 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLD-Road:A global-local decoding road network extraction model for remote sensing images
Jun 11, 2025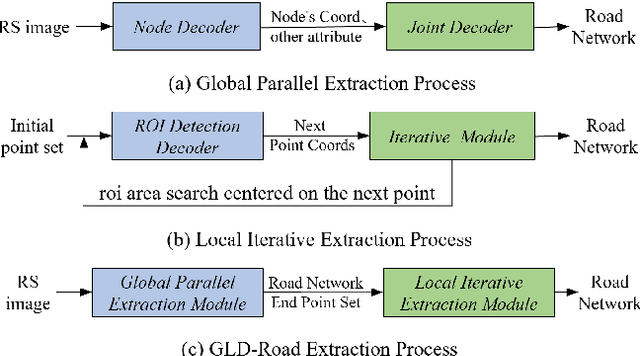
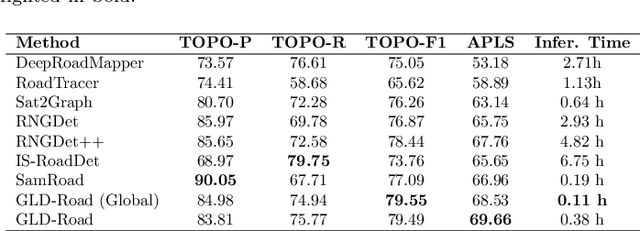

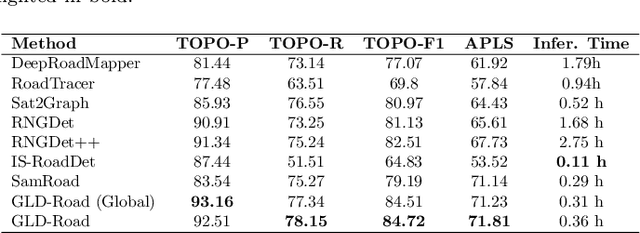
Road networks are crucial for mapping, autonomous driving, and disaster response. While manual annotation is costly, deep learning offers efficient extraction. Current methods include postprocessing (prone to errors), global parallel (fast but misses nodes), and local iterative (accurate but slow). We propose GLD-Road, a two-stage model combining global efficiency and local precision. First, it detects road nodes and connects them via a Connect Module. Then, it iteratively refines broken roads using local searches, drastically reducing computation. Experiments show GLD-Road outperforms state-of-the-art methods, improving APLS by 1.9% (City-Scale) and 0.67% (SpaceNet3). It also reduces retrieval time by 40% vs. Sat2Graph (global) and 92% vs. RNGDet++ (local). The experimental results are available at https://github.com/ucas-dlg/GLD-Road.
LRSCLIP: A Vision-Language Foundation Model for Aligning Remote Sensing Image with Longer Text
Mar 25, 2025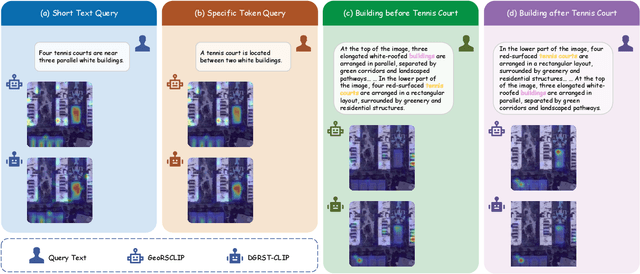
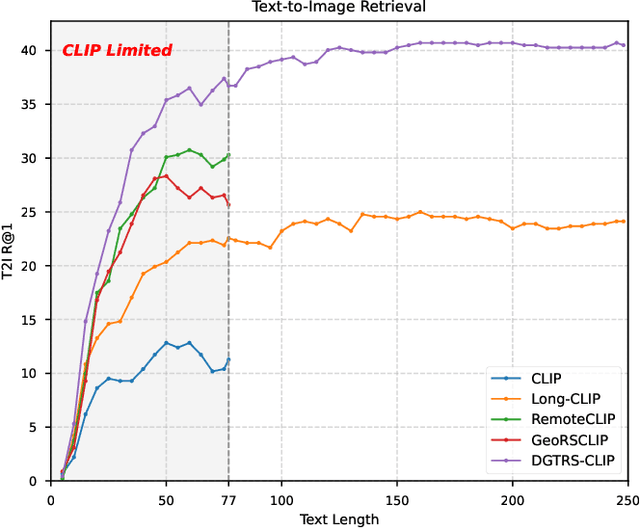
This study addresses the technical bottlenecks in handling long text and the "hallucination" issue caused by insufficient short text information in remote sensing vision-language foundation models (VLFM). We propose a novel vision-language foundation model, LRSCLIP, and a multimodal dataset, LRS2M. The main contributions are as follows: (1) By integrating multi-source remote sensing data and adopting a large language model labeling strategy, we construct the LRS2M dataset, which contains 2 million image-text pairs, providing both short and long texts for the first time, thus solving the problem of semantic granularity limitations in existing datasets; (2) The design of the LRSCLIP architecture based on Long-CLIP's KPS module, which extends CLIP's text processing capacity and achieves fine-grained cross-modal