 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile-Agent-v3.5: Multi-platform Fundamental GUI Agents
Feb 15, 2026The paper introduces GUI-Owl-1.5, the latest native GUI agent model that features instruct/thinking variants in multiple sizes (2B/4B/8B/32B/235B) and supports a range of platforms (desktop, mobile, browser, and more) to enable cloud-edge collaboration and real-time interaction. GUI-Owl-1.5 achieves state-of-the-art results on more than 20+ GUI benchmarks on open-source models: (1) on GUI automation tasks, it obtains 56.5 on OSWorld, 71.6 on AndroidWorld, and 48.4 on WebArena; (2) on grounding tasks, it obtains 80.3 on ScreenSpotPro; (3) on tool-calling tasks, it obtains 47.6 on OSWorld-MCP, and 46.8 on MobileWorld; (4) on memory and knowledge tasks, it obtains 75.5 on GUI-Knowledge Bench. GUI-Owl-1.5 incorporates several key innovations: (1) Hybird Data Flywheel: we construct the data pipeline for UI understanding and trajectory generation based on a combination of simulated environments and cloud-based sandbox environments, in order to improve the efficiency and quality of data collection. (2) Unified Enhancement of Agent Capabilities: we use a unified thought-synthesis pipeline to enhance the model's reasoning capabilities, while placing particular emphasis on improving key agent abilities, including Tool/MCP use, memory and multi-agent adaptation; (3) Multi-platform Environment RL Scaling: We propose a new environment RL algorithm, MRPO, to address the challenges of multi-platform conflicts and the low training efficiency of long-horizon tasks. The GUI-Owl-1.5 models are open-sourced, and an online cloud-sandbox demo is available at https://github.com/X-PLUG/MobileAgent.
Mobile-Agent-v3: Foundamental Agents for GUI Automation
Aug 21, 2025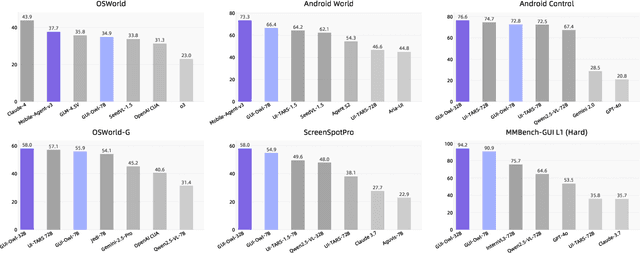
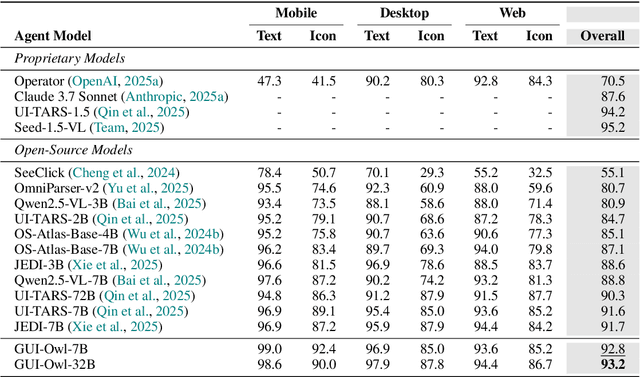
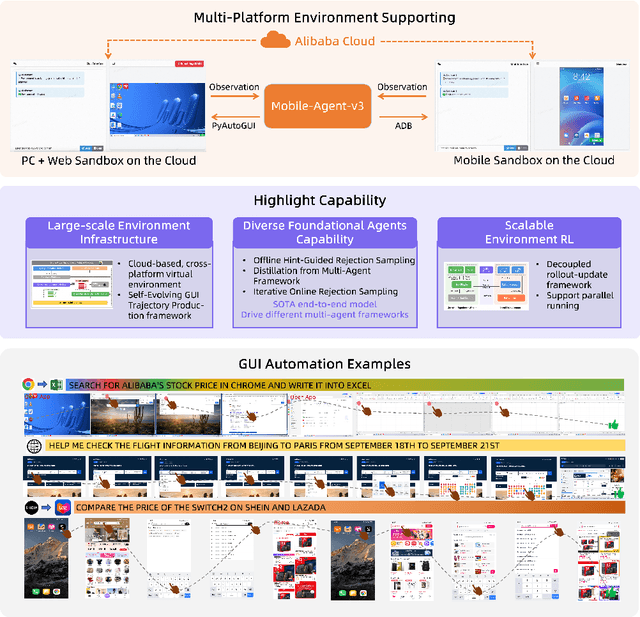
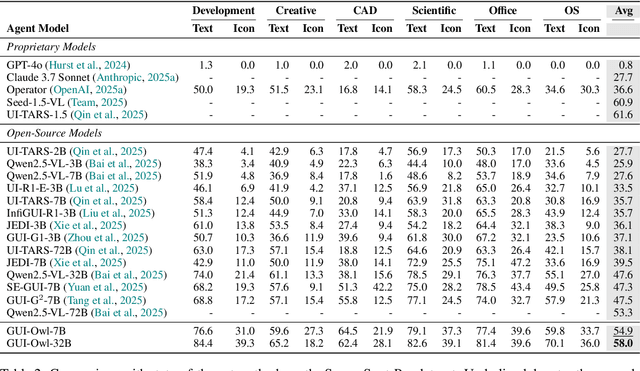
This paper introduces GUI-Owl, a foundational GUI agent model that achieves state-of-the-art performance among open-source end-to-end models on ten GUI benchmarks across desktop and mobile environments, covering grounding, question answering, planning, decision-making, and procedural knowledge. GUI-Owl-7B achieves 66.4 on AndroidWorld and 29.4 on OSWorld. Building on this, we propose Mobile-Agent-v3, a general-purpose GUI agent framework that further improves performance to 73.3 on AndroidWorld and 37.7 on OSWorld, setting a new state-of-the-art for open-source GUI agent frameworks. GUI-Owl incorporates three key innovations: (1) Large-scale Environment Infrastructure: a cloud-based virtual environment spanning