 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyGDA: A Python Library for Graph Domain Adaptation
Mar 13, 2025
Graph domain adaptation has emerged as a promising approach to facilitate knowledge transfer across different domains. Recently, numerous models have been proposed to enhance their generalization capabilities in this field. However, there is still no unified library that brings together existing techniques and simplifies their implementation. To fill this gap, we introduce PyGDA, an open-source Python library tailored for graph domain adaptation. As the first comprehensive library in this area, PyGDA covers more than 20 widely used graph domain adaptation methods together with different types of graph datasets. Specifically, PyGDA offers modular components, enabling users to seamlessly build custom models with a variety of commonly used utility functions. To handle large-scale graphs, PyGDA includes support for features such as sampling and mini-batch processing, ensuring efficient computation. In addition, PyGDA also includes comprehensive performance benchmarks and well-documented user-friendly API for both researchers and practitioners. To foster convenient accessibility, PyGDA is released under the MIT license at https://github.com/pygda-team/pygda, and the API documentation is https://pygda.readthedocs.io/en/stable/.
Universal Inceptive GNNs by Eliminating the Smoothness-generalization Dilemma
Dec 13, 2024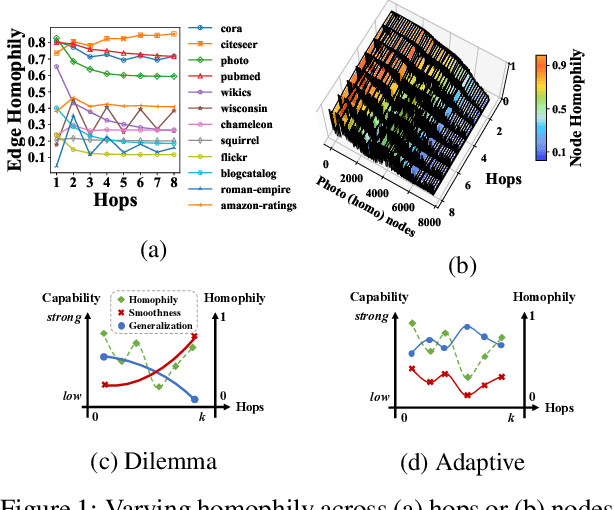

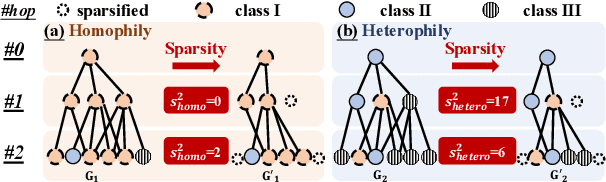

Graph Neural Networks (GNNs) have demonstrated remarkable success in various domains, such as transaction and social net-works. However, their application is often hindered by the varyinghomophily levels across different orders of neighboring nodes, ne-cessitating separate model designs for homophilic and heterophilicgraphs. In this paper, we aim to develop a unified framework ca-pable of handling neighborhoods of various orders and homophilylevels. Through theoretical exploration, we identify a previouslyoverlooked architectural aspect in multi-hop learning: the cascadedependency, which leads to asmoothness-generalization dilemma.This dilemma significantly affects the learning process, especiallyin the context of high-order neighborhoods and heterophilic graphs.To resolve this issue, we propose an Inceptive Graph Neural Net-work (IGNN), a universal message-passing framework that replacesthe cascade dependency with an inceptive architecture. IGNN pro-vides independent representations for each hop, allowing personal-ized generalization capabilities, and captures neighborhood-wiserelationships to select appropriate receptive fields. Extensive ex-periments show that our IGNN outperforms 23 baseline methods,demonstrating superior performance on both homophilic and het-erophilic graphs, while also scaling efficiently to large graphs.
Collaborate to Adapt: Source-Free Graph Domain Adaptation via Bi-directional Adaptation
Mar 03, 2024Unsupervised Graph Domain Adaptation (UGDA) has emerged as a practical solution to transfer knowledge from a label-rich source graph to a completely unlabelled target graph. However, most methods require a labelled source graph to provide supervision signals, which might not be accessible in the real-world settings due to regulations and privacy concerns. In this paper, we explore the scenario of source-free unsupervised graph domain adaptation, which tries to address the domain adaptation problem without accessing the labelled source graph. Specifically, we present a novel paradigm called GraphCTA, which performs model adaptation and graph adaptation collaboratively through a series of procedures: (1) conduct model adaptation based on node's neighborhood predictions in target graph considering both local and global information; (2) perform graph adaptation by updating graph structure and node attributes via neighborhood contrastive learning; and (3) the updated graph serves as an input to facilitate the subsequent iteration of model adaptation, thereby establishing a collaborative loop between model adaptation and graph adaptation. Comprehensive experiments are conducted on various public datasets. The experimental results demonstrate that our proposed model outperforms recent source-free baselines by large margins.
Rethinking Propagation for Unsupervised Graph Domain Adaptation
Feb 08, 2024



Unsupervised Graph Domain Adaptation (UGDA) aims to transfer knowledge from a labelled source graph to an unlabelled target graph in order to address the distribution shifts between graph domains. Previous works have primarily focused on aligning data from the source and target graph in the representation space learned by graph neural networks (GNNs). However, the inherent generalization capability of GNNs has been largely overlooked. Motivated by our empirical analysis, we reevaluate the role of GNNs in graph domain adaptation and uncover the pivotal role of the propagation process in GNNs for adapting to different graph domains. We provide a comprehensive theoretical analysis of UGDA and derive a generalization bound for multi-layer GNNs. By formulating GNN Lipschitz for k-layer GNNs, we show that the target risk bound can be tighter by removing propagation layers in source graph and stacking multiple propagation layers in target graph. Based on the empirical and theoretical analysis mentioned above, we propose a simple yet effective approach called A2GNN for graph domain adaptation. Through extensive experiments on real-world datasets, we demonstrate the effectiveness of our proposed A2GNN framework.
Homophily-enhanced Structure Learning for Graph Clustering
Aug 11, 2023Graph clustering is a fundamental task in graph analysis, and recent advances in utilizing graph neural networks (GNNs) have shown impressive results. Despite the success of existing GNN-based graph clustering methods, they often overlook the quality of graph structure, which is inherent in real-world graphs due to their sparse and multifarious nature, leading to subpar performance. Graph structure learning allows refining the input graph by adding missing links and removing spurious connections. However, previous endeavors in graph structure learning have predominantly centered around supervised settings, and cannot be directly applied to our specific clustering tasks due to the absence of ground-truth labels. To bridge the gap, we propose a novel method called \textbf{ho}mophily-enhanced structure \textbf{le}arning for graph clustering (HoLe). Our motivation stems from the observation that subtly enhancing the degree of homophily within the graph structure can significantly improve GNNs and clustering outcomes. To realize this objective, we develop two clustering-oriented structure learning modules, i.e., hierarchical correlation estimation and cluster-aware sparsification. The former module enables a more accurate estimation of pairwise node relationships by leveraging guidance from latent and clustering spaces, while the latter one generates a sparsified structure based on the similarity matrix and clustering assignments. Additionally, we devise a joint optimization approach alternating between training the homophily-enhanced structure learning and GNN-based clustering, thereby enforcing their reciprocal effects. Extensive experiments on seven benchmark datasets of various types and scales, across a range of clustering metrics, demonstrate the superiority of HoLe against state-of-the-art baselines.