feature alignment through a dual-text loss weighting mechanism. Experimental results show that LRSCLIP improves retrieval accuracy by 10\%-20\% over the Long-CLIP baseline in the zero-shot long-text cross-modal retrieval task. For the zero-shot short-text cross-modal retrieval task, LRSCLIP achieves improvements over the current best model, GeoRSCLIP, with increases of 0.17\%, 0.67\%, and 0.92\% in Text to Image R@1, Image to Text R@1, and mR on RSITMD, respectively, and 0.04\%, 2.93\%, and 1.28\% on RSICD. In the zero-shot image classification task (average accuracy=75.75\%) and semantic localization task (Rmi=0.7653), LRSCLIP achieves state-of-the-art performance. These results validate the dual advantages of fine-grained semantic understanding and global feature matching in LRSCLIP. This work provides a new benchmark model and data support for remote sensing multimodal learning. The related code has been open source and is available at https://github.com/MitsuiChen14/LRSCLIP.
Probabilistic Formulations for System Identification of Linear Dynamics with Bilinear Observation Models
Feb 21, 2025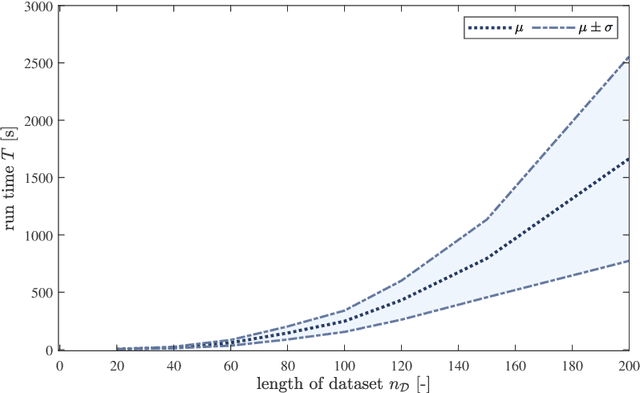
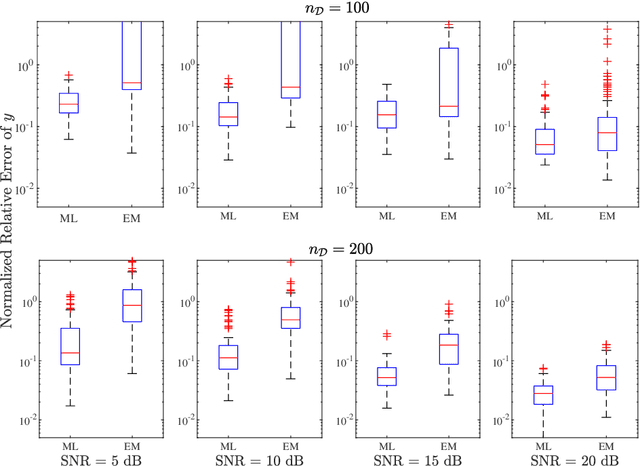
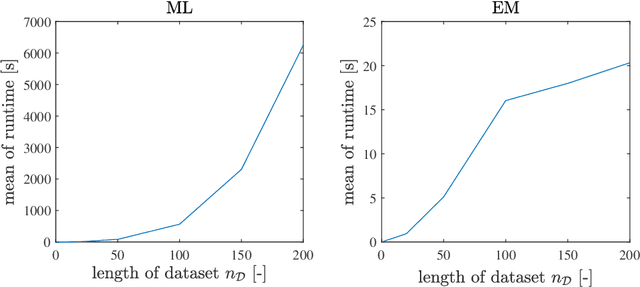
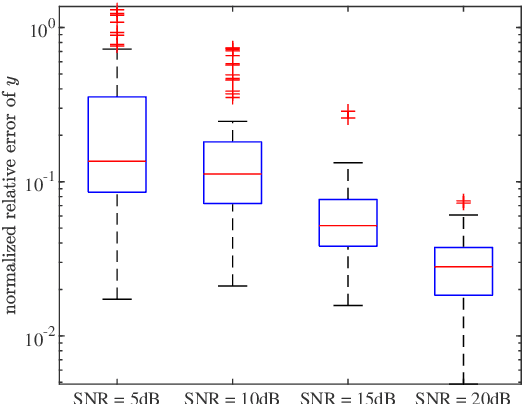
In this paper, we address the identification problem for the systems characterized by linear time-invariant dynamics with bilinear observation models. More precisely, we consider a suitable parametric description of the system and formulate the identification problem as the estimation of the parameters defining the mathematical model of the system using the observed input-output data. To this end, we propose two probabilistic frameworks. The first framework employs the Maximum Likelihood (ML) approach, which accurately finds the optimal parameter estimates by maximizing a likelihood function. Subsequently, we develop a tractable first-order method to solve the optimization problem corresponding to the proposed ML approach. Additionally, to further improve tractability and computational efficiency of the estimation of the parameters, we