Android, Ubuntu, macOS, and Windows, enabling our Self-Evolving GUI Trajectory Production framework. This generates high-quality interaction data via automated query generation and correctness validation, leveraging GUI-Owl to refine trajectories iteratively, forming a self-improving loop. It supports diverse data pipelines and reduces manual annotation. (2) Diverse Foundational Agent Capabilities: by integrating UI grounding, planning, action semantics, and reasoning patterns, GUI-Owl supports end-to-end decision-making and can act as a modular component in multi-agent systems. (3) Scalable Environment RL: we develop a scalable reinforcement learning framework with fully asynchronous training for real-world alignment. We also introduce Trajectory-aware Relative Policy Optimization (TRPO) for online RL, achieving 34.9 on OSWorld. GUI-Owl and Mobile-Agent-v3 are open-sourced at https://github.com/X-PLUG/MobileAgent.
SceneVTG++: Controllable Multilingual Visual Text Generation in the Wild
Jan 07, 2025



Generating visual text in natural scene images is a challenging task with many unsolved problems. Different from generating text on artificially designed images (such as posters, covers, cartoons, etc.), the text in natural scene images needs to meet the following four key criteria: (1) Fidelity: the generated text should appear as realistic as a photograph and be completely accurate, with no errors in any of the strokes. (2) Reasonability: the text should be generated on reasonable carrier areas (such as boards, signs, walls, etc.), and the generated text content should also be relevant to the scene. (3) Utility: the generated text can facilitate to the training of natural scene OCR (Optical Character Recognition) tasks. (4) Controllability: The attribute of the text (such as font and color) should be controllable as needed. In this paper, we propose a two stage method, SceneVTG++, which simultaneously satisfies the four aspects mentioned above. SceneVTG++ consists of a Text Layout and Content Generator (TLCG) and a Controllable Local Text Diffusion (CLTD). The former utilizes the world knowledge of multi modal large language models to find reasonable text areas and recommend text content according to the nature scene background images, while the latter generates controllable multilingual text based on the diffusion model. Through extensive experiments, we respectively verified the effectiveness of TLCG and CLTD, and demonstrated the state-of-the-art text generation performance of SceneVTG++. In addition, the generated images have superior utility in OCR tasks like text detection and text recognition. Codes and datasets will be available.
