 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUI-Venus-1.5 Technical Report
Feb 09, 2026GUI agents have emerged as a powerful paradigm for automating interactions in digital environments, yet achieving both broad generality and consistently strong task performance remains challenging.In this report, we present UI-Venus-1.5, a unified, end-to-end GUI Agent designed for robust real-world applications.The proposed model family comprises two dense variants (2B and 8B) and one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios.Compared to our previous version, UI-Venus-1.5 introduces three key technical advances: (1) a comprehensive Mid-Training stage leveraging 10 billion tokens across 30+ datasets to establish foundational GUI semantics; (2) Online Reinforcement Learning with full-trajectory rollouts, aligning training objectives with long-horizon, dynamic navigation in large-scale environments; and (3) a single unified GUI Agent constructed via Model Merging, which synthesizes domain-specific models (grounding, web, and mobile) into one cohesive checkpoint. Extensive evaluations demonstrate that UI-Venus-1.5 establishes new state-of-the-art performance on benchmarks such as ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%), and AndroidWorld (77.6%), significantly outperforming previous strong baselines. In addition, UI-Venus-1.5 demonstrates robust navigation capabilities across a variety of Chinese mobile apps, effectively executing user instructions in real-world scenarios. Code: https://github.com/inclusionAI/UI-Venus; Model: https://huggingface.co/collections/inclusionAI/ui-venus
LRSCLIP: A Vision-Language Foundation Model for Aligning Remote Sensing Image with Longer Text
Mar 25, 2025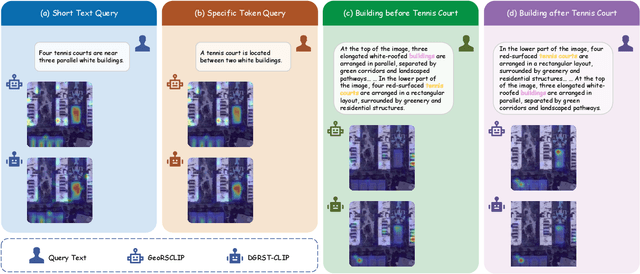
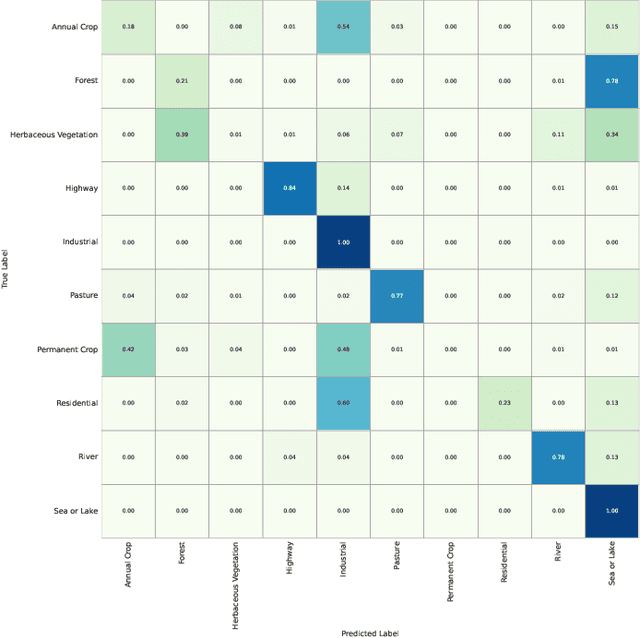
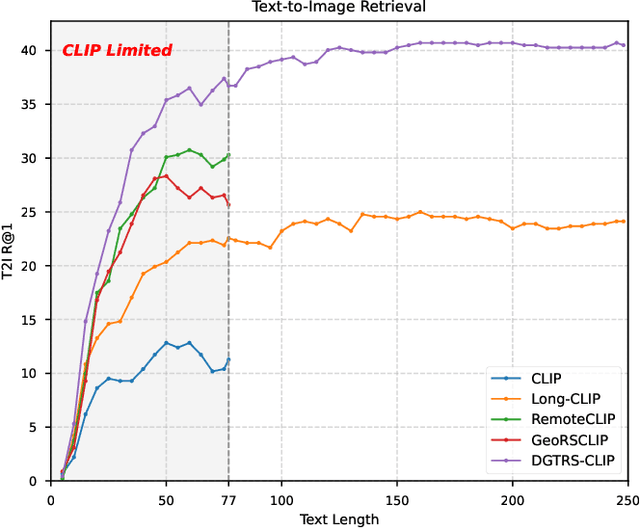
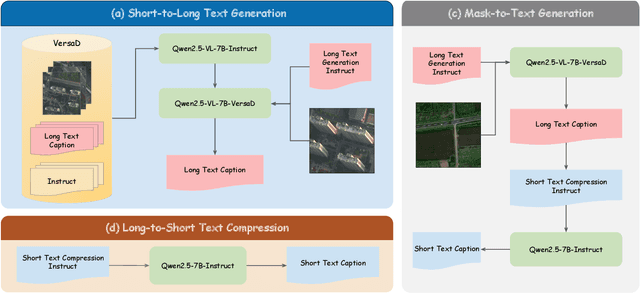
This study addresses the technical bottlenecks in handling long text and the "hallucination" issue caused by insufficient short text information in remote sensing vision-language foundation models (VLFM). We propose a novel vision-language foundation model, LRSCLIP, and a multimodal dataset, LRS2M. The main contributions are as follows: (1) By integrating multi-source remote sensing data and adopting a large language model labeling strategy, we construct the LRS2M dataset, which contains 2 million image-text pairs, providing both short and long texts for the first time, thus solving the problem of semantic granularity limitations in existing datasets; (2) The design of the LRSCLIP architecture based on Long-CLIP's KPS module, which extends CLIP's text processing capacity and achieves fine-grained cross-modal feature alignment through a dual-text loss weighting mechanism. Experimental results show that LRSCLIP improves retrieval accuracy by 10\%-20\% over the Long-CLIP baseline in the zero-shot long-text cross-modal retrieval task. For the zero-shot short-text cross-modal retrieval task, LRSCLIP achieves improvements over the current best model, GeoRSCLIP, with increases of 0.17\%, 0.67\%, and 0.92\% in Text to Image R@1, Image to Text R@1, and mR on RSITMD, respectively, and 0.04\%, 2.93\%, and 1.28\% on RSICD. In the zero-shot image classification task (average accuracy=75.75\%) and semantic localization task (Rmi=0.7653), LRSCLIP achieves state-of-the-art performance. These results validate the dual advantages of fine-grained semantic understanding and global feature matching in LRSCLIP. This work provides a new benchmark model and data support for remote sensing multimodal learning. The related code has been open source and is available at https://github.com/MitsuiChen14/LRSCLIP.
MP-GUI: Modality Perception with MLLMs for GUI Understanding