introduce an alternative framework based on the Expectation--Maximization (EM) approach, which estimates the parameters using an appropriately designed cost function. We show that the EM cost function is invex, which ensures the existence and uniqueness of the optimal solution. Furthermore, we derive the closed-form solution for the optimal parameters and also prove the recursive feasibility of the EM procedure. Through extensive numerical experiments, the practical implementation of the proposed approaches is demonstrated, and their estimation efficacy is verified and compared, highlighting the effectiveness of the methods to accurately estimate the system parameters and their potential for real-world applications in scenarios involving bilinear observation structures.
Extracting polygonal footprints in off-nadir images with Segment Anything Model
Aug 16, 2024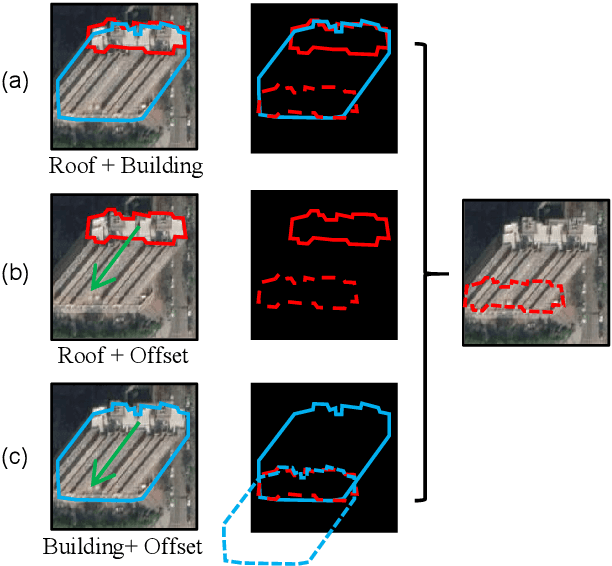
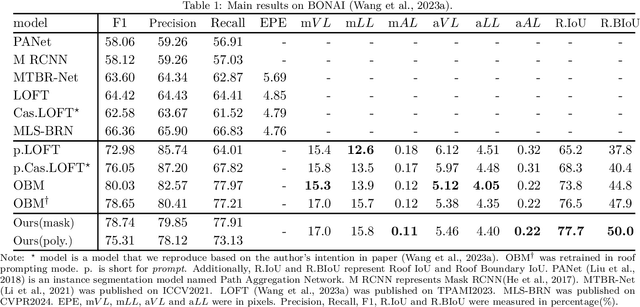
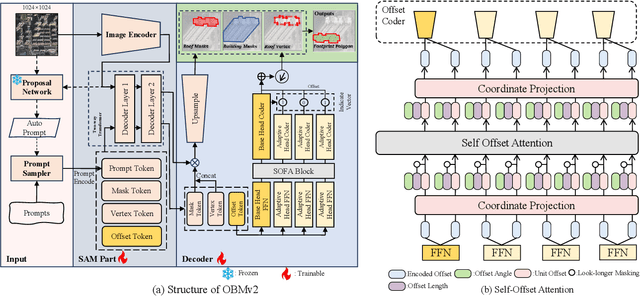
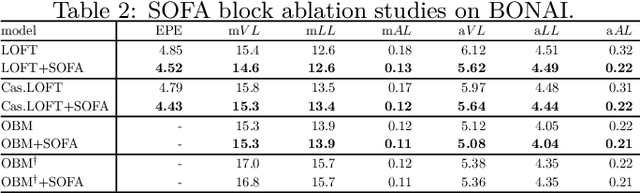
Building Footprint Extraction (BFE) in off-nadir aerial images often relies on roof segmentation and roof-to-footprint offset prediction, then drugging roof-to-footprint via the offset. However, the results from this multi-stage inference are not applicable in data production, because of the low quality of masks given by prediction. To solve this problem, we proposed OBMv2 in this paper, which supports both end-to-end and promptable polygonal footprint prediction. Different from OBM, OBMv2 using a newly proposed Self Offset Attention (SOFA) to bridge the performance gap on bungalow and skyscraper, which realized a real end-to-end footprint polygon prediction without postprocessing. %, such as Non-Maximum Suppression (NMS) and Distance NMS (DNMS). % To fully use information contained in roof masks, building masks and offsets, we proposed a Multi-level Information SyStem (MISS) for footprint prediction, with which OBMv2 can predict footprints even with insufficient predictions. Additionally, to squeeze information from the same model, we were inspired by Retrieval-Augmented Generation (RAG) in Nature Language Processing and proposed "RAG in BFE" problem. To verify the effectiveness of the proposed method, experiments were conducted on open datasets BONAI and OmniCity-view3. A generalization test was also conducted on Huizhou test set. The code will be available at \url{https://github.com/likaiucas/OBM}.
Rebuild City Buildings from Off-Nadir Aerial Images with Offset-Building Model
Nov 03, 2023



Accurate measurement of the offset from roof-to-footprint in very-high-resolution remote sensing imagery is crucial for urban information extraction tasks. With the help of deep learning, existing methods typically rely on two-stage CNN models to extract regions of interest on building feature maps. At the first stage, a Region Proposal Network (RPN) is applied to extract thousands of ROIs (Region of Interests) which will post-imported into a Region-based Convolutional Neural Networks (RCNN) to extract wanted information. However, because of inflexible RPN, these methods often lack effective user interaction, encounter difficulties in instance correspondence, and struggle to keep up with the advancements in general artificial intelligence. This paper introduces an interactive Transformer model combined with a prompt encoder to precisely extract building segmentation as well as the offset vectors from roofs to footprints. In our model, a powerful module, namely ROAM, was tailored for common problems in predicting roof-to-footprint offsets. We tested our model's feasibility on the publicly available BONAI dataset, achieving a significant reduction in Prompt-Instance-Level offset errors ranging from 14.6% to 16.3%. Additionally, we developed a Distance-NMS algorithm tailored for large-scale building offsets, significantly enhancing the accuracy of predicted building offset angles and lengths in a straightforward and efficient manner. To further validate the model's robustness, we created a new test set using 0.5m remote sensing imagery from Huizhou, China, for inference testing. Our code, training methods, and the updated dataset will be accessable at https://github.com/likaiucas.