WebRPG: Automatic Web Rendering Parameters Generation for Visual Presentation
Jul 22, 2024
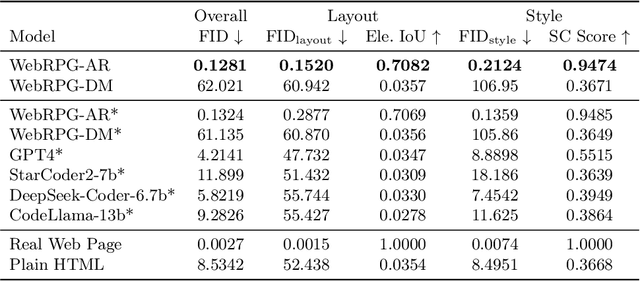


In the era of content creation revolution propelled by advancements in generative models, the field of web design remains unexplored despite its critical role in modern digital communication. The web design process is complex and often time-consuming, especially for those with limited expertise. In this paper, we introduce Web Rendering Parameters Generation (WebRPG), a new task that aims at automating the generation for visual presentation of web pages based on their HTML code. WebRPG would contribute to a faster web development workflow. Since there is no existing benchmark available, we develop a new dataset for WebRPG through an automated pipeline. Moreover, we present baseline models, utilizing VAE to manage numerous elements and rendering parameters, along with custom HTML embedding for capturing essential semantic and hierarchical information from HTML. Extensive experiments, including customized quantitative evaluations for this specific task, are conducted to evaluate the quality of the generated results.
Visual Text Generation in the Wild
Jul 19, 2024



Recently, with the rapid advancements of generative models, the field of visual text generation has witnessed significant progress. However, it is still challenging to render high-quality text images in real-world scenarios, as three critical criteria should be satisfied: (1) Fidelity: the generated text images should be photo-realistic and the contents are expected to be the same as specified in the given conditions; (2) Reasonability: the regions and contents of the generated text should cohere with the scene; (3) Utility: the generated text images can facilitate related tasks (e.g., text detection and recognition). Upon investigation, we find that existing methods, either rendering-based or diffusion-based, can hardly meet all these aspects simultaneously, limiting their application range. Therefore, we propose in this paper a visual text generator (termed SceneVTG), which can produce high-quality text images in the wild. Following a two-stage paradigm, SceneVTG leverages a Multimodal Large Language Model to recommend reasonable text regions and contents across multiple scales and levels, which are used by a conditional diffusion model as conditions to generate text images. Extensive experiments demonstrate that the proposed SceneVTG significantly outperforms traditional rendering-based methods and recent diffusion-based methods in terms of fidelity and reasonability. Besides, the generated images provide superior utility for tasks involving text detection and text recognition. Code and datasets are available at AdvancedLiterateMachinery.
LORE: Logical Location Regression Network for Table Structure Recognition
Mar 07, 2023



Table structure recognition (TSR) aims at extracting tables in images into machine-understandable formats. Recent methods solve this problem by predicting the adjacency relations of detected cell boxes, or learning to generate the corresponding markup sequences from the table images. However, they either count on additional heuristic rules to recover the table structures, or require a huge amount of training data and time-consuming sequential decoders. In this paper, we propose an alternative paradigm. We model TSR as a logical location regression problem and propose a new TSR framework called LORE, standing for LOgical location REgression network, which for the first time combines logical location regression together with spatial location regression of table cells. Our proposed LORE is conceptually simpler, easier to train and more accurate than previous TSR models of other paradigms. Experiments on standard benchmarks demonstrate that LORE consistently outperforms prior arts. Code is available at https:// github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/LORE-TSR.
