we provide a theoretical analysis of the majorization minimization (MM) algorithm and explain the convergence of CuDFKD. Experiments conducted on benchmark datasets show that with a simple course design strategy, CuDFKD achieves the best performance over state-of-the-art DFKD methods and different benchmarks, such as 95.28\% top1 accuracy of the ResNet18 model on CIFAR10, which is better than training from scratch with data. The training is fast, reaching the highest accuracy of 90\% within 30 epochs, and the variance during training is stable. Also in this paper, the applicability of CuDFKD is also analyzed and discussed.