Mar 18, 2025Graphical user interface (GUI) has become integral to modern society, making it crucial to be understood for human-centric systems. However, unlike natural images or documents, GUIs comprise artificially designed graphical elements arranged to convey specific semantic meanings. Current multi-modal large language models (MLLMs) already proficient in processing graphical and textual components suffer from hurdles in GUI understanding due to the lack of explicit spatial structure modeling. Moreover, obtaining high-quality spatial structure data is challenging due to privacy issues and noisy environments. To address these challenges, we present MP-GUI, a specially designed MLLM for GUI understanding. MP-GUI features three precisely specialized perceivers to extract graphical, textual, and spatial modalities from the screen as GUI-tailored visual clues, with spatial structure refinement strategy and adaptively combined via a fusion gate to meet the specific preferences of different GUI understanding tasks. To cope with the scarcity of training data, we also introduce a pipeline for automatically data collecting. Extensive experiments demonstrate that MP-GUI achieves impressive results on various GUI understanding tasks with limited data.
Correlation-Aware Graph Convolutional Networks for Multi-Label Node Classification
Nov 26, 2024



Multi-label node classification is an important yet under-explored domain in graph mining as many real-world nodes belong to multiple categories rather than just a single one. Although a few efforts have been made by utilizing Graph Convolution Networks (GCNs) to learn node representations and model correlations between multiple labels in the embedding space, they still suffer from the ambiguous feature and ambiguous topology induced by multiple labels, which reduces the credibility of the messages delivered in graphs and overlooks the label correlations on graph data. Therefore, it is crucial to reduce the ambiguity and empower the GCNs for accurate classification. However, this is quite challenging due to the requirement of retaining the distinctiveness of each label while fully harnessing the correlation between labels simultaneously. To address these issues, in this paper, we propose a Correlation-aware Graph Convolutional Network (CorGCN) for multi-label node classification. By introducing a novel Correlation-Aware Graph Decomposition module, CorGCN can learn a graph that contains rich label-correlated information for each label. It then employs a Correlation-Enhanced Graph Convolution to model the relationships between labels during message passing to further bolster the classification process. Extensive experiments on five datasets demonstrate the effectiveness of our proposed CorGCN.
A Marginal Distributionally Robust Kalman Filter for Centralized Fusion
Jul 06, 2024State estimation is a fundamental problem for multi-sensor information fusion, essential in applications such as target tracking, power systems, and control automation. Previous research mostly ignores the correlation between sensors and assumes independent or known distributions. However, in practice, these distributions are often correlated and difAcult to estimate. This paper proposes a novel moment constrained marginal distributionally robust Kalman Alter (MC-MDRKF) for centralized state estimation in multi-sensor systems. First, we introduce a marginal distributional uncertainty set using a moment-constrained approach, which can better capture the uncertainties of Gaussian noises compared to Kullback-Leibler (KL) divergence-based methods. Based on that, a minimax optimization problem is formulated to identify the least favorable joint distribution and the optimal MMSE estimator thereunder. It is proved that this problem can be reformulated as a convex optimization problem, allowing for efficient solution Anding. Subsequently, by accounting for marginal distributional uncertainty within the state space model, the proposed MC-MDRKF is devised in a minimax approach. Simulation result demonstrates the robustness and superiority of the proposed method in a multi-sensor target tracking scenario.