SentiPrompt: Sentiment Knowledge Enhanced Prompt-Tuning for Aspect-Based Sentiment Analysis
Sep 17, 2021

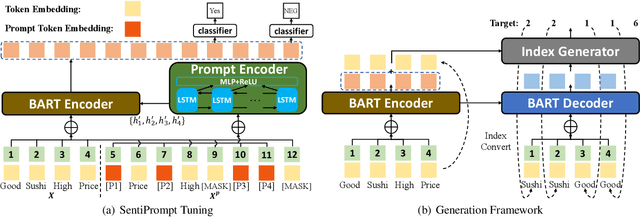
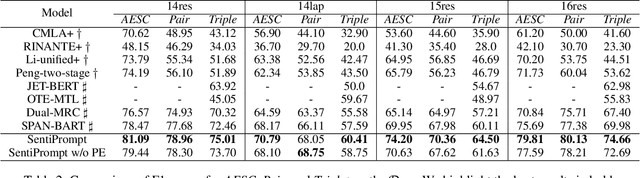
Aspect-based sentiment analysis (ABSA) is an emerging fine-grained sentiment analysis task that aims to extract aspects, classify corresponding sentiment polarities and find opinions as the causes of sentiment. The latest research tends to solve the ABSA task in a unified way with end-to-end frameworks. Yet, these frameworks get fine-tuned from downstream tasks without any task-adaptive modification. Specifically, they do not use task-related knowledge well or explicitly model relations between aspect and opinion terms, hindering them from better performance. In this paper, we propose SentiPrompt to use sentiment knowledge enhanced prompts to tune the language model in the unified framework. We inject sentiment knowledge regarding aspects, opinions, and polarities into prompt and explicitly model term relations via constructing consistency and polarity judgment templates from the ground truth triplets. Experimental results demonstrate that our approach can outperform strong baselines on Triplet Extraction, Pair Extraction, and Aspect Term Extraction with Sentiment Classification by a notable margin.
Parsing Table Structures in the Wild
Sep 06, 2021
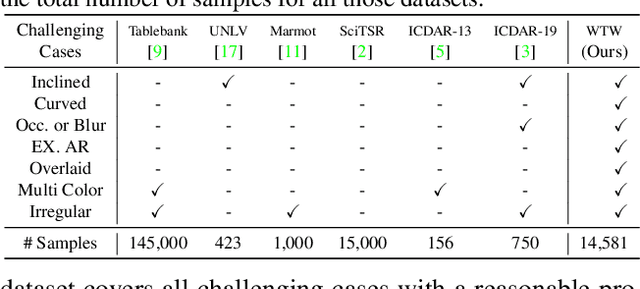
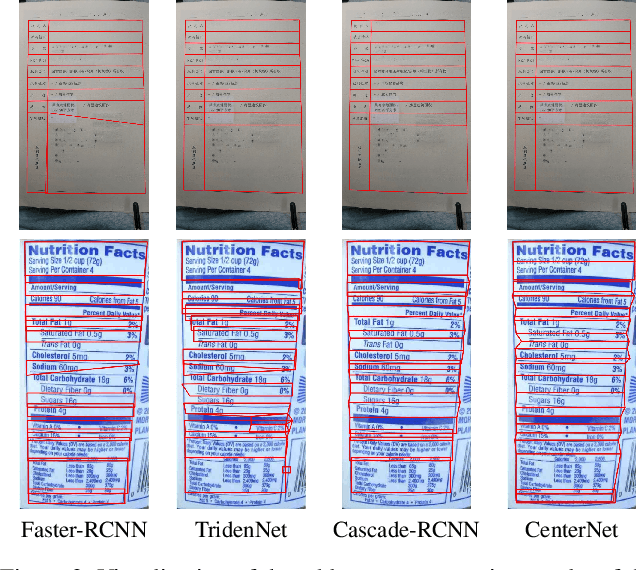
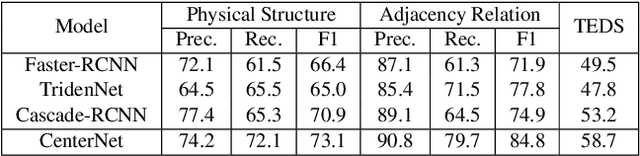
This paper tackles the problem of table structure parsing (TSP) from images in the wild. In contrast to existing studies that mainly focus on parsing well-aligned tabular images with simple layouts from scanned PDF documents, we aim to establish a practical table structure parsing system for real-world scenarios where tabular input images are taken or scanned with severe deformation, bending or occlusions. For designing such a system, we propose an approach named Cycle-CenterNet on the top of CenterNet with a novel cycle-pairing module to simultaneously detect and group tabular cells into structured tables. In the cycle-pairing module, a new pairing loss function is proposed for the network training. Alongside with our Cycle-CenterNet, we also present a large-scale dataset, named Wired Table in the Wild (WTW), which includes well-annotated structure parsing of multiple style tables in several scenes like the photo, scanning files, web pages, \emph{etc.}. In experiments, we demonstrate that our Cycle-CenterNet consistently achieves the best accuracy of table structure parsing on the new WTW dataset by 24.6\% absolute improvement evaluated by the TEDS metric. A more comprehensive experimental analysis also validates the advantages of our proposed methods for the TSP task.
Graph Convolution for Multimodal Information Extraction from Visually Rich Documents
Mar 27, 2019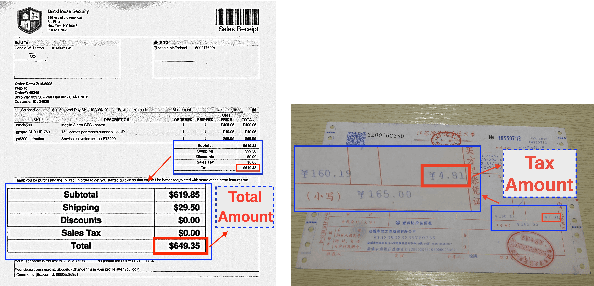
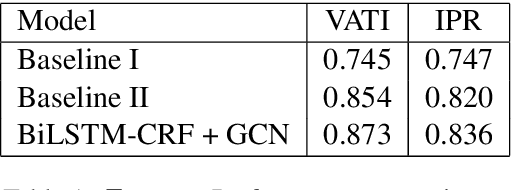
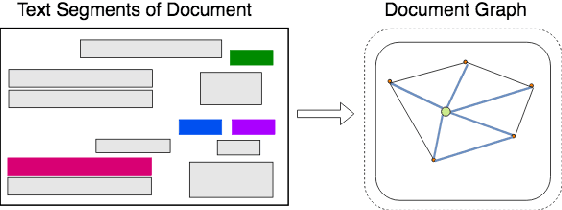
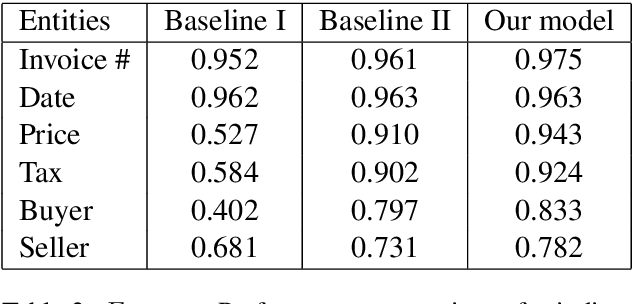
Visually rich documents (VRDs) are ubiquitous in daily business and life. Examples are purchase receipts, insurance policy documents, custom declaration forms and so on. In VRDs, visual and layout information is critical for document understanding, and texts in such documents cannot be serialized into the one-dimensional sequence without losing information. Classic information extraction models such as BiLSTM-CRF typically operate on text sequences and do not incorporate visual features. In this paper, we introduce a graph convolution based model to combine textual and visual information presented in VRDs. Graph embeddings are trained to summarize the context of a text segment in the document, and further combined with text embeddings for entity extraction. Extensive experiments have been conducted to show that our method outperforms BiLSTM-CRF baselines by significant margins, on two real-world datasets. Additionally, ablation studies are also performed to evaluate the effectiveness of each